 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Feb 16, 2026Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
Arctic-Embed 2.0: Multilingual Retrieval Without Compromise
Dec 03, 2024This paper presents the training methodology of Arctic-Embed 2.0, a set of open-source text embedding models built for accurate and efficient multilingual retrieval. While prior works have suffered from degraded English retrieval quality, Arctic-Embed 2.0 delivers competitive retrieval quality on multilingual and English-only benchmarks, and supports Matryoshka Representation Learning (MRL) for efficient embedding storage with significantly lower compressed quality degradation compared to alternatives. We detail the design and implementation, presenting several important open research questions that arose during model development. We conduct experiments exploring these research questions and include extensive discussion aimed at fostering further discussion in this field.
Embedding And Clustering Your Data Can Improve Contrastive Pretraining
Jul 26, 2024Recent studies of large-scale contrastive pretraining in the text embedding domain show that using single-source minibatches, rather than mixed-source minibatches, can substantially improve overall model accuracy. In this work, we explore extending training data stratification beyond source granularity by leveraging a pretrained text embedding model and the classic k-means clustering algorithm to further split training data apart by the semantic clusters within each source. Experimentally, we observe a notable increase in NDCG@10 when pretraining a BERT-based text embedding model on query-passage pairs from the MSMARCO passage retrieval dataset. Additionally, we conceptually connect our clustering approach to both the Topic Aware Sampling (TAS) aspect of the TAS-B methodology and the nearest-neighbor-based hard-negative mining aspect of the ANCE methodology and discuss how this unified view motivates future lines of research on the organization of contrastive pretraining data.
Arctic-Embed: Scalable, Efficient, and Accurate Text Embedding Models
May 08, 2024



This report describes the training dataset creation and recipe behind the family of \texttt{arctic-embed} text embedding models (a set of five models ranging from 22 to 334 million parameters with weights open-sourced under an Apache-2 license). At the time of their release, each model achieved state-of-the-art retrieval accuracy for models of their size on the MTEB Retrieval leaderboard, with the largest model, arctic-embed-l outperforming closed source embedding models such as Cohere's embed-v3 and Open AI's text-embed-3-large. In addition to the details of our training recipe, we have provided several informative ablation studies, which we believe are the cause of our model performance.
Randomized Ablation Feature Importance
Oct 02, 2019Given a model $f$ that predicts a target $y$ from a vector of input features $\pmb{x} = x_1, x_2, \ldots, x_M$, we seek to measure the importance of each feature with respect to the model's ability to make a good prediction. To this end, we consider how (on average) some measure of goodness or badness of prediction (which we term "loss" $\ell$), changes when we hide or ablate each feature from the model. To ablate a feature, we replace its value with another possible value randomly. By averaging over many points and many possible replacements, we measure the importance of a feature on the model's ability to make good predictions. Furthermore, we present statistical measures of uncertainty that quantify how confident we are that the feature importance we measure from our finite dataset and finite number of ablations is close to the theoretical true importance value.
The Explanation Game: Explaining Machine Learning Models with Cooperative Game Theory
Sep 17, 2019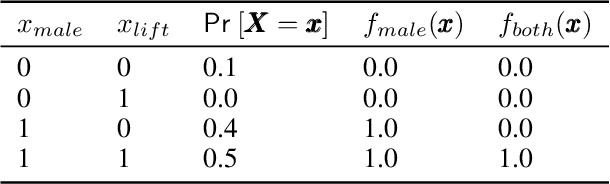
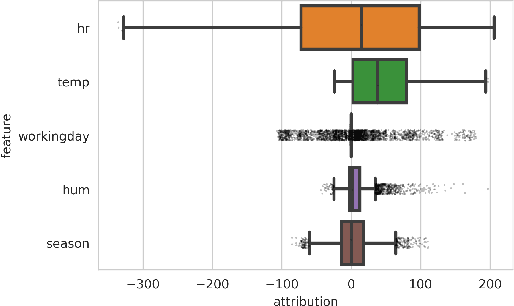

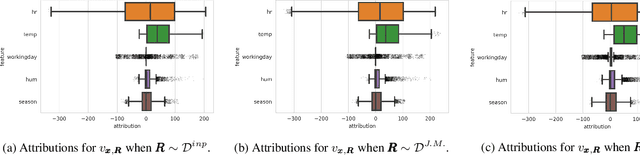
Recently, a number of techniques have been proposed to explain a machine learning (ML) model's prediction by attributing it to the corresponding input features. Popular among these are techniques that apply the Shapley value method from cooperative game theory. While existing papers focus on the axiomatic motivation of Shapley values, and efficient techniques for computing them, they do not justify the game formulations used. For instance, we find that the SHAP algorithm's formulation (Lundberg and Lee 2017) may give substantial attributions to features that play no role in a model. In this work, we study the game formulations underpinning several existing methods. Using a series of simple models, we illustrate how their subtle differences can yield large differences in attribution for the same prediction. We then present a general game formulation that unifies existing methods. After discussing the primitive of single-reference games, we decompose the Shapley values of the general game formulation into Shapley values of single-reference games. This is instructive in several ways. First, it enables confidence intervals on estimated attributions, which are not offered by previous works. Second, it enables different contrastive explanations of a prediction through comparison with different groups of reference inputs. We tie this idea to classic work on Norm Theory (Kahneman and Miller 1986) in cognitive psychology, and propose a general framework for generating explanations for ML models, called formulate, approximate, and explain (FAE). We apply this framework to explaining black-box models trained on two UCI datasets and a Lending Club dataset.