 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
Mar 27, 2026Spectral optimizers such as Muon have recently shown strong empirical performance in large-scale language model training, but the source and extent of their advantage remain poorly understood. We study this question through the linear associative memory problem, a tractable model for factual recall in transformer-based models. In particular, we go beyond orthogonal embeddings and consider Gaussian inputs and outputs, which allows the number of stored associations to greatly exceed the embedding dimension. Our main result sharply characterizes the recovery rates of one step of Muon and SGD on the logistic regression loss under a power law frequency distribution. We show that the storage capacity of Muon significantly exceeds that of SGD, and moreover Muon saturates at a larger critical batch size. We further analyze the multi-step dynamics under a thresholded gradient approximation and show that Muon achieves a substantially faster initial recovery rate than SGD, while both methods eventually converge to the information-theoretic limit at comparable speeds. Experiments on synthetic tasks validate the predicted scaling laws. Our analysis provides a quantitative understanding of the signal amplification of Muon and lays the groundwork for establishing scaling laws across more practical language modeling tasks and optimizers.
Learning to Recall with Transformers Beyond Orthogonal Embeddings
Mar 16, 2026Modern large language models (LLMs) excel at tasks that require storing and retrieving knowledge, such as factual recall and question answering. Transformers are central to this capability because they can encode information during training and retrieve it at inference. Existing theoretical analyses typically study transformers under idealized assumptions such as infinite data or orthogonal embeddings. In realistic settings, however, models are trained on finite datasets with non-orthogonal (random) embeddings. We address this gap by analyzing a single-layer transformer with random embeddings trained with (empirical) gradient descent on a simple token-retrieval task, where the model must identify an informative token within a length-$L$ sequence and learn a one-to-one mapping from tokens to labels. Our analysis tracks the ``early phase'' of gradient descent and yields explicit formulas for the model's storage capacity -- revealing a multiplicative dependence between sample size $N$, embedding dimension $d$, and sequence length $L$. We validate these scalings numerically and further complement them with a lower bound for the underlying statistical problem, demonstrating that this multiplicative scaling is intrinsic under non-orthogonal embeddings.
Full-Batch Gradient Descent Outperforms One-Pass SGD: Sample Complexity Separation in Single-Index Learning
Feb 02, 2026It is folklore that reusing training data more than once can improve the statistical efficiency of gradient-based learning. However, beyond linear regression, the theoretical advantage of full-batch gradient descent (GD, which always reuses all the data) over one-pass stochastic gradient descent (online SGD, which uses each data point only once) remains unclear. In this work, we consider learning a $d$-dimensional single-index model with a quadratic activation, for which it is known that one-pass SGD requires $n\gtrsim d\log d$ samples to achieve weak recovery. We first show that this $\log d$ factor in the sample complexity persists for full-batch spherical GD on the correlation loss; however, by simply truncating the activation, full-batch GD exhibits a favorable optimization landscape at $n \simeq d$ samples, thereby outperforming one-pass SGD (with the same activation) in statistical efficiency. We complement this result with a trajectory analysis of full-batch GD on the squared loss from small initialization, showing that $n \gtrsim d$ samples and $T \gtrsim\log d$ gradient steps suffice to achieve strong (exact) recovery.
Understanding the Mechanisms of Fast Hyperparameter Transfer
Dec 28, 2025The growing scale of deep learning models has rendered standard hyperparameter (HP) optimization prohibitively expensive. A promising solution is the use of scale-aware hyperparameters, which can enable direct transfer of optimal HPs from small-scale grid searches to large models with minimal performance loss. To understand the principles governing such transfer strategy, we develop a general conceptual framework for reasoning about HP transfer across scale, characterizing transfer as fast when the suboptimality it induces vanishes asymptotically faster than the finite-scale performance gap. We show formally that fast transfer is equivalent to useful transfer for compute-optimal grid search, meaning that transfer is asymptotically more compute-efficient than direct tuning. While empirical work has found that the Maximal Update Parameterization ($μ$P) exhibits fast transfer when scaling model width, the mechanisms remain poorly understood. We show that this property depends critically on problem structure by presenting synthetic settings where transfer either offers provable computational advantage or fails to outperform direct tuning even under $μ$P. To explain the fast transfer observed in practice, we conjecture that decomposing the optimization trajectory reveals two contributions to loss reduction: (1) a width-stable component that determines the optimal HPs, and (2) a width-sensitive component that improves with width but weakly perturbs the HP optimum. We present empirical evidence for this hypothesis across various settings, including large language model pretraining.
From Shortcut to Induction Head: How Data Diversity Shapes Algorithm Selection in Transformers
Dec 21, 2025



Transformers can implement both generalizable algorithms (e.g., induction heads) and simple positional shortcuts (e.g., memorizing fixed output positions). In this work, we study how the choice of pretraining data distribution steers a shallow transformer toward one behavior or the other. Focusing on a minimal trigger-output prediction task -- copying the token immediately following a special trigger upon its second occurrence -- we present a rigorous analysis of gradient-based training of a single-layer transformer. In both the infinite and finite sample regimes, we prove a transition in the learned mechanism: if input sequences exhibit sufficient diversity, measured by a low ``max-sum'' ratio of trigger-to-trigger distances, the trained model implements an induction head and generalizes to unseen contexts; by contrast, when this ratio is large, the model resorts to a positional shortcut and fails to generalize out-of-distribution (OOD). We also reveal a trade-off between the pretraining context length and OOD generalization, and derive the optimal pretraining distribution that minimizes computational cost per sample. Finally, we validate our theoretical predictions with controlled synthetic experiments, demonstrating that broadening context distributions robustly induces induction heads and enables OOD generalization. Our results shed light on the algorithmic biases of pretrained transformers and offer conceptual guidelines for data-driven control of their learned behaviors.
Learning Compositional Functions with Transformers from Easy-to-Hard Data
May 29, 2025Transformer-based language models have demonstrated impressive capabilities across a range of complex reasoning tasks. Prior theoretical work exploring the expressive power of transformers has shown that they can efficiently perform multi-step reasoning tasks involving parallelizable computations. However, the learnability of such constructions, particularly the conditions on the data distribution that enable efficient learning via gradient-based optimization, remains an open question. Towards answering this question, in this work we study the learnability of the $k$-fold composition task, which requires computing an interleaved composition of $k$ input permutations and $k$ hidden permutations, and can be expressed by a transformer with $O(\log k)$ layers. On the negative front, we prove a Statistical Query (SQ) lower bound showing that any SQ learner that makes only polynomially-many queries to an SQ oracle for the $k$-fold composition task distribution must have sample size exponential in $k$, thus establishing a statistical-computational gap. On the other hand, we show that this function class can be efficiently learned, with runtime and sample complexity polynomial in $k$, by gradient descent on an $O(\log k)$-depth transformer via two different curriculum learning strategies: one in which data consists of $k'$-fold composition functions with $k' \le k$ presented in increasing difficulty, and another in which all such data is presented simultaneously. Our work sheds light on the necessity and sufficiency of having both easy and hard examples in the data distribution for transformers to learn complex compositional tasks.
Emergence and scaling laws in SGD learning of shallow neural networks
Apr 28, 2025We study the complexity of online stochastic gradient descent (SGD) for learning a two-layer neural network with $P$ neurons on isotropic Gaussian data: $f_*(\boldsymbol{x}) = \sum_{p=1}^P a_p\cdot \sigma(\langle\boldsymbol{x},\boldsymbol{v}_p^*\rangle)$, $\boldsymbol{x} \sim \mathcal{N}(0,\boldsymbol{I}_d)$, where the activation $\sigma:\mathbb{R}\to\mathbb{R}$ is an even function with information exponent $k_*>2$ (defined as the lowest degree in the Hermite expansion), $\{\boldsymbol{v}^*_p\}_{p\in[P]}\subset \mathbb{R}^d$ are orthonormal signal directions, and the non-negative second-layer coefficients satisfy $\sum_{p} a_p^2=1$. We focus on the challenging ``extensive-width'' regime $P\gg 1$ and permit diverging condition number in the second-layer, covering as a special case the power-law scaling $a_p\asymp p^{-\beta}$ where $\beta\in\mathbb{R}_{\ge 0}$. We provide a precise analysis of SGD dynamics for the training of a student two-layer network to minimize the mean squared error (MSE) objective, and explicitly identify sharp transition times to recover each signal direction. In the power-law setting, we characterize scaling law exponents for the MSE loss with respect to the number of training samples and SGD steps, as well as the number of parameters in the student neural network. Our analysis entails that while the learning of individual teacher neurons exhibits abrupt transitions, the juxtaposition of $P\gg 1$ emergent learning curves at different timescales leads to a smooth scaling law in the cumulative objective.
Propagation of Chaos in One-hidden-layer Neural Networks beyond Logarithmic Time
Apr 17, 2025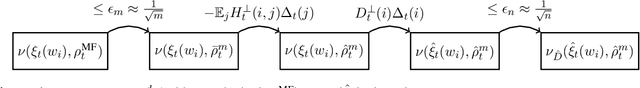

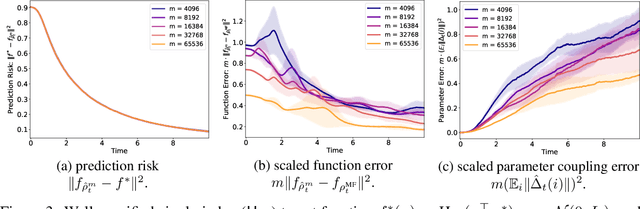
We study the approximation gap between the dynamics of a polynomial-width neural network and its infinite-width counterpart, both trained using projected gradient descent in the mean-field scaling regime. We demonstrate how to tightly bound this approximation gap through a differential equation governed by the mean-field dynamics. A key factor influencing the growth of this ODE is the local Hessian of each particle, defined as the derivative of the particle's velocity in the mean-field dynamics with respect to its position. We apply our results to the canonical feature learning problem of estimating a well-specified single-index model; we permit the information exponent to be arbitrarily large, leading to convergence times that grow polynomially in the ambient dimension $d$. We show that, due to a certain ``self-concordance'' property in these problems -- where the local Hessian of a particle is bounded by a constant times the particle's velocity -- polynomially many neurons are sufficient to closely approximate the mean-field dynamics throughout training.
When Do Transformers Outperform Feedforward and Recurrent Networks? A Statistical Perspective
Mar 14, 2025Theoretical efforts to prove advantages of Transformers in comparison with classical architectures such as feedforward and recurrent neural networks have mostly focused on representational power. In this work, we take an alternative perspective and prove that even with infinite compute, feedforward and recurrent networks may suffer from larger sample complexity compared to Transformers, as the latter can adapt to a form of dynamic sparsity. Specifically, we consider a sequence-to-sequence data generating model on sequences of length $N$, in which the output at each position depends only on $q$ relevant tokens with $q \ll N$, and the positions of these tokens are described in the input prompt. We prove that a single-layer Transformer can learn this model if and only if its number of attention heads is at least $q$, in which case it achieves a sample complexity almost independent of $N$, while recurrent networks require $N^{\Omega(1)}$ samples on the same problem. If we simplify this model, recurrent networks may achieve a complexity almost independent of $N$, while feedforward networks still require $N$ samples. Consequently, our proposed sparse retrieval model illustrates a natural hierarchy in sample complexity across these architectures.
Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search, RL and Distillation
Feb 02, 2025A key paradigm to improve the reasoning capabilities of large language models (LLMs) is to allocate more inference-time compute to search against a verifier or reward model. This process can then be utilized to refine the pretrained model or distill its reasoning patterns into more efficient models. In this paper, we study inference-time compute by viewing chain-of-thought (CoT) generation as a metastable Markov process: easy reasoning steps (e.g., algebraic manipulations) form densely connected clusters, while hard reasoning steps (e.g., applying a relevant theorem) create sparse, low-probability edges between clusters, leading to phase transitions at longer timescales. Under this framework, we prove that implementing a search protocol that rewards sparse edges improves CoT by decreasing the expected number of steps to reach different clusters. In contrast, we establish a limit on reasoning capability when the model is restricted to local information of the pretrained graph. We also show that the information gained by search can be utilized to obtain a better reasoning model: (1) the pretrained model can be directly finetuned to favor sparse edges via policy gradient methods, and moreover (2) a compressed metastable representation of the reasoning dynamics can be distilled into a smaller, more efficient model.