 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient displacement convex optimization with particle gradient descent
Feb 09, 2023Particle gradient descent, which uses particles to represent a probability measure and performs gradient descent on particles in parallel, is widely used to optimize functions of probability measures. This paper considers particle gradient descent with a finite number of particles and establishes its theoretical guarantees to optimize functions that are \emph{displacement convex} in measures. Concretely, for Lipschitz displacement convex functions defined on probability over $\mathbb{R}^d$, we prove that $O(1/\epsilon^2)$ particles and $O(d/\epsilon^4)$ computations are sufficient to find the $\epsilon$-optimal solutions. We further provide improved complexity bounds for optimizing smooth displacement convex functions. We demonstrate the application of our results for function approximation with specific neural architectures with two-dimensional inputs.
Refined Value-Based Offline RL under Realizability and Partial Coverage
Feb 05, 2023In offline reinforcement learning (RL) we have no opportunity to explore so we must make assumptions that the data is sufficient to guide picking a good policy, taking the form of assuming some coverage, realizability, Bellman completeness, and/or hard margin (gap). In this work we propose value-based algorithms for offline RL with PAC guarantees under just partial coverage, specifically, coverage of just a single comparator policy, and realizability of soft (entropy-regularized) Q-function of the single policy and a related function defined as a saddle point of certain minimax optimization problem. This offers refined and generally more lax conditions for offline RL. We further show an analogous result for vanilla Q-functions under a soft margin condition. To attain these guarantees, we leverage novel minimax learning algorithms to accurately estimate soft or vanilla Q-functions with $L^2$-convergence guarantees. Our algorithms' loss functions arise from casting the estimation problems as nonlinear convex optimization problems and Lagrangifying.
Looped Transformers as Programmable Computers
Jan 30, 2023



We present a framework for using transformer networks as universal computers by programming them with specific weights and placing them in a loop. Our input sequence acts as a punchcard, consisting of instructions and memory for data read/writes. We demonstrate that a constant number of encoder layers can emulate basic computing blocks, including embedding edit operations, non-linear functions, function calls, program counters, and conditional branches. Using these building blocks, we emulate a small instruction-set computer. This allows us to map iterative algorithms to programs that can be executed by a looped, 13-layer transformer. We show how this transformer, instructed by its input, can emulate a basic calculator, a basic linear algebra library, and in-context learning algorithms that employ backpropagation. Our work highlights the versatility of the attention mechanism, and demonstrates that even shallow transformers can execute full-fledged, general-purpose programs.
Understanding Incremental Learning of Gradient Descent: A Fine-grained Analysis of Matrix Sensing
Jan 27, 2023

It is believed that Gradient Descent (GD) induces an implicit bias towards good generalization in training machine learning models. This paper provides a fine-grained analysis of the dynamics of GD for the matrix sensing problem, whose goal is to recover a low-rank ground-truth matrix from near-isotropic linear measurements. It is shown that GD with small initialization behaves similarly to the greedy low-rank learning heuristics (Li et al., 2020) and follows an incremental learning procedure (Gissin et al., 2019): GD sequentially learns solutions with increasing ranks until it recovers the ground truth matrix. Compared to existing works which only analyze the first learning phase for rank-1 solutions, our result provides characterizations for the whole learning process. Moreover, besides the over-parameterized regime that many prior works focused on, our analysis of the incremental learning procedure also applies to the under-parameterized regime. Finally, we conduct numerical experiments to confirm our theoretical findings.
From Gradient Flow on Population Loss to Learning with Stochastic Gradient Descent
Oct 13, 2022Stochastic Gradient Descent (SGD) has been the method of choice for learning large-scale non-convex models. While a general analysis of when SGD works has been elusive, there has been a lot of recent progress in understanding the convergence of Gradient Flow (GF) on the population loss, partly due to the simplicity that a continuous-time analysis buys us. An overarching theme of our paper is providing general conditions under which SGD converges, assuming that GF on the population loss converges. Our main tool to establish this connection is a general converse Lyapunov like theorem, which implies the existence of a Lyapunov potential under mild assumptions on the rates of convergence of GF. In fact, using these potentials, we show a one-to-one correspondence between rates of convergence of GF and geometrical properties of the underlying objective. When these potentials further satisfy certain self-bounding properties, we show that they can be used to provide a convergence guarantee for Gradient Descent (GD) and SGD (even when the paths of GF and GD/SGD are quite far apart). It turns out that these self-bounding assumptions are in a sense also necessary for GD/SGD to work. Using our framework, we provide a unified analysis for GD/SGD not only for classical settings like convex losses, or objectives that satisfy PL / KL properties, but also for more complex problems including Phase Retrieval and Matrix sq-root, and extending the results in the recent work of Chatterjee 2022.
Self-Stabilization: The Implicit Bias of Gradient Descent at the Edge of Stability
Sep 30, 2022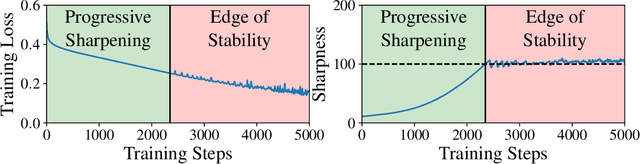
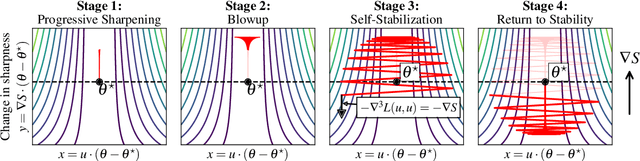
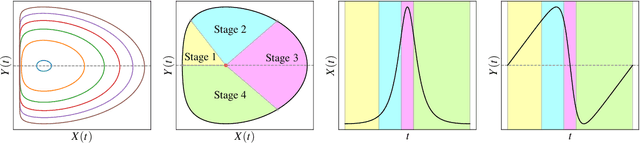
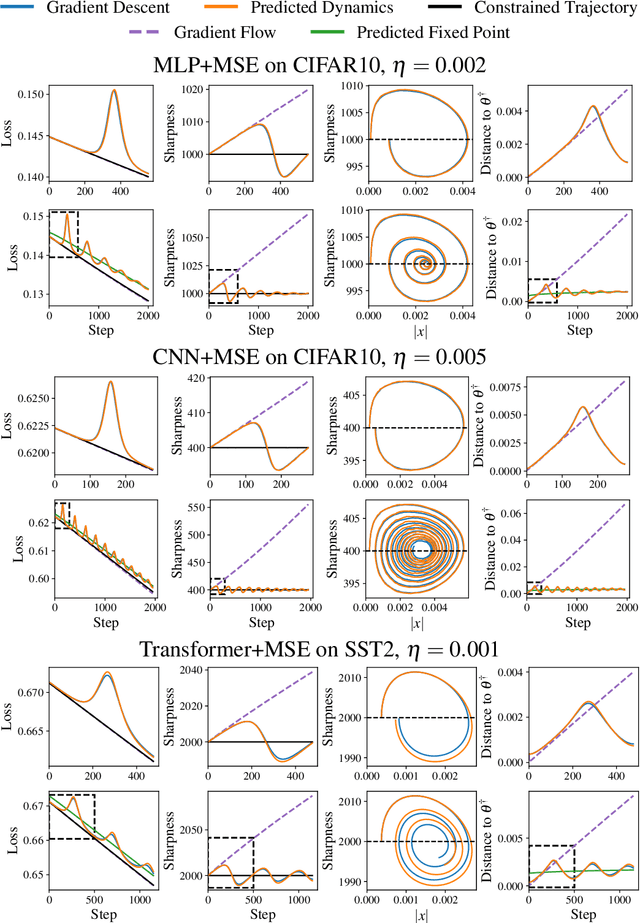
Traditional analyses of gradient descent show that when the largest eigenvalue of the Hessian, also known as the sharpness $S(\theta)$, is bounded by $2/\eta$, training is "stable" and the training loss decreases monotonically. Recent works, however, have observed that this assumption does not hold when training modern neural networks with full batch or large batch gradient descent. Most recently, Cohen et al. (2021) observed two important phenomena. The first, dubbed progressive sharpening, is that the sharpness steadily increases throughout training until it reaches the instability cutoff $2/\eta$. The second, dubbed edge of stability, is that the sharpness hovers at $2/\eta$ for the remainder of training while the loss continues decreasing, albeit non-monotonically. We demonstrate that, far from being chaotic, the dynamics of gradient descent at the edge of stability can be captured by a cubic Taylor expansion: as the iterates diverge in direction of the top eigenvector of the Hessian due to instability, the cubic term in the local Taylor expansion of the loss function causes the curvature to decrease until stability is restored. This property, which we call self-stabilization, is a general property of gradient descent and explains its behavior at the edge of stability. A key consequence of self-stabilization is that gradient descent at the edge of stability implicitly follows projected gradient descent (PGD) under the constraint $S(\theta) \le 2/\eta$. Our analysis provides precise predictions for the loss, sharpness, and deviation from the PGD trajectory throughout training, which we verify both empirically in a number of standard settings and theoretically under mild conditions. Our analysis uncovers the mechanism for gradient descent's implicit bias towards stability.
PAC Reinforcement Learning for Predictive State Representations
Jul 15, 2022
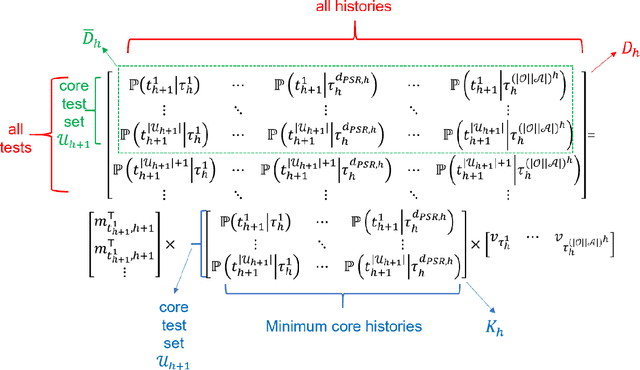


In this paper we study online Reinforcement Learning (RL) in partially observable dynamical systems. We focus on the Predictive State Representations (PSRs) model, which is an expressive model that captures other well-known models such as Partially Observable Markov Decision Processes (POMDP). PSR represents the states using a set of predictions of future observations and is defined entirely using observable quantities. We develop a novel model-based algorithm for PSRs that can learn a near optimal policy in sample complexity scaling polynomially with respect to all the relevant parameters of the systems. Our algorithm naturally works with function approximation to extend to systems with potentially large state and observation spaces. We show that given a realizable model class, the sample complexity of learning the near optimal policy only scales polynomially with respect to the statistical complexity of the model class, without any explicit polynomial dependence on the size of the state and observation spaces. Notably, our work is the first work that shows polynomial sample complexities to compete with the globally optimal policy in PSRs. Finally, we demonstrate how our general theorem can be directly used to derive sample complexity bounds for special models including $m$-step weakly revealing and $m$-step decodable tabular POMDPs, POMDPs with low-rank latent transition, and POMDPs with linear emission and latent transition.
Neural Networks can Learn Representations with Gradient Descent
Jun 30, 2022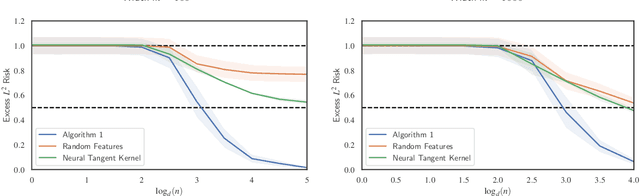
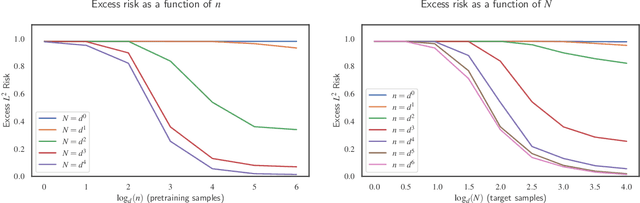
Significant theoretical work has established that in specific regimes, neural networks trained by gradient descent behave like kernel methods. However, in practice, it is known that neural networks strongly outperform their associated kernels. In this work, we explain this gap by demonstrating that there is a large class of functions which cannot be efficiently learned by kernel methods but can be easily learned with gradient descent on a two layer neural network outside the kernel regime by learning representations that are relevant to the target task. We also demonstrate that these representations allow for efficient transfer learning, which is impossible in the kernel regime. Specifically, we consider the problem of learning polynomials which depend on only a few relevant directions, i.e. of the form $f^\star(x) = g(Ux)$ where $U: \R^d \to \R^r$ with $d \gg r$. When the degree of $f^\star$ is $p$, it is known that $n \asymp d^p$ samples are necessary to learn $f^\star$ in the kernel regime. Our primary result is that gradient descent learns a representation of the data which depends only on the directions relevant to $f^\star$. This results in an improved sample complexity of $n\asymp d^2 r + dr^p$. Furthermore, in a transfer learning setup where the data distributions in the source and target domain share the same representation $U$ but have different polynomial heads we show that a popular heuristic for transfer learning has a target sample complexity independent of $d$.
Computationally Efficient PAC RL in POMDPs with Latent Determinism and Conditional Embeddings
Jun 24, 2022
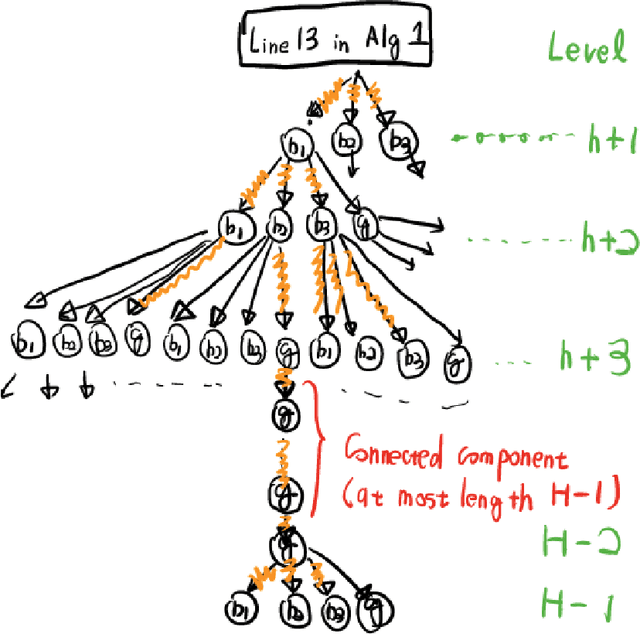
We study reinforcement learning with function approximation for large-scale Partially Observable Markov Decision Processes (POMDPs) where the state space and observation space are large or even continuous. Particularly, we consider Hilbert space embeddings of POMDP where the feature of latent states and the feature of observations admit a conditional Hilbert space embedding of the observation emission process, and the latent state transition is deterministic. Under the function approximation setup where the optimal latent state-action $Q$-function is linear in the state feature, and the optimal $Q$-function has a gap in actions, we provide a \emph{computationally and statistically efficient} algorithm for finding the \emph{exact optimal} policy. We show our algorithm's computational and statistical complexities scale polynomially with respect to the horizon and the intrinsic dimension of the feature on the observation space. Furthermore, we show both the deterministic latent transitions and gap assumptions are necessary to avoid statistical complexity exponential in horizon or dimension. Since our guarantee does not have an explicit dependence on the size of the state and observation spaces, our algorithm provably scales to large-scale POMDPs.
Provably Efficient Reinforcement Learning in Partially Observable Dynamical Systems
Jun 24, 2022
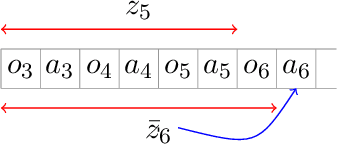
We study Reinforcement Learning for partially observable dynamical systems using function approximation. We propose a new \textit{Partially Observable Bilinear Actor-Critic framework}, that is general enough to include models such as observable tabular Partially Observable Markov Decision Processes (POMDPs), observable Linear-Quadratic-Gaussian (LQG), Predictive State Representations (PSRs), as well as a newly introduced model Hilbert Space Embeddings of POMDPs and observable POMDPs with latent low-rank transition. Under this framework, we propose an actor-critic style algorithm that is capable of performing agnostic policy learning. Given a policy class that consists of memory based policies (that look at a fixed-length window of recent observations), and a value function class that consists of functions taking both memory and future observations as inputs, our algorithm learns to compete against the best memory-based policy in the given policy class. For certain examples such as undercomplete observable tabular POMDPs, observable LQGs and observable POMDPs with latent low-rank transition, by implicitly leveraging their special properties, our algorithm is even capable of competing against the globally optimal policy without paying an exponential dependence on the horizon in its sample complexity.