 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Fine-Tuning Allows for Effective Meta-Learning
Paper and Code
May 05, 2021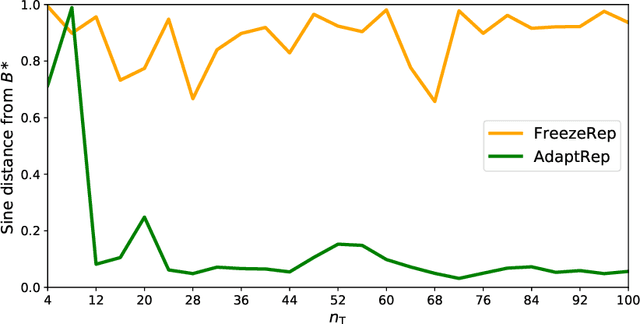
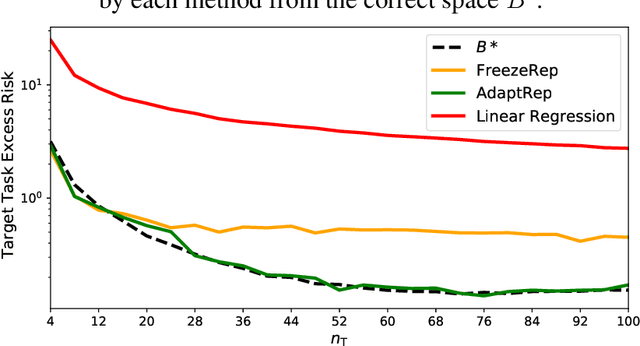
Representation learning has been widely studied in the context of meta-learning, enabling rapid learning of new tasks through shared representations. Recent works such as MAML have explored using fine-tuning-based metrics, which measure the ease by which fine-tuning can achieve good performance, as proxies for obtaining representations. We present a theoretical framework for analyzing representations derived from a MAML-like algorithm, assuming the available tasks use approximately the same underlying representation. We then provide risk bounds on the best predictor found by fine-tuning via gradient descent, demonstrating that the algorithm can provably leverage the shared structure. The upper bound applies to general function classes, which we demonstrate by instantiating the guarantees of our framework in the logistic regression and neural network settings. In contrast, we establish the existence of settings where any algorithm, using a representation trained with no consideration for task-specific fine-tuning, performs as well as a learner with no access to source tasks in the worst case. This separation result underscores the benefit of fine-tuning-based methods, such as MAML, over methods with "frozen representation" objectives in few-shot learning.