 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic Knowledge Distillation and Masked Acoustic Modeling for Full-band Speech Restoration with Improved Intelligibility
Sep 14, 2024



Speech restoration aims at restoring full-band speech with high quality and intelligibility, considering a diverse set of distortions. MaskSR is a recently proposed generative model for this task. As other models of its kind, MaskSR attains high quality but, as we show, intelligibility can be substantially improved. We do so by boosting the speech encoder component of MaskSR with predictions of semantic representations of the target speech, using a pre-trained self-supervised teacher model. Then, a masked language model is conditioned on the learned semantic features to predict acoustic tokens that encode low level spectral details of the target speech. We show that, with the same MaskSR model capacity and inference time, the proposed model, MaskSR2, significantly reduces the word error rate, a typical metric for intelligibility. MaskSR2 also achieves competitive word error rate among other models, while providing superior quality. An ablation study shows the effectiveness of various semantic representations.
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Jul 15, 2024Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Sequential Contrastive Audio-Visual Learning
Jul 08, 2024



Contrastive learning has emerged as a powerful technique in audio-visual representation learning, leveraging the natural co-occurrence of audio and visual modalities in extensive web-scale video datasets to achieve significant advancements. However, conventional contrastive audio-visual learning methodologies often rely on aggregated representations derived through temporal aggregation, which neglects the intrinsic sequential nature of the data. This oversight raises concerns regarding the ability of standard approaches to capture and utilize fine-grained information within sequences, information that is vital for distinguishing between semantically similar yet distinct examples. In response to this limitation, we propose sequential contrastive audio-visual learning (SCAV), which contrasts examples based on their non-aggregated representation space using sequential distances. Retrieval experiments with the VGGSound and Music datasets demonstrate the effectiveness of SCAV, showing 2-3x relative improvements against traditional aggregation-based contrastive learning and other methods from the literature. We also show that models trained with SCAV exhibit a high degree of flexibility regarding the metric employed for retrieval, allowing them to operate on a spectrum of efficiency-accuracy trade-offs, potentially making them applicable in multiple scenarios, from small- to large-scale retrieval.
GASS: Generalizing Audio Source Separation with Large-scale Data
Sep 29, 2023


Universal source separation targets at separating the audio sources of an arbitrary mix, removing the constraint to operate on a specific domain like speech or music. Yet, the potential of universal source separation is limited because most existing works focus on mixes with predominantly sound events, and small training datasets also limit its potential for supervised learning. Here, we study a single general audio source separation (GASS) model trained to separate speech, music, and sound events in a supervised fashion with a large-scale dataset. We assess GASS models on a diverse set of tasks. Our strong in-distribution results show the feasibility of GASS models, and the competitive out-of-distribution performance in sound event and speech separation shows its generalization abilities. Yet, it is challenging for GASS models to generalize for separating out-of-distribution cinematic and music content. We also fine-tune GASS models on each dataset and consistently outperform the ones without pre-training. All fine-tuned models (except the music separation one) obtain state-of-the-art results in their respective benchmarks.
V2A-Mapper: A Lightweight Solution for Vision-to-Audio Generation by Connecting Foundation Models
Aug 21, 2023Building artificial intelligence (AI) systems on top of a set of foundation models (FMs) is becoming a new paradigm in AI research. Their representative and generative abilities learnt from vast amounts of data can be easily adapted and transferred to a wide range of downstream tasks without extra training from scratch. However, leveraging FMs in cross-modal generation remains under-researched when audio modality is involved. On the other hand, automatically generating semantically-relevant sound from visual input is an important problem in cross-modal generation studies. To solve this vision-to-audio (V2A) generation problem, existing methods tend to design and build complex systems from scratch using modestly sized datasets. In this paper, we propose a lightweight solution to this problem by leveraging foundation models, specifically CLIP, CLAP, and AudioLDM. We first investigate the domain gap between the latent space of the visual CLIP and the auditory CLAP models. Then we propose a simple yet effective mapper mechanism (V2A-Mapper) to bridge the domain gap by translating the visual input between CLIP and CLAP spaces. Conditioned on the translated CLAP embedding, pretrained audio generative FM AudioLDM is adopted to produce high-fidelity and visually-aligned sound. Compared to previous approaches, our method only requires a quick training of the V2A-Mapper. We further analyze and conduct extensive experiments on the choice of the V2A-Mapper and show that a generative mapper is better at fidelity and variability (FD) while a regression mapper is slightly better at relevance (CS). Both objective and subjective evaluation on two V2A datasets demonstrate the superiority of our proposed method compared to current state-of-the-art approaches - trained with 86% fewer parameters but achieving 53% and 19% improvement in FD and CS, respectively.
Mono-to-stereo through parametric stereo generation
Jun 26, 2023



Generating a stereophonic presentation from a monophonic audio signal is a challenging open task, especially if the goal is to obtain a realistic spatial imaging with a specific panning of sound elements. In this work, we propose to convert mono to stereo by means of predicting parametric stereo (PS) parameters using both nearest neighbor and deep network approaches. In combination with PS, we also propose to model the task with generative approaches, allowing to synthesize multiple and equally-plausible stereo renditions from the same mono signal. To achieve this, we consider both autoregressive and masked token modelling approaches. We provide evidence that the proposed PS-based models outperform a competitive classical decorrelation baseline and that, within a PS prediction framework, modern generative models outshine equivalent non-generative counterparts. Overall, our work positions both PS and generative modelling as strong and appealing methodologies for mono-to-stereo upmixing. A discussion of the limitations of these approaches is also provided.
CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
Jun 16, 2023



Recent work has studied text-to-audio synthesis using large amounts of paired text-audio data. However, audio recordings with high-quality text annotations can be difficult to acquire. In this work, we approach text-to-audio synthesis using unlabeled videos and pretrained language-vision models. We propose to learn the desired text-audio correspondence by leveraging the visual modality as a bridge. We train a conditional diffusion model to generate the audio track of a video, given a video frame encoded by a pretrained contrastive language-image pretraining (CLIP) model. At test time, we first explore performing a zero-shot modality transfer and condition the diffusion model with a CLIP-encoded text query. However, we observe a noticeable performance drop with respect to image queries. To close this gap, we further adopt a pretrained diffusion prior model to generate a CLIP image embedding given a CLIP text embedding. Our results show the effectiveness of the proposed method, and that the pretrained diffusion prior can reduce the modality transfer gap. While we focus on text-to-audio synthesis, the proposed model can also generate audio from image queries, and it shows competitive performance against a state-of-the-art image-to-audio synthesis model in a subjective listening test. This study offers a new direction of approaching text-to-audio synthesis that leverages the naturally-occurring audio-visual correspondence in videos and the power of pretrained language-vision models.
Full-band General Audio Synthesis with Score-based Diffusion
Oct 26, 2022Recent works have shown the capability of deep generative models to tackle general audio synthesis from a single label, producing a variety of impulsive, tonal, and environmental sounds. Such models operate on band-limited signals and, as a result of an autoregressive approach, they are typically conformed by pre-trained latent encoders and/or several cascaded modules. In this work, we propose a diffusion-based generative model for general audio synthesis, named DAG, which deals with full-band signals end-to-end in the waveform domain. Results show the superiority of DAG over existing label-conditioned generators in terms of both quality and diversity. More specifically, when compared to the state of the art, the band-limited and full-band versions of DAG achieve relative improvements that go up to 40 and 65%, respectively. We believe DAG is flexible enough to accommodate different conditioning schemas while providing good quality synthesis.
Universal Speech Enhancement with Score-based Diffusion
Jun 07, 2022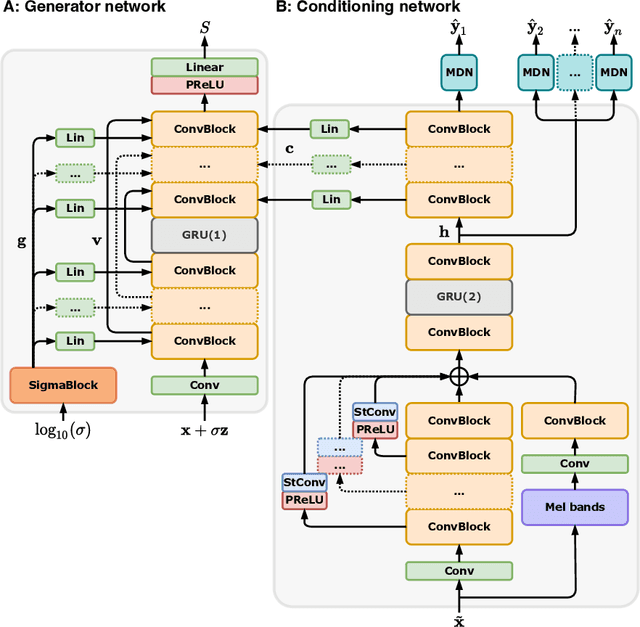
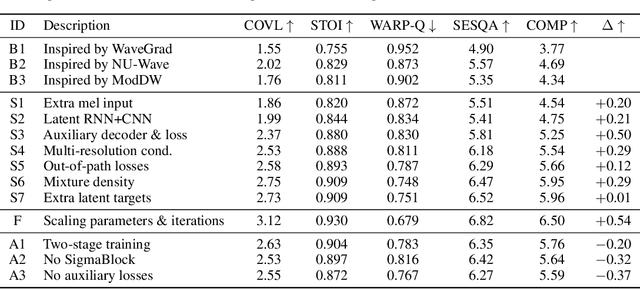
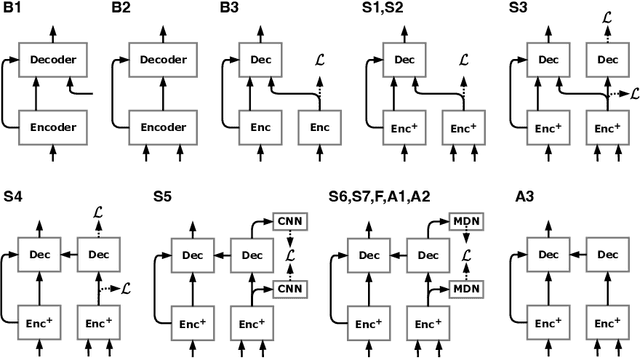
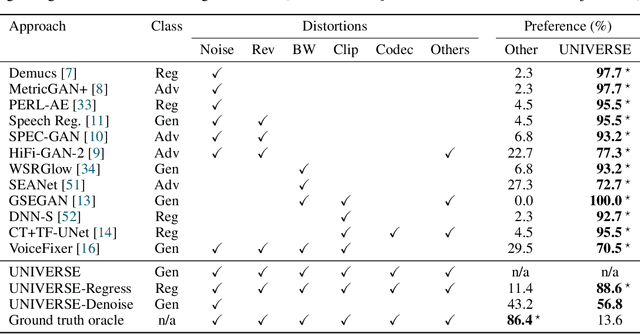
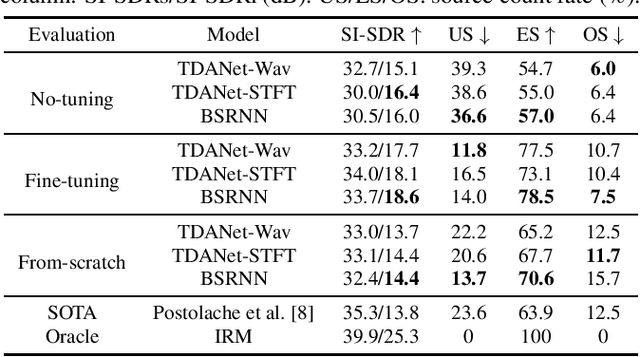
Removing background noise from speech audio has been the subject of considerable research and effort, especially in recent years due to the rise of virtual communication and amateur sound recording. Yet background noise is not the only unpleasant disturbance that can prevent intelligibility: reverb, clipping, codec artifacts, problematic equalization, limited bandwidth, or inconsistent loudness are equally disturbing and ubiquitous. In this work, we propose to consider the task of speech enhancement as a holistic endeavor, and present a universal speech enhancement system that tackles 55 different distortions at the same time. Our approach consists of a generative model that employs score-based diffusion, together with a multi-resolution conditioning network that performs enhancement with mixture density networks. We show that this approach significantly outperforms the state of the art in a subjective test performed by expert listeners. We also show that it achieves competitive objective scores with just 4-8 diffusion steps, despite not considering any particular strategy for fast sampling. We hope that both our methodology and technical contributions encourage researchers and practitioners to adopt a universal approach to speech enhancement, possibly framing it as a generative task.
On loss functions and evaluation metrics for music source separation
Feb 16, 2022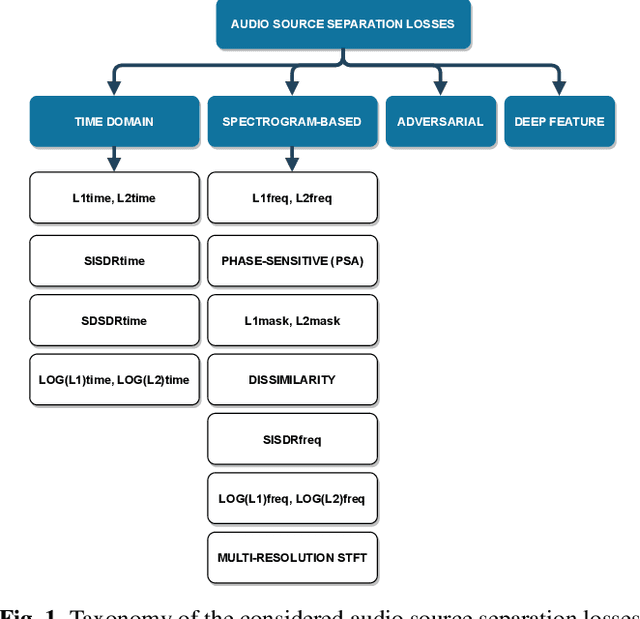
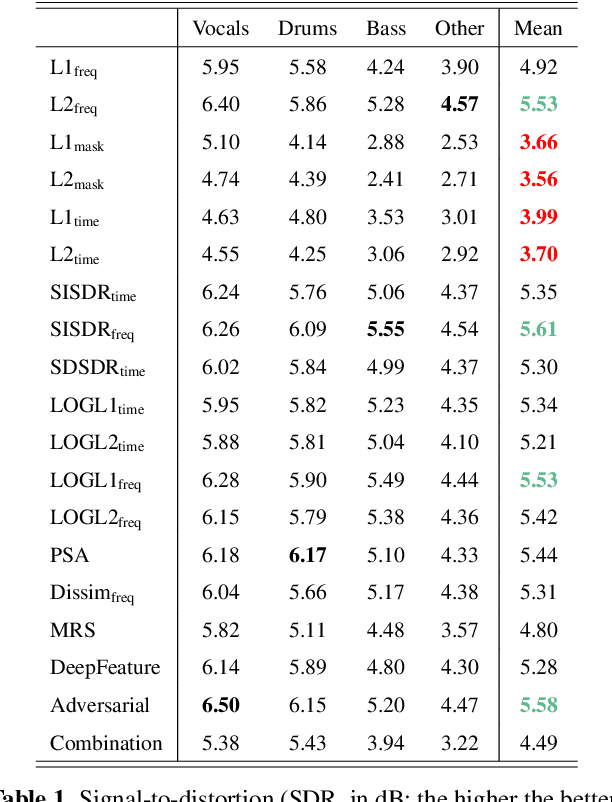
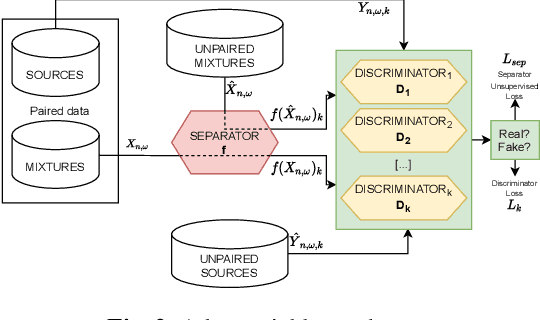
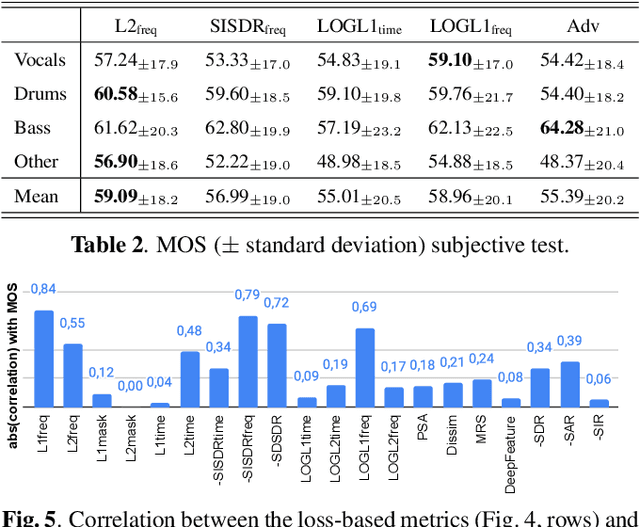
We investigate which loss functions provide better separations via benchmarking an extensive set of those for music source separation. To that end, we first survey the most representative audio source separation losses we identified, to later consistently benchmark them in a controlled experimental setup. We also explore using such losses as evaluation metrics, via cross-correlating them with the results of a subjective test. Based on the observation that the standard signal-to-distortion ratio metric can be misleading in some scenarios, we study alternative evaluation metrics based on the considered losses.