 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRashid: A Cipher-Based Framework for Exploring In-Context Language Learning
Mar 23, 2026Where there is growing interest in in-context language learning (ICLL) for unseen languages with large language models, such languages usually suffer from the lack of NLP tools, data resources, and researcher expertise. This means that progress is difficult to assess, the field does not allow for cheap large-scale experimentation, and findings on ICLL are often limited to very few languages and tasks. In light of such limitations, we introduce a framework (Rashid), for studying ICLL wherein we reversibly cipher high-resource languages (HRLs) to construct truly unseen languages with access to a wide range of resources available for HRLs, unlocking previously impossible exploration of ICLL phenomena. We use our framework to assess current methods in the field with SOTA evaluation tools and manual analysis, explore the utility of potentially expensive resources in improving ICLL, and test ICLL strategies on rich downstream tasks beyond machine translation. These lines of exploration showcase the possibilities enabled by our framework, as well as providing actionable insights regarding current performance and future directions in ICLL.
DialUp! Modeling the Language Continuum by Adapting Models to Dialects and Dialects to Models
Jan 27, 2025



Most of the world's languages and dialects are low-resource, and lack support in mainstream machine translation (MT) models. However, many of them have a closely-related high-resource language (HRL) neighbor, and differ in linguistically regular ways from it. This underscores the importance of model robustness to dialectical variation and cross-lingual generalization to the HRL dialect continuum. We present DialUp, consisting of a training-time technique for adapting a pretrained model to dialectical data (M->D), and an inference-time intervention adapting dialectical data to the model expertise (D->M). M->D induces model robustness to potentially unseen and unknown dialects by exposure to synthetic data exemplifying linguistic mechanisms of dialectical variation, whereas D->M treats dialectical divergence for known target dialects. These methods show considerable performance gains for several dialects from four language families, and modest gains for two other language families. We also conduct feature and error analyses, which show that language varieties with low baseline MT performance are more likely to benefit from these approaches.
Evaluating Large Language Models along Dimensions of Language Variation: A Systematik Invesdigatiom uv Cross-lingual Generalization
Jun 19, 2024



While large language models exhibit certain cross-lingual generalization capabilities, they suffer from performance degradation (PD) on unseen closely-related languages (CRLs) and dialects relative to their high-resource language neighbour (HRLN). However, we currently lack a fundamental understanding of what kinds of linguistic distances contribute to PD, and to what extent. Furthermore, studies of cross-lingual generalization are confounded by unknown quantities of CRL language traces in the training data, and by the frequent lack of availability of evaluation data in lower-resource related languages and dialects. To address these issues, we model phonological, morphological, and lexical distance as Bayesian noise processes to synthesize artificial languages that are controllably distant from the HRLN. We analyse PD as a function of underlying noise parameters, offering insights on model robustness to isolated and composed linguistic phenomena, and the impact of task and HRL characteristics on PD. We calculate parameter posteriors on real CRL-HRLN pair data and show that they follow computed trends of artificial languages, demonstrating the viability of our noisers. Our framework offers a cheap solution to estimating task performance on an unseen CRL given HRLN performance using its posteriors, as well as for diagnosing observed PD on a CRL in terms of its linguistic distances from its HRLN, and opens doors to principled methods of mitigating performance degradation.
Pointer-Generator Networks for Low-Resource Machine Translation: Don't Copy That!
Mar 25, 2024



While Transformer-based neural machine translation (NMT) is very effective in high-resource settings, many languages lack the necessary large parallel corpora to benefit from it. In the context of low-resource (LR) MT between two closely-related languages, a natural intuition is to seek benefits from structural "shortcuts", such as copying subwords from the source to the target, given that such language pairs often share a considerable number of identical words, cognates, and borrowings. We test Pointer-Generator Networks for this purpose for six language pairs over a variety of resource ranges, and find weak improvements for most settings. However, analysis shows that the model does not show greater improvements for closely-related vs. more distant language pairs, or for lower resource ranges, and that the models do not exhibit the expected usage of the mechanism for shared subwords. Our discussion of the reasons for this behaviour highlights several general challenges for LR NMT, such as modern tokenization strategies, noisy real-world conditions, and linguistic complexities. We call for better scrutiny of linguistically motivated improvements to NMT given the blackbox nature of Transformer models, as well as for a focus on the above problems in the field.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Induced Inflection-Set Keyword Search in Speech
Oct 27, 2019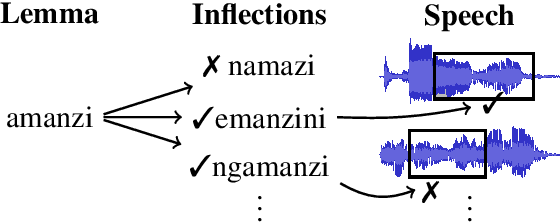
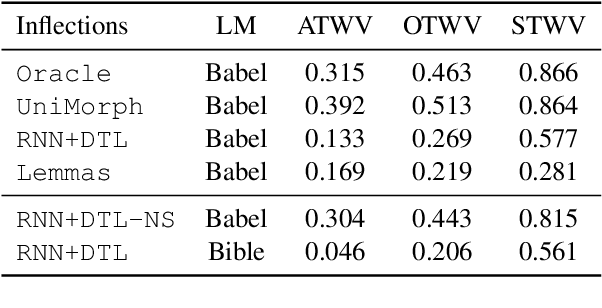
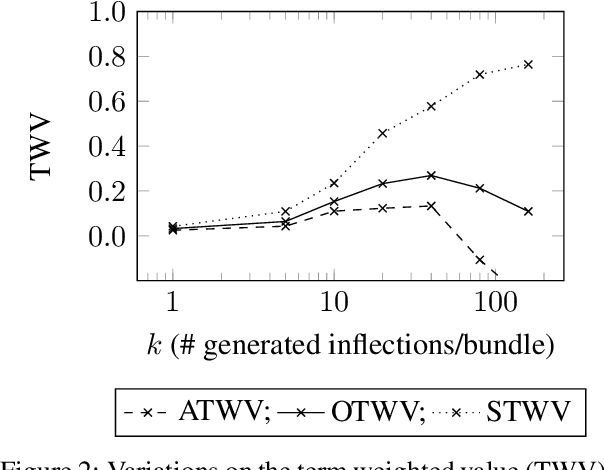
We investigate the problem of searching for a lexeme-set in speech by searching for its inflectional variants. Experimental results indicate how lexeme-set search performance changes with the number of hypothesized inflections, while ablation experiments highlight the relative importance of different components in the lexeme-set search pipeline. We provide a recipe and evaluation set for the community to use as an extrinsic measure of the performance of inflection generation approaches.
Modeling Color Terminology Across Thousands of Languages
Oct 03, 2019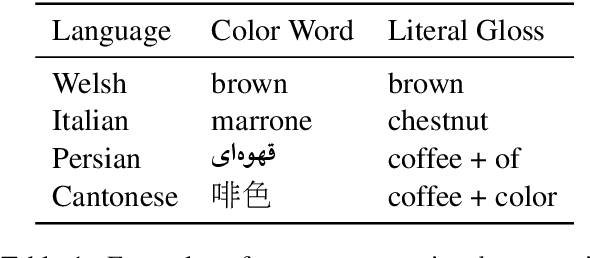
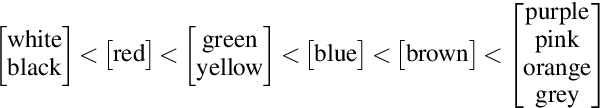
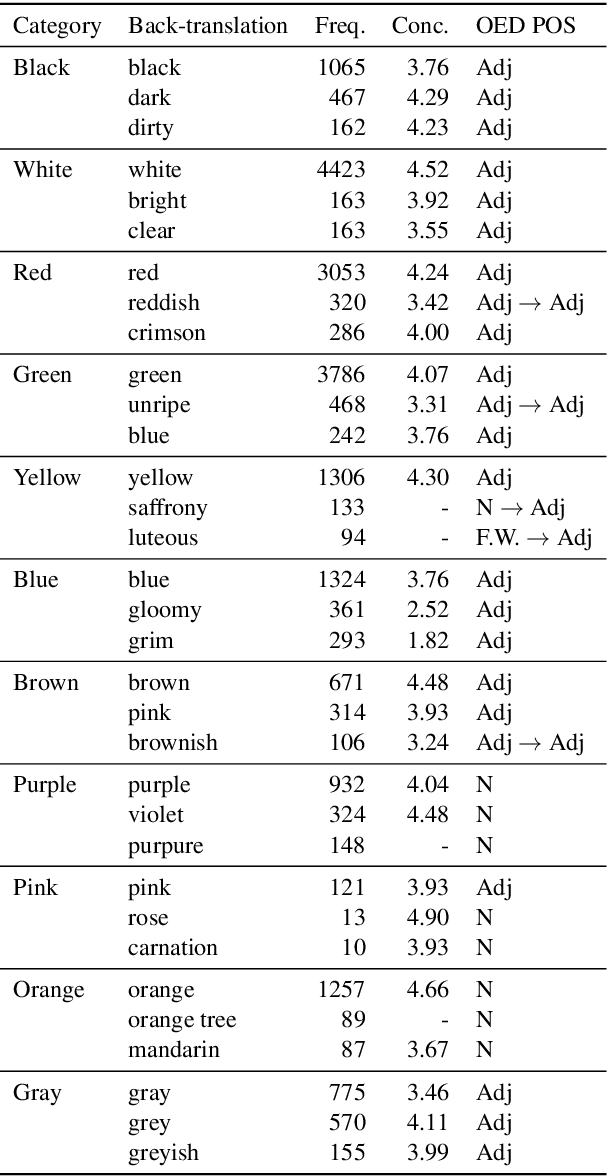
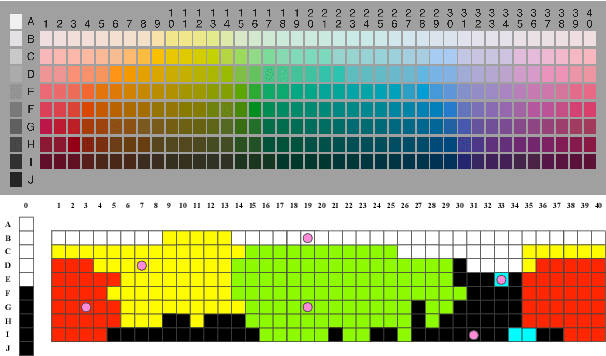
There is an extensive history of scholarship into what constitutes a "basic" color term, as well as a broadly attested acquisition sequence of basic color terms across many languages, as articulated in the seminal work of Berlin and Kay (1969). This paper employs a set of diverse measures on massively cross-linguistic data to operationalize and critique the Berlin and Kay color term hypotheses. Collectively, the 14 empirically-grounded computational linguistic metrics we design---as well as their aggregation---correlate strongly with both the Berlin and Kay basic/secondary color term partition (gamma=0.96) and their hypothesized universal acquisition sequence. The measures and result provide further empirical evidence from computational linguistics in support of their claims, as well as additional nuance: they suggest treating the partition as a spectrum instead of a dichotomy.
Massively Multilingual Adversarial Speech Recognition
Apr 03, 2019
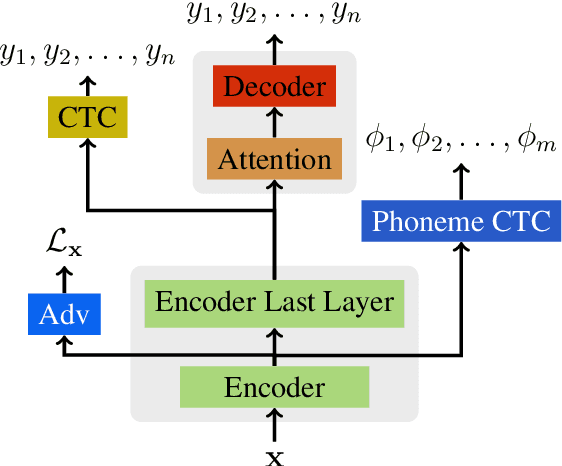
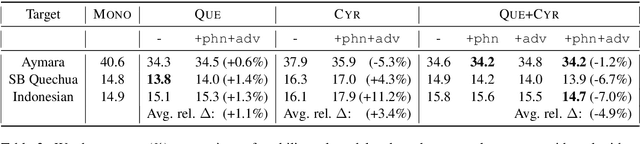

We report on adaptation of multilingual end-to-end speech recognition models trained on as many as 100 languages. Our findings shed light on the relative importance of similarity between the target and pretraining languages along the dimensions of phonetics, phonology, language family, geographical location, and orthography. In this context, experiments demonstrate the effectiveness of two additional pretraining objectives in encouraging language-independent encoder representations: a context-independent phoneme objective paired with a language-adversarial classification objective.
UniMorph 2.0: Universal Morphology
Oct 25, 2018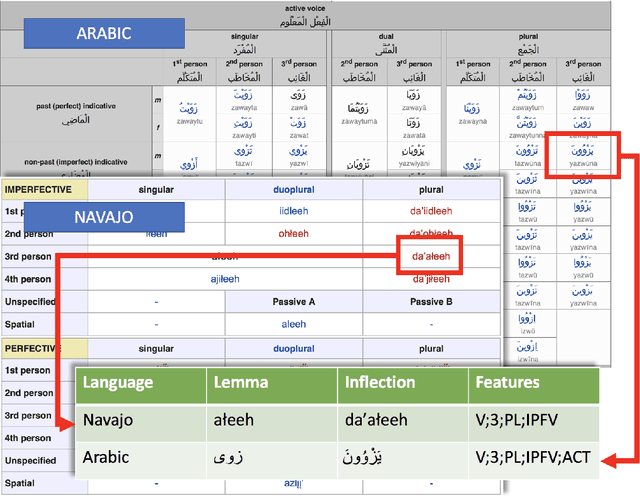
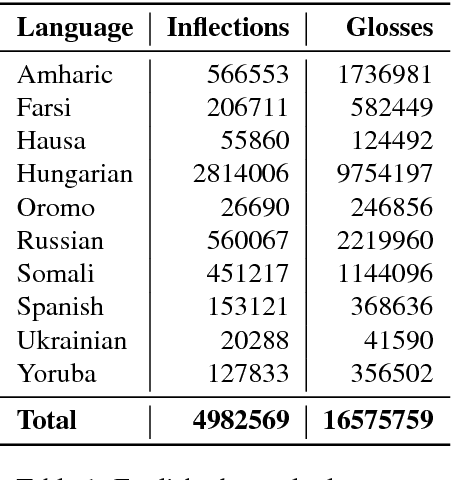

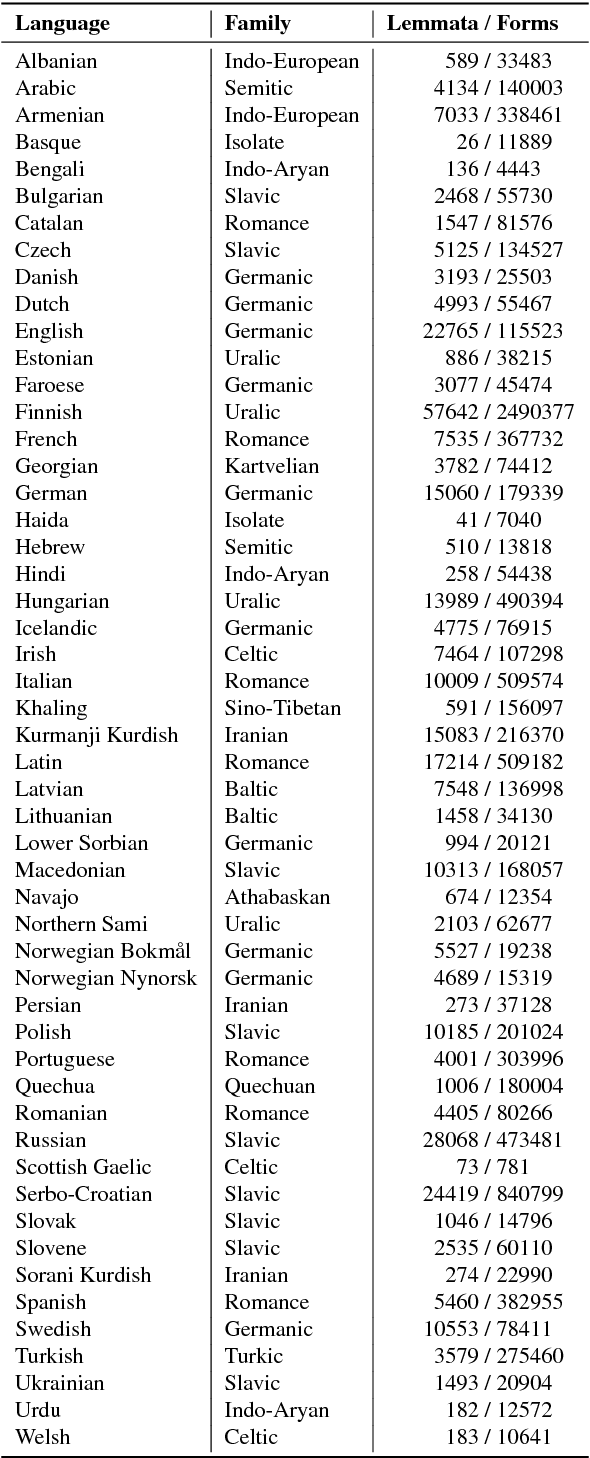
The Universal Morphology UniMorph project is a collaborative effort to improve how NLP handles complex morphology across the world's languages. The project releases annotated morphological data using a universal tagset, the UniMorph schema. Each inflected form is associated with a lemma, which typically carries its underlying lexical meaning, and a bundle of morphological features from our schema. Additional supporting data and tools are also released on a per-language basis when available. UniMorph is based at the Center for Language and Speech Processing (CLSP) at Johns Hopkins University in Baltimore, Maryland and is sponsored by the DARPA LORELEI program. This paper details advances made to the collection, annotation, and dissemination of project resources since the initial UniMorph release described at LREC 2016. lexical resources} }
The CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Oct 18, 2018
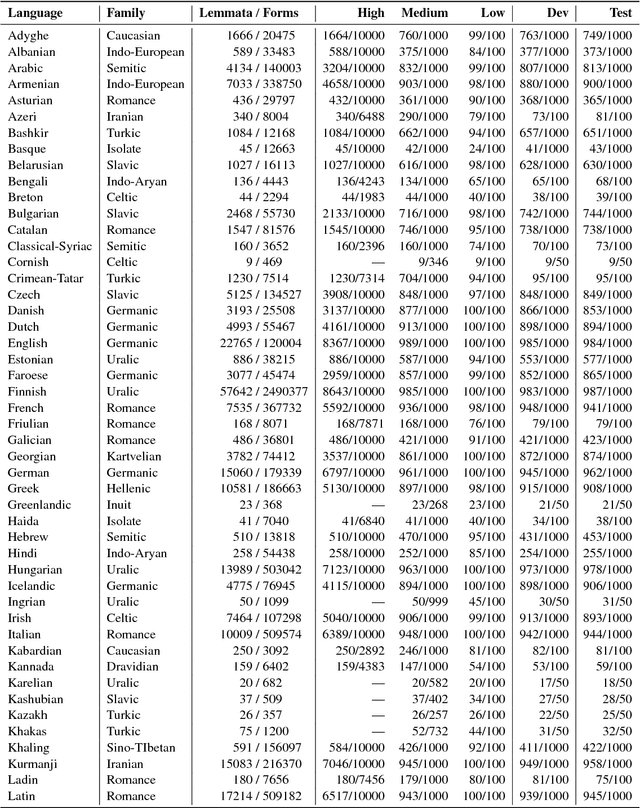
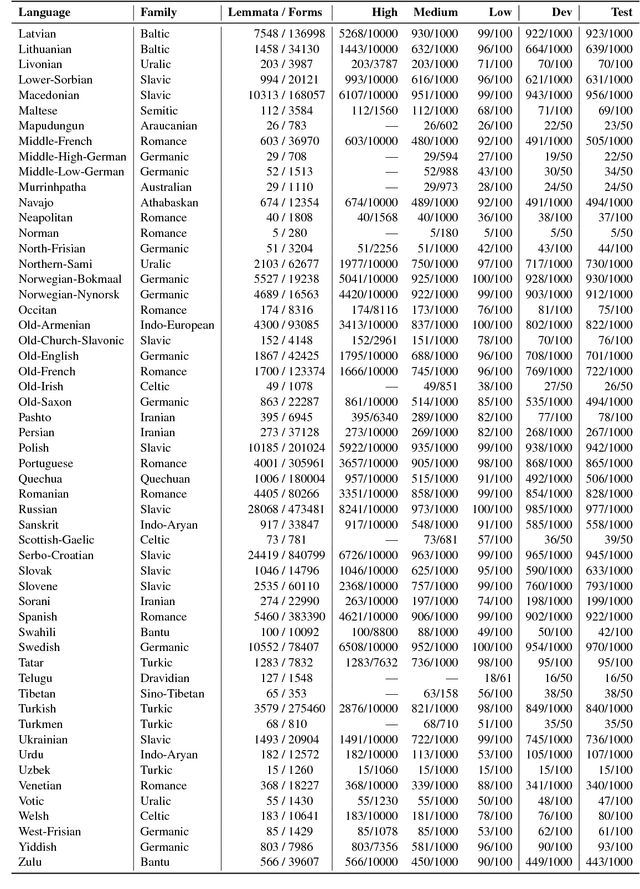

The CoNLL--SIGMORPHON 2018 shared task on supervised learning of morphological generation featured data sets from 103 typologically diverse languages. Apart from extending the number of languages involved in earlier supervised tasks of generating inflected forms, this year the shared task also featured a new second task which asked participants to inflect words in sentential context, similar to a cloze task. This second task featured seven languages. Task 1 received 27 submissions and task 2 received 6 submissions. Both tasks featured a low, medium, and high data condition. Nearly all submissions featured a neural component and built on highly-ranked systems from the earlier 2017 shared task. In the inflection task (task 1), 41 of the 52 languages present in last year's inflection task showed improvement by the best systems in the low-resource setting. The cloze task (task 2) proved to be difficult, and few submissions managed to consistently improve upon both a simple neural baseline system and a lemma-repeating baseline.