 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting joint decoding based multi-talker speech recognition with DNN acoustic model
Oct 31, 2021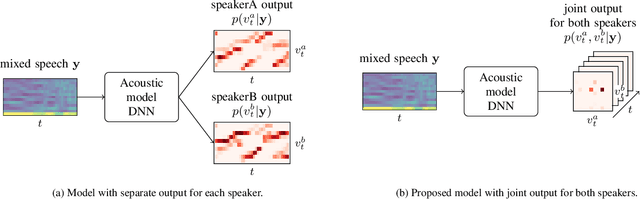
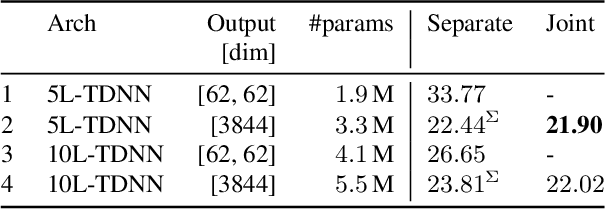
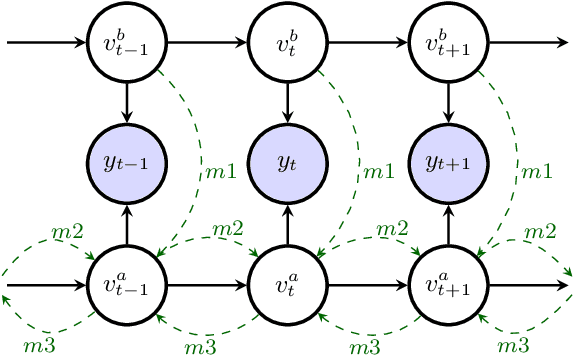
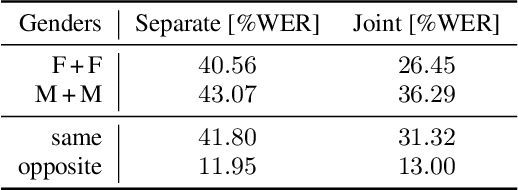
In typical multi-talker speech recognition systems, a neural network-based acoustic model predicts senone state posteriors for each speaker. These are later used by a single-talker decoder which is applied on each speaker-specific output stream separately. In this work, we argue that such a scheme is sub-optimal and propose a principled solution that decodes all speakers jointly. We modify the acoustic model to predict joint state posteriors for all speakers, enabling the network to express uncertainty about the attribution of parts of the speech signal to the speakers. We employ a joint decoder that can make use of this uncertainty together with higher-level language information. For this, we revisit decoding algorithms used in factorial generative models in early multi-talker speech recognition systems. In contrast with these early works, we replace the GMM acoustic model with DNN, which provides greater modeling power and simplifies part of the inference. We demonstrate the advantage of joint decoding in proof of concept experiments on a mixed-TIDIGITS dataset.
Unsupervised Word Segmentation from Discrete Speech Units in Low-Resource Settings
Jun 08, 2021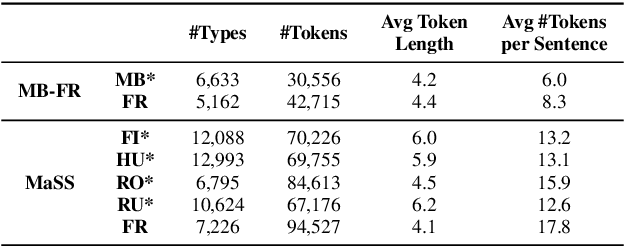
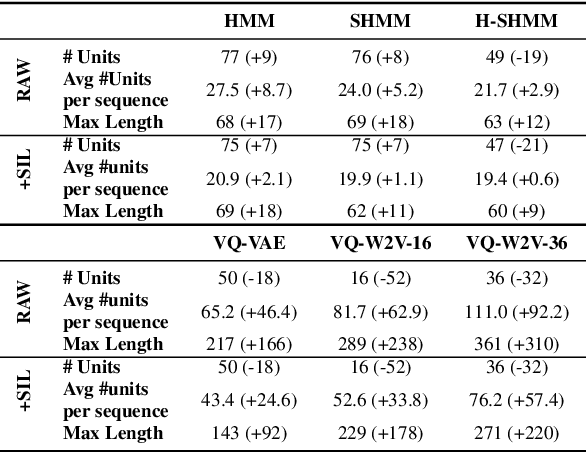
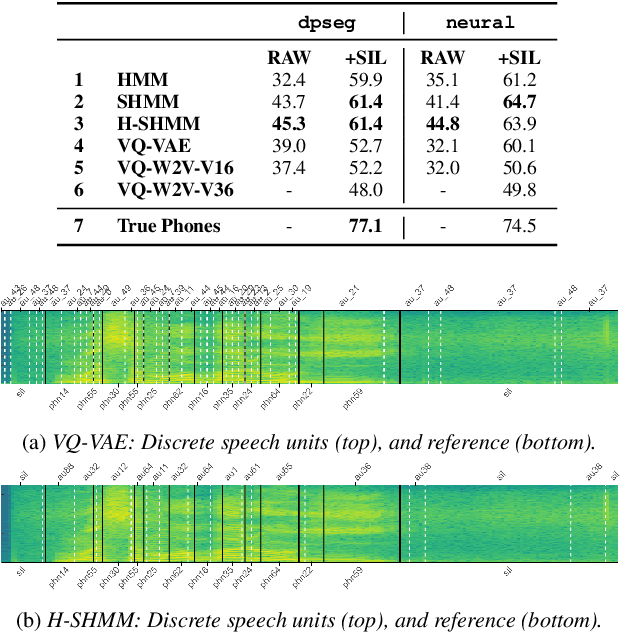
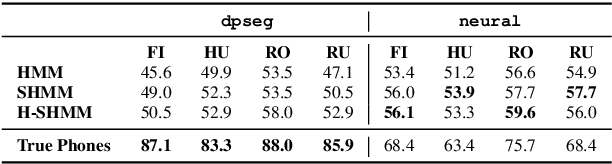
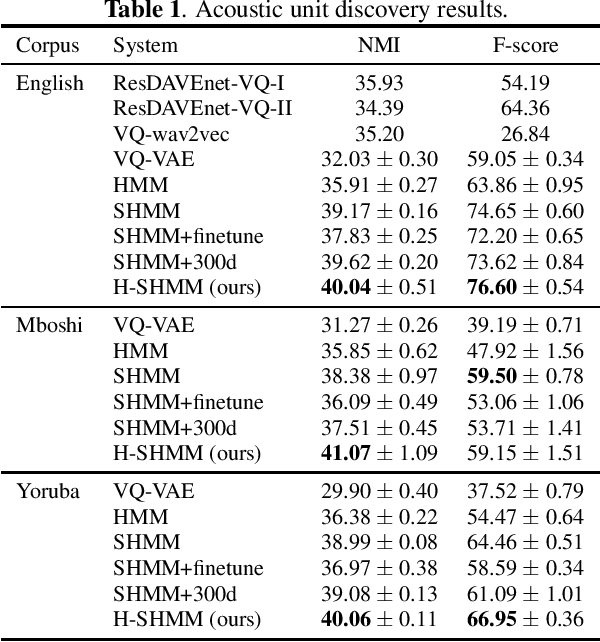
When documenting oral-languages, Unsupervised Word Segmentation (UWS) from speech is a useful, yet challenging, task. It can be performed from phonetic transcriptions, or in the absence of these, from the output of unsupervised speech discretization models. These discretization models are trained using raw speech only, producing discrete speech units which can be applied for downstream (text-based) tasks. In this paper we compare five of these models: three Bayesian and two neural approaches, with regards to the exploitability of the produced units for UWS. Two UWS models are experimented with and we report results for Finnish, Hungarian, Mboshi, Romanian and Russian in a low-resource setting (using only 5k sentences). Our results suggest that neural models for speech discretization are difficult to exploit in our setting, and that it might be necessary to adapt them to limit sequence length. We obtain our best UWS results by using the SHMM and H-SHMM Bayesian models, which produce high quality, yet compressed, discrete representations of the input speech signal.
A Hierarchical Subspace Model for Language-Attuned Acoustic Unit Discovery
Nov 09, 2020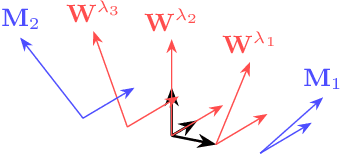
In this work, we propose a hierarchical subspace model for acoustic unit discovery. In this approach, we frame the task as one of learning embeddings on a low-dimensional phonetic subspace, and simultaneously specify the subspace itself as an embedding on a hyper-subspace. We train the hyper-subspace on a set of transcribed languages and transfer it to the target language. In the target language, we infer both the language and unit embeddings in an unsupervised manner, and in so doing, we simultaneously learn a subspace of units specific to that language and the units that dwell on it. We conduct our experiments on TIMIT and two low-resource languages: Mboshi and Yoruba. Results show that our model outperforms major acoustic unit discovery techniques, both in terms of clustering quality and segmentation accuracy.
The Zero Resource Speech Challenge 2020: Discovering discrete subword and word units
Oct 12, 2020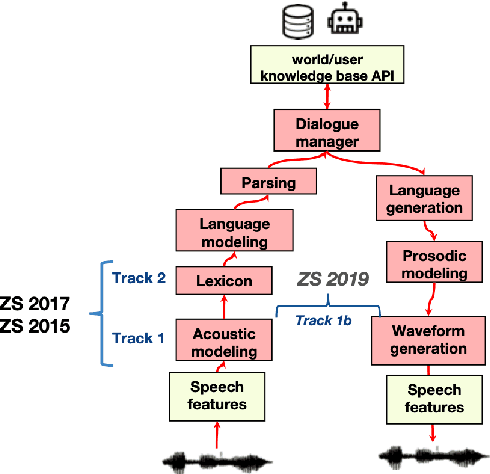

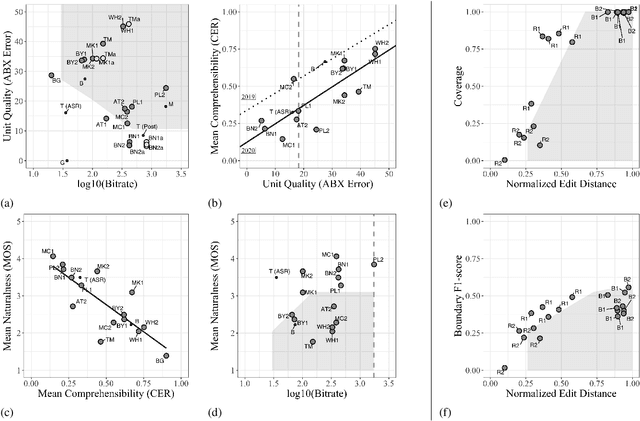
We present the Zero Resource Speech Challenge 2020, which aims at learning speech representations from raw audio signals without any labels. It combines the data sets and metrics from two previous benchmarks (2017 and 2019) and features two tasks which tap into two levels of speech representation. The first task is to discover low bit-rate subword representations that optimize the quality of speech synthesis; the second one is to discover word-like units from unsegmented raw speech. We present the results of the twenty submitted models and discuss the implications of the main findings for unsupervised speech learning.
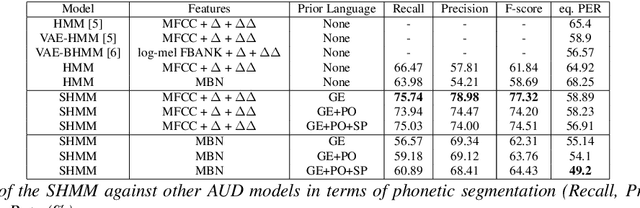
Bayesian Subspace HMM for the Zerospeech 2020 Challenge
May 19, 2020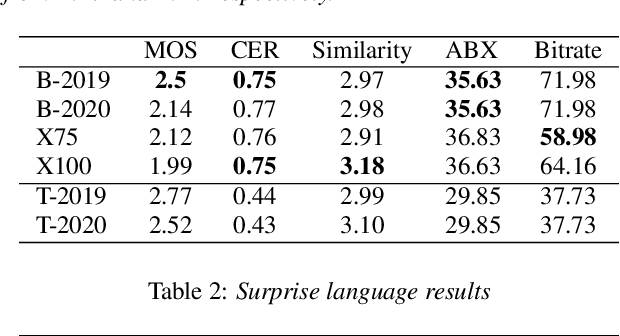
In this paper we describe our submission to the Zerospeech 2020 challenge, where the participants are required to discover latent representations from unannotated speech, and to use those representations to perform speech synthesis, with synthesis quality used as a proxy metric for the unit quality. In our system, we use the Bayesian Subspace Hidden Markov Model (SHMM) for unit discovery. The SHMM models each unit as an HMM whose parameters are constrained to lie in a low dimensional subspace of the total parameter space which is trained to model phonetic variability. Our system compares favorably with the baseline on the human-evaluated character error rate while maintaining significantly lower unit bitrate.
The Zero Resource Speech Challenge 2019: TTS without T
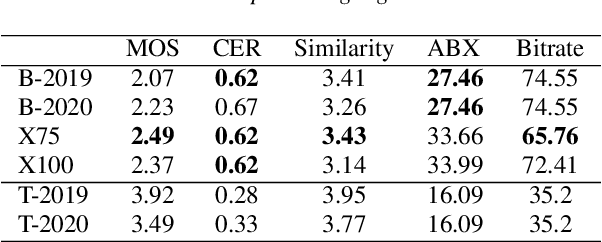
Apr 25, 2019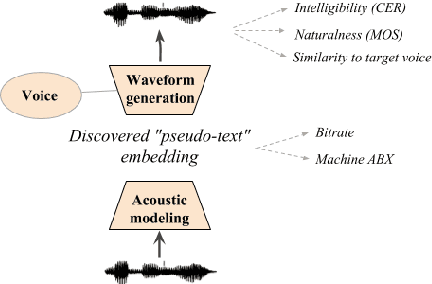
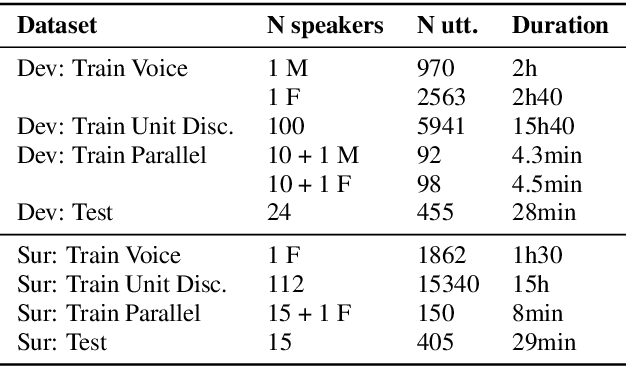
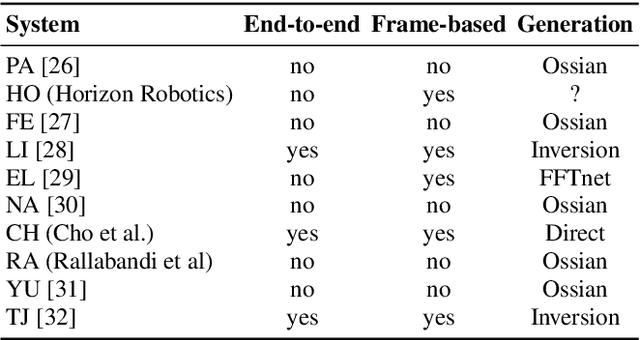
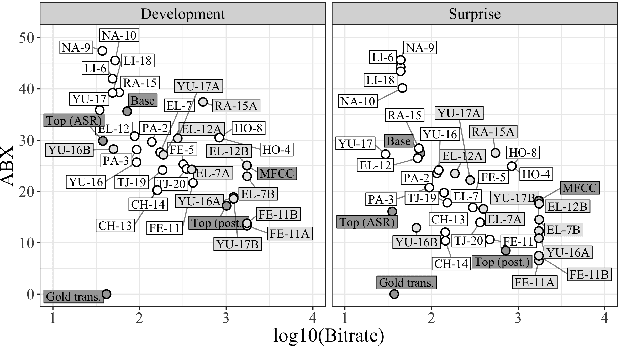
We present the Zero Resource Speech Challenge 2019, which proposes to build a speech synthesizer without any text or phonetic labels: hence, TTS without T (text-to-speech without text). We provide raw audio for a target voice in an unknown language (the Voice dataset), but no alignment, text or labels. Participants must discover subword units in an unsupervised way (using the Unit Discovery dataset) and align them to the voice recordings in a way that works best for the purpose of synthesizing novel utterances from novel speakers, similar to the target speaker's voice. We describe the metrics used for evaluation, a baseline system consisting of unsupervised subword unit discovery plus a standard TTS system, and a topline TTS using gold phoneme transcriptions. We present an overview of the 19 submitted systems from 11 teams and discuss the main results.
Bayesian Subspace Hidden Markov Model for Acoustic Unit Discovery
Apr 08, 2019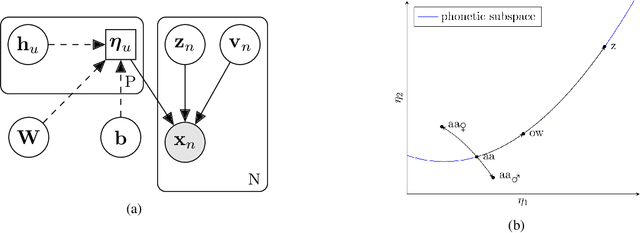
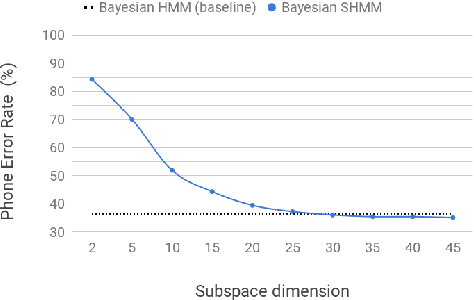
This work tackles the problem of learning a set of language specific acoustic units from unlabeled speech recordings given a set of labeled recordings from other languages. Our approach may be described by the following two steps procedure: first the model learns the notion of acoustic units from the labelled data and then the model uses its knowledge to find new acoustic units on the target language. We implement this process with the Bayesian Subspace Hidden Markov Model (SHMM), a model akin to the Subspace Gaussian Mixture Model (SGMM) where each low dimensional embedding represents an acoustic unit rather than just a HMM's state. The subspace is trained on 3 languages from the GlobalPhone corpus (German, Polish and Spanish) and the AUs are discovered on the TIMIT corpus. Results, measured in equivalent Phone Error Rate, show that this approach significantly outperforms previous HMM based acoustic units discovery systems and compares favorably with the Variational Auto Encoder-HMM.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018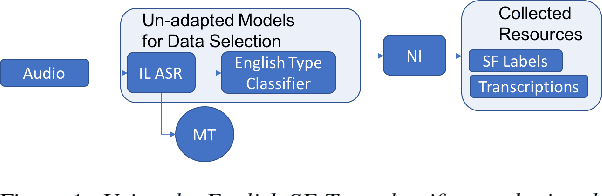
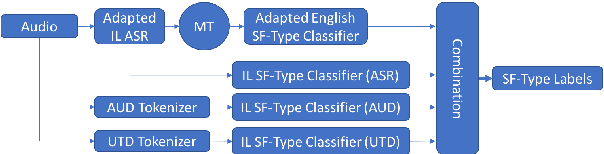
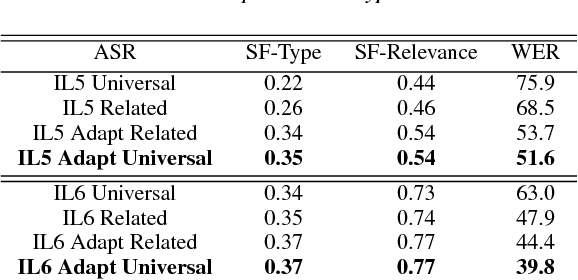
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
Unsupervised Word Segmentation from Speech with Attention
Jun 18, 2018

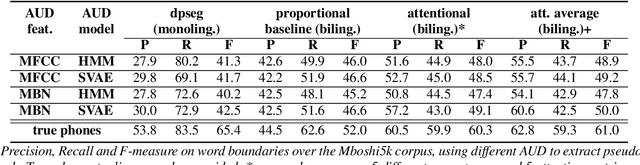
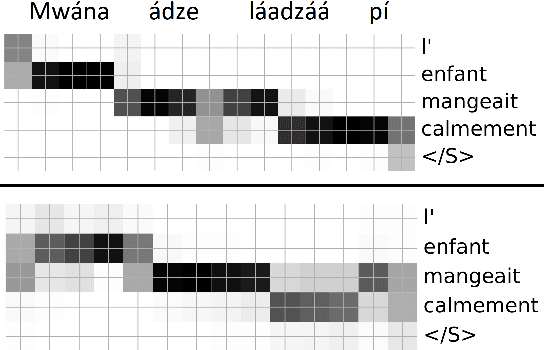
We present a first attempt to perform attentional word segmentation directly from the speech signal, with the final goal to automatically identify lexical units in a low-resource, unwritten language (UL). Our methodology assumes a pairing between recordings in the UL with translations in a well-resourced language. It uses Acoustic Unit Discovery (AUD) to convert speech into a sequence of pseudo-phones that is segmented using neural soft-alignments produced by a neural machine translation model. Evaluation uses an actual Bantu UL, Mboshi; comparisons to monolingual and bilingual baselines illustrate the potential of attentional word segmentation for language documentation.
Bayesian Models for Unit Discovery on a Very Low Resource Language
Feb 20, 2018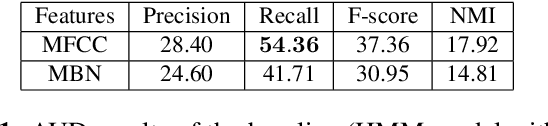
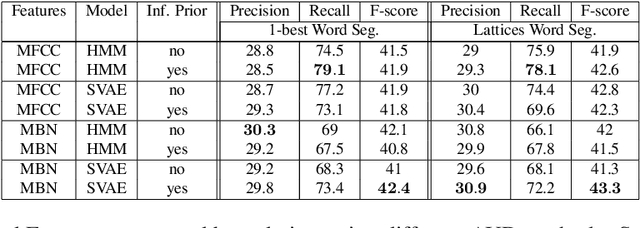
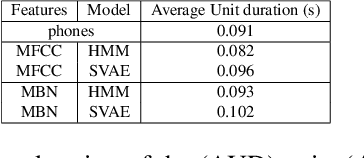
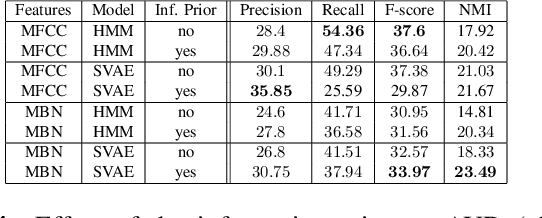
Developing speech technologies for low-resource languages has become a very active research field over the last decade. Among others, Bayesian models have shown some promising results on artificial examples but still lack of in situ experiments. Our work applies state-of-the-art Bayesian models to unsupervised Acoustic Unit Discovery (AUD) in a real low-resource language scenario. We also show that Bayesian models can naturally integrate information from other resourceful languages by means of informative prior leading to more consistent discovered units. Finally, discovered acoustic units are used, either as the 1-best sequence or as a lattice, to perform word segmentation. Word segmentation results show that this Bayesian approach clearly outperforms a Segmental-DTW baseline on the same corpus.