 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANe: Lighting-Aware Neural Fields for Compositional Scene Synthesis
Apr 06, 2023



Neural fields have recently enjoyed great success in representing and rendering 3D scenes. However, most state-of-the-art implicit representations model static or dynamic scenes as a whole, with minor variations. Existing work on learning disentangled world and object neural fields do not consider the problem of composing objects into different world neural fields in a lighting-aware manner. We present Lighting-Aware Neural Field (LANe) for the compositional synthesis of driving scenes in a physically consistent manner. Specifically, we learn a scene representation that disentangles the static background and transient elements into a world-NeRF and class-specific object-NeRFs to allow compositional synthesis of multiple objects in the scene. Furthermore, we explicitly designed both the world and object models to handle lighting variation, which allows us to compose objects into scenes with spatially varying lighting. This is achieved by constructing a light field of the scene and using it in conjunction with a learned shader to modulate the appearance of the object NeRFs. We demonstrate the performance of our model on a synthetic dataset of diverse lighting conditions rendered with the CARLA simulator, as well as a novel real-world dataset of cars collected at different times of the day. Our approach shows that it outperforms state-of-the-art compositional scene synthesis on the challenging dataset setup, via composing object-NeRFs learned from one scene into an entirely different scene whilst still respecting the lighting variations in the novel scene. For more results, please visit our project website https://lane-composition.github.io/.
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023



We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
Visual Estimation of Fingertip Pressure on Diverse Surfaces using Easily Captured Data
Jan 05, 2023



Prior research has shown that deep models can estimate the pressure applied by a hand to a surface based on a single RGB image. Training these models requires high-resolution pressure measurements that are difficult to obtain with physical sensors. Additionally, even experts cannot reliably annotate pressure from images. Thus, data collection is a critical barrier to generalization and improved performance. We present a novel approach that enables training data to be efficiently captured from unmodified surfaces with only an RGB camera and a cooperative participant. Our key insight is that people can be prompted to perform actions that correspond with categorical labels (contact labels) describing contact pressure, such as using a specific fingertip to make low-force contact. We present ContactLabelNet, which visually estimates pressure applied by fingertips. With the use of contact labels, ContactLabelNet achieves improved performance, generalizes to novel surfaces, and outperforms models from prior work.
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
Trust, but Verify: Cross-Modality Fusion for HD Map Change Detection
Dec 14, 2022High-definition (HD) map change detection is the task of determining when sensor data and map data are no longer in agreement with one another due to real-world changes. We collect the first dataset for the task, which we entitle the Trust, but Verify (TbV) dataset, by mining thousands of hours of data from over 9 months of autonomous vehicle fleet operations. We present learning-based formulations for solving the problem in the bird's eye view and ego-view. Because real map changes are infrequent and vector maps are easy to synthetically manipulate, we lean on simulated data to train our model. Perhaps surprisingly, we show that such models can generalize to real world distributions. The dataset, consisting of maps and logs collected in six North American cities, is one of the largest AV datasets to date with more than 7.8 million images. We make the data available to the public at https://www.argoverse.org/av2.html#mapchange-link, along with code and models at https://github.com/johnwlambert/tbv under the the CC BY-NC-SA 4.0 license.
Far3Det: Towards Far-Field 3D Detection
Nov 25, 2022



We focus on the task of far-field 3D detection (Far3Det) of objects beyond a certain distance from an observer, e.g., $>$50m. Far3Det is particularly important for autonomous vehicles (AVs) operating at highway speeds, which require detections of far-field obstacles to ensure sufficient braking distances. However, contemporary AV benchmarks such as nuScenes underemphasize this problem because they evaluate performance only up to a certain distance (50m). One reason is that obtaining far-field 3D annotations is difficult, particularly for lidar sensors that produce very few point returns for far-away objects. Indeed, we find that almost 50% of far-field objects (beyond 50m) contain zero lidar points. Secondly, current metrics for 3D detection employ a "one-size-fits-all" philosophy, using the same tolerance thresholds for near and far objects, inconsistent with tolerances for both human vision and stereo disparities. Both factors lead to an incomplete analysis of the Far3Det task. For example, while conventional wisdom tells us that high-resolution RGB sensors should be vital for 3D detection of far-away objects, lidar-based methods still rank higher compared to RGB counterparts on the current benchmark leaderboards. As a first step towards a Far3Det benchmark, we develop a method to find well-annotated scenes from the nuScenes dataset and derive a well-annotated far-field validation set. We also propose a Far3Det evaluation protocol and explore various 3D detection methods for Far3Det. Our result convincingly justifies the long-held conventional wisdom that high-resolution RGB improves 3D detection in the far-field. We further propose a simple yet effective method that fuses detections from RGB and lidar detectors based on non-maximum suppression, which remarkably outperforms state-of-the-art 3D detectors in the far-field.
Soft Augmentation for Image Classification
Nov 09, 2022



Modern neural networks are over-parameterized and thus rely on strong regularization such as data augmentation and weight decay to reduce overfitting and improve generalization. The dominant form of data augmentation applies invariant transforms, where the learning target of a sample is invariant to the transform applied to that sample. We draw inspiration from human visual classification studies and propose generalizing augmentation with invariant transforms to soft augmentation where the learning target softens non-linearly as a function of the degree of the transform applied to the sample: e.g., more aggressive image crop augmentations produce less confident learning targets. We demonstrate that soft targets allow for more aggressive data augmentation, offer more robust performance boosts, work with other augmentation policies, and interestingly, produce better calibrated models (since they are trained to be less confident on aggressively cropped/occluded examples). Combined with existing aggressive augmentation strategies, soft target 1) doubles the top-1 accuracy boost across Cifar-10, Cifar-100, ImageNet-1K, and ImageNet-V2, 2) improves model occlusion performance by up to $4\times$, and 3) halves the expected calibration error (ECE). Finally, we show that soft augmentation generalizes to self-supervised classification tasks.
A Sketch Is Worth a Thousand Words: Image Retrieval with Text and Sketch
Aug 05, 2022


We address the problem of retrieving images with both a sketch and a text query. We present TASK-former (Text And SKetch transformer), an end-to-end trainable model for image retrieval using a text description and a sketch as input. We argue that both input modalities complement each other in a manner that cannot be achieved easily by either one alone. TASK-former follows the late-fusion dual-encoder approach, similar to CLIP, which allows efficient and scalable retrieval since the retrieval set can be indexed independently of the queries. We empirically demonstrate that using an input sketch (even a poorly drawn one) in addition to text considerably increases retrieval recall compared to traditional text-based image retrieval. To evaluate our approach, we collect 5,000 hand-drawn sketches for images in the test set of the COCO dataset. The collected sketches are available a https://janesjanes.github.io/tsbir/.
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022

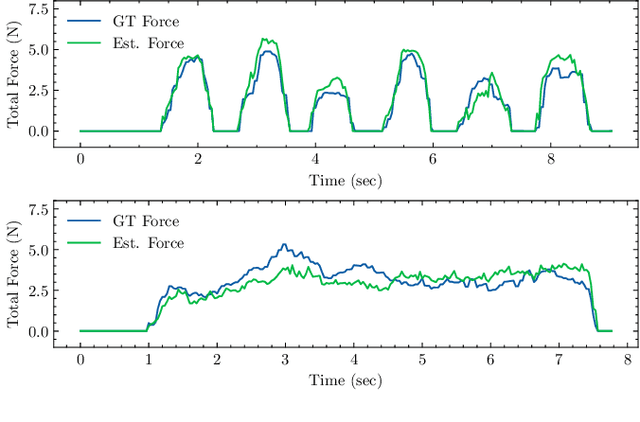
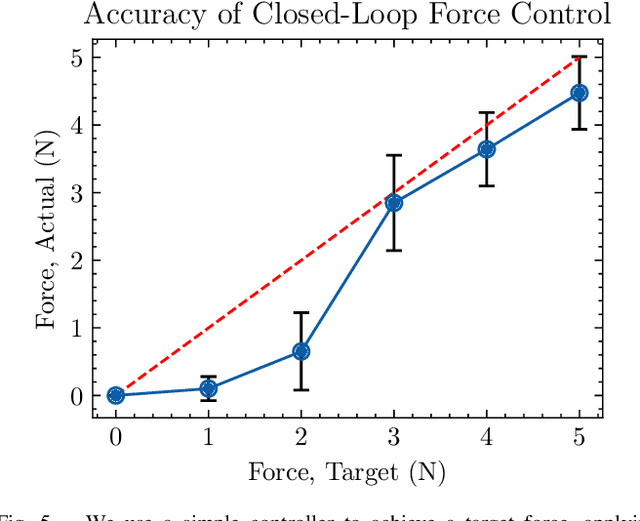
Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.
DRaCoN -- Differentiable Rasterization Conditioned Neural Radiance Fields for Articulated Avatars
Mar 29, 2022
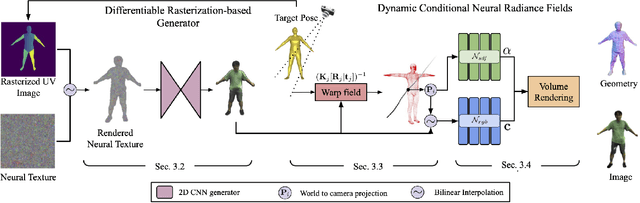
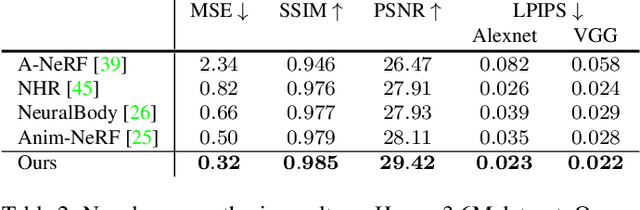
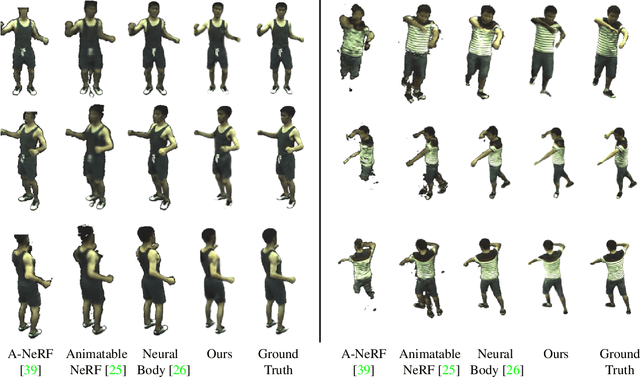
Acquisition and creation of digital human avatars is an important problem with applications to virtual telepresence, gaming, and human modeling. Most contemporary approaches for avatar generation can be viewed either as 3D-based methods, which use multi-view data to learn a 3D representation with appearance (such as a mesh, implicit surface, or volume), or 2D-based methods which learn photo-realistic renderings of avatars but lack accurate 3D representations. In this work, we present, DRaCoN, a framework for learning full-body volumetric avatars which exploits the advantages of both the 2D and 3D neural rendering techniques. It consists of a Differentiable Rasterization module, DiffRas, that synthesizes a low-resolution version of the target image along with additional latent features guided by a parametric body model. The output of DiffRas is then used as conditioning to our conditional neural 3D representation module (c-NeRF) which generates the final high-res image along with body geometry using volumetric rendering. While DiffRas helps in obtaining photo-realistic image quality, c-NeRF, which employs signed distance fields (SDF) for 3D representations, helps to obtain fine 3D geometric details. Experiments on the challenging ZJU-MoCap and Human3.6M datasets indicate that DRaCoN outperforms state-of-the-art methods both in terms of error metrics and visual quality.