 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
MHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
HUMOS: Human Motion Model Conditioned on Body Shape
Sep 05, 2024



Generating realistic human motion is essential for many computer vision and graphics applications. The wide variety of human body shapes and sizes greatly impacts how people move. However, most existing motion models ignore these differences, relying on a standardized, average body. This leads to uniform motion across different body types, where movements don't match their physical characteristics, limiting diversity. To solve this, we introduce a new approach to develop a generative motion model based on body shape. We show that it's possible to train this model using unpaired data by applying cycle consistency, intuitive physics, and stability constraints, which capture the relationship between identity and movement. The resulting model generates diverse, physically plausible, and dynamically stable human motions that are both quantitatively and qualitatively more realistic than current state-of-the-art methods. More details are available on our project page https://CarstenEpic.github.io/humos/.
EPOCH: Jointly Estimating the 3D Pose of Cameras and Humans
Jun 28, 2024Monocular Human Pose Estimation (HPE) aims at determining the 3D positions of human joints from a single 2D image captured by a camera. However, a single 2D point in the image may correspond to multiple points in 3D space. Typically, the uniqueness of the 2D-3D relationship is approximated using an orthographic or weak-perspective camera model. In this study, instead of relying on approximations, we advocate for utilizing the full perspective camera model. This involves estimating camera parameters and establishing a precise, unambiguous 2D-3D relationship. To do so, we introduce the EPOCH framework, comprising two main components: the pose lifter network (LiftNet) and the pose regressor network (RegNet). LiftNet utilizes the full perspective camera model to precisely estimate the 3D pose in an unsupervised manner. It takes a 2D pose and camera parameters as inputs and produces the corresponding 3D pose estimation. These inputs are obtained from RegNet, which starts from a single image and provides estimates for the 2D pose and camera parameters. RegNet utilizes only 2D pose data as weak supervision. Internally, RegNet predicts a 3D pose, which is then projected to 2D using the estimated camera parameters. This process enables RegNet to establish the unambiguous 2D-3D relationship. Our experiments show that modeling the lifting as an unsupervised task with a camera in-the-loop results in better generalization to unseen data. We obtain state-of-the-art results for the 3D HPE on the Human3.6M and MPI-INF-3DHP datasets. Our code is available at: [Github link upon acceptance, see supplementary materials].
fNeRF: High Quality Radiance Fields from Practical Cameras
Jun 15, 2024



In recent years, the development of Neural Radiance Fields has enabled a previously unseen level of photo-realistic 3D reconstruction of scenes and objects from multi-view camera data. However, previous methods use an oversimplified pinhole camera model resulting in defocus blur being `baked' into the reconstructed radiance field. We propose a modification to the ray casting that leverages the optics of lenses to enhance scene reconstruction in the presence of defocus blur. This allows us to improve the quality of radiance field reconstructions from the measurements of a practical camera with finite aperture. We show that the proposed model matches the defocus blur behavior of practical cameras more closely than pinhole models and other approximations of defocus blur models, particularly in the presence of partial occlusions. This allows us to achieve sharper reconstructions, improving the PSNR on validation of all-in-focus images, on both synthetic and real datasets, by up to 3 dB.
Personalized 3D Human Pose and Shape Refinement
Mar 18, 2024



Recently, regression-based methods have dominated the field of 3D human pose and shape estimation. Despite their promising results, a common issue is the misalignment between predictions and image observations, often caused by minor joint rotation errors that accumulate along the kinematic chain. To address this issue, we propose to construct dense correspondences between initial human model estimates and the corresponding images that can be used to refine the initial predictions. To this end, we utilize renderings of the 3D models to predict per-pixel 2D displacements between the synthetic renderings and the RGB images. This allows us to effectively integrate and exploit appearance information of the persons. Our per-pixel displacements can be efficiently transformed to per-visible-vertex displacements and then used for 3D model refinement by minimizing a reprojection loss. To demonstrate the effectiveness of our approach, we refine the initial 3D human mesh predictions of multiple models using different refinement procedures on 3DPW and RICH. We show that our approach not only consistently leads to better image-model alignment, but also to improved 3D accuracy.
* Accepted to 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
ANR: Articulated Neural Rendering for Virtual Avatars
Dec 23, 2020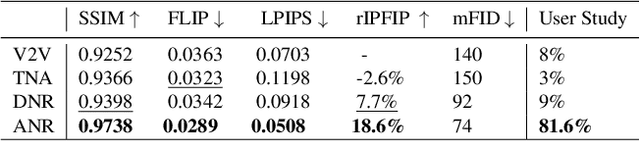
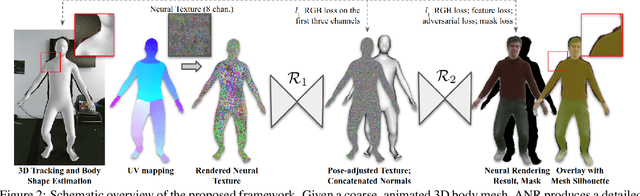
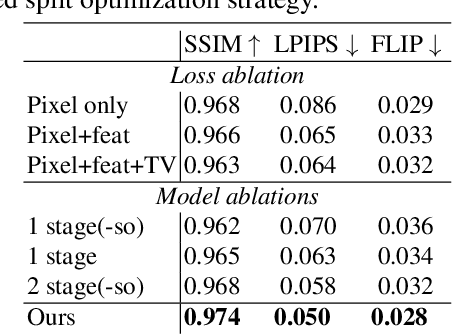
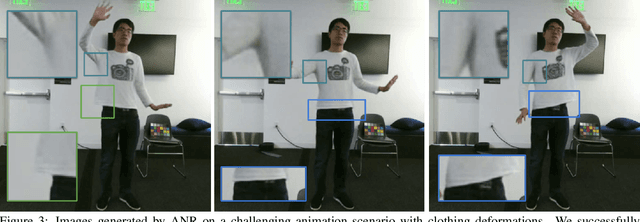
The combination of traditional rendering with neural networks in Deferred Neural Rendering (DNR) provides a compelling balance between computational complexity and realism of the resulting images. Using skinned meshes for rendering articulating objects is a natural extension for the DNR framework and would open it up to a plethora of applications. However, in this case the neural shading step must account for deformations that are possibly not captured in the mesh, as well as alignment inaccuracies and dynamics -- which can confound the DNR pipeline. We present Articulated Neural Rendering (ANR), a novel framework based on DNR which explicitly addresses its limitations for virtual human avatars. We show the superiority of ANR not only with respect to DNR but also with methods specialized for avatar creation and animation. In two user studies, we observe a clear preference for our avatar model and we demonstrate state-of-the-art performance on quantitative evaluation metrics. Perceptually, we observe better temporal stability, level of detail and plausibility.
TexMesh: Reconstructing Detailed Human Texture and Geometry from RGB-D Video
Aug 29, 2020
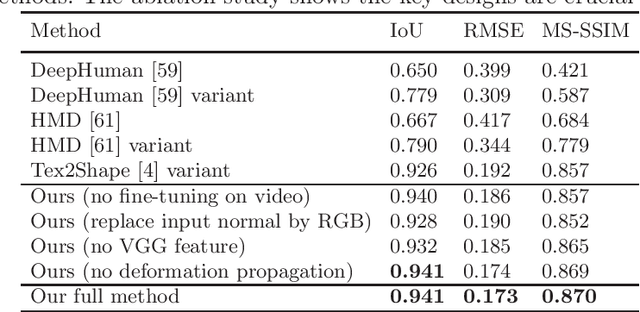
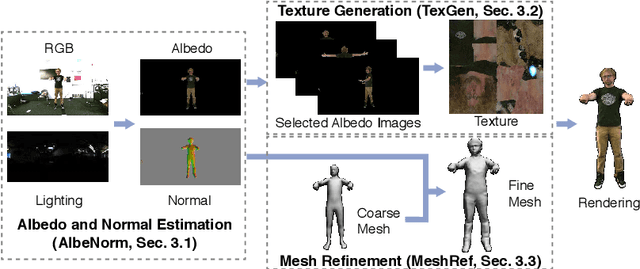

We present TexMesh, a novel approach to reconstruct detailed human meshes with high-resolution full-body texture from RGB-D video. TexMesh enables high quality free-viewpoint rendering of humans. Given the RGB frames, the captured environment map, and the coarse per-frame human mesh from RGB-D tracking, our method reconstructs spatiotemporally consistent and detailed per-frame meshes along with a high-resolution albedo texture. By using the incident illumination we are able to accurately estimate local surface geometry and albedo, which allows us to further use photometric constraints to adapt a synthetically trained model to real-world sequences in a self-supervised manner for detailed surface geometry and high-resolution texture estimation. In practice, we train our models on a short example sequence for self-adaptation and the model runs at interactive framerate afterwards. We validate TexMesh on synthetic and real-world data, and show it outperforms the state of art quantitatively and qualitatively.
PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations
Aug 04, 2020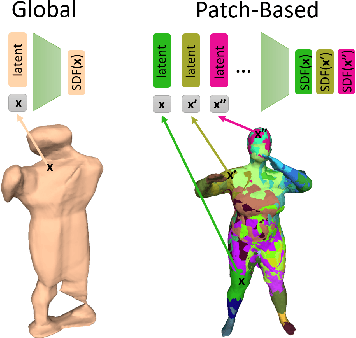
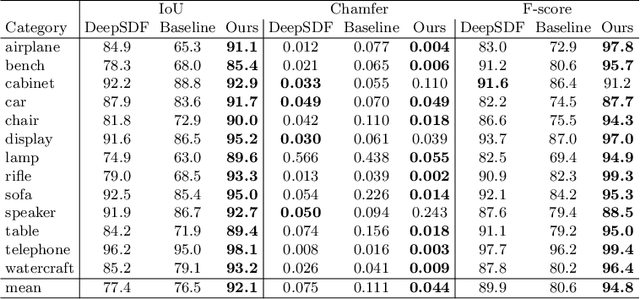

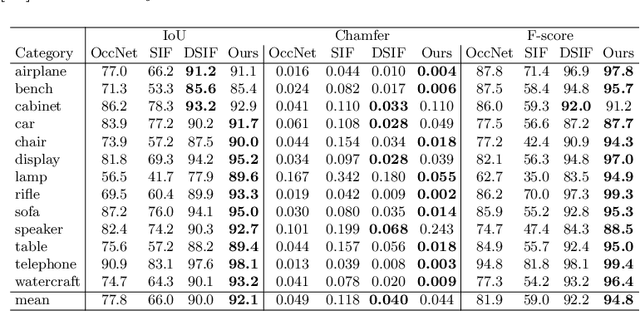
Implicit surface representations, such as signed-distance functions, combined with deep learning have led to impressive models which can represent detailed shapes of objects with arbitrary topology. Since a continuous function is learned, the reconstructions can also be extracted at any arbitrary resolution. However, large datasets such as ShapeNet are required to train such models. In this paper, we present a new mid-level patch-based surface representation. At the level of patches, objects across different categories share similarities, which leads to more generalizable models. We then introduce a novel method to learn this patch-based representation in a canonical space, such that it is as object-agnostic as possible. We show that our representation trained on one category of objects from ShapeNet can also well represent detailed shapes from any other category. In addition, it can be trained using much fewer shapes, compared to existing approaches. We show several applications of our new representation, including shape interpolation and partial point cloud completion. Due to explicit control over positions, orientations and scales of patches, our representation is also more controllable compared to object-level representations, which enables us to deform encoded shapes non-rigidly.