 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-patch Feature Pyramid Network for Weakly Supervised Object Detection in Optical Remote Sensing Images
Aug 18, 2021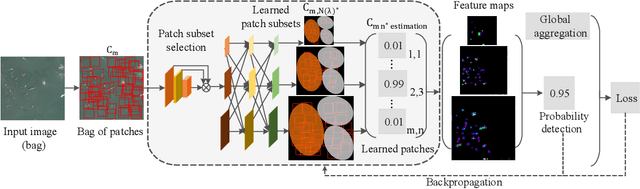
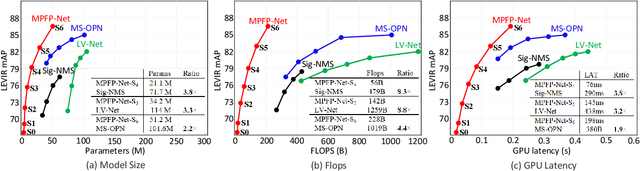
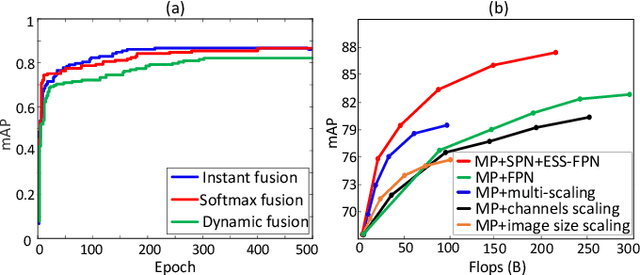
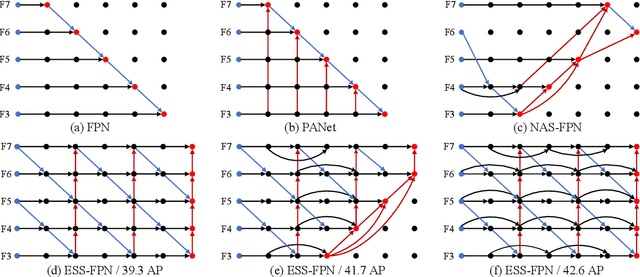
Object detection is a challenging task in remote sensing because objects only occupy a few pixels in the images, and the models are required to simultaneously learn object locations and detection. Even though the established approaches well perform for the objects of regular sizes, they achieve weak performance when analyzing small ones or getting stuck in the local minima (e.g. false object parts). Two possible issues stand in their way. First, the existing methods struggle to perform stably on the detection of small objects because of the complicated background. Second, most of the standard methods used hand-crafted features, and do not work well on the detection of objects parts of which are missing. We here address the above issues and propose a new architecture with a multiple patch feature pyramid network (MPFP-Net). Different from the current models that during training only pursue the most discriminative patches, in MPFPNet the patches are divided into class-affiliated subsets, in which the patches are related and based on the primary loss function, a sequence of smooth loss functions are determined for the subsets to improve the model for collecting small object parts. To enhance the feature representation for patch selection, we introduce an effective method to regularize the residual values and make the fusion transition layers strictly norm-preserving. The network contains bottom-up and crosswise connections to fuse the features of different scales to achieve better accuracy, compared to several state-of-the-art object detection models. Also, the developed architecture is more efficient than the baselines.
MPI: Multi-receptive and Parallel Integration for Salient Object Detection
Aug 08, 2021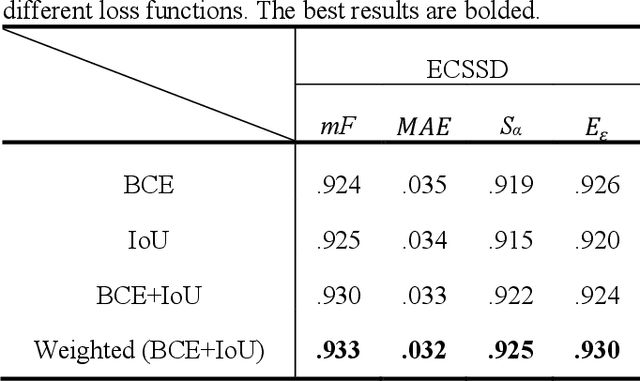
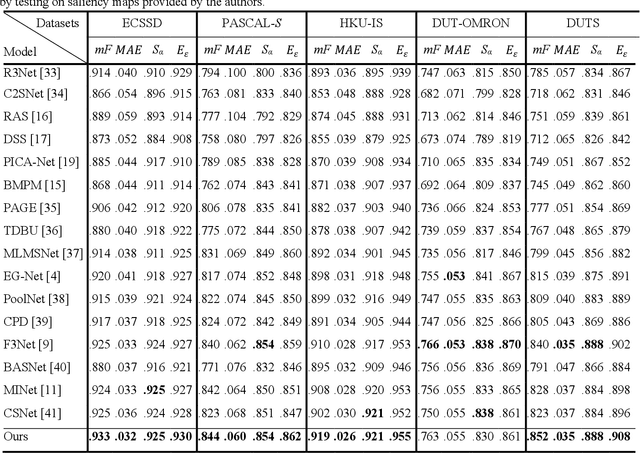
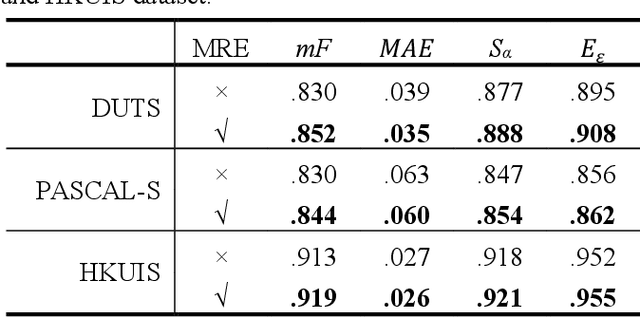
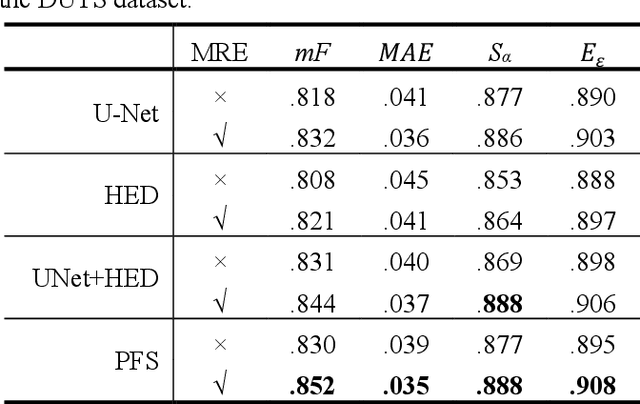
The semantic representation of deep features is essential for image context understanding, and effective fusion of features with different semantic representations can significantly improve the model's performance on salient object detection. In this paper, a novel method called MPI is proposed for salient object detection. Firstly, a multi-receptive enhancement module (MRE) is designed to effectively expand the receptive fields of features from different layers and generate features with different receptive fields. MRE can enhance the semantic representation and improve the model's perception of the image context, which enables the model to locate the salient object accurately. Secondly, in order to reduce the reuse of redundant information in the complex top-down fusion method and weaken the differences between semantic features, a relatively simple but effective parallel fusion strategy (PFS) is proposed. It allows multi-scale features to better interact with each other, thus improving the overall performance of the model. Experimental results on multiple datasets demonstrate that the proposed method outperforms state-of-the-art methods under different evaluation metrics.
Adaptive Affinity Loss and Erroneous Pseudo-Label Refinement for Weakly Supervised Semantic Segmentation
Aug 03, 2021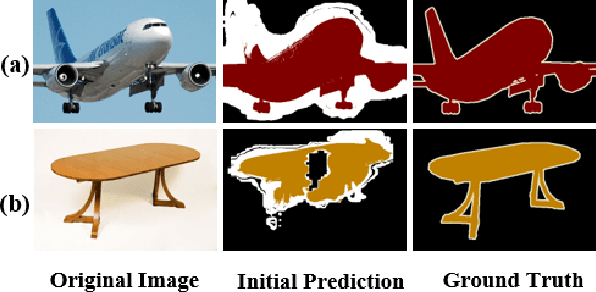
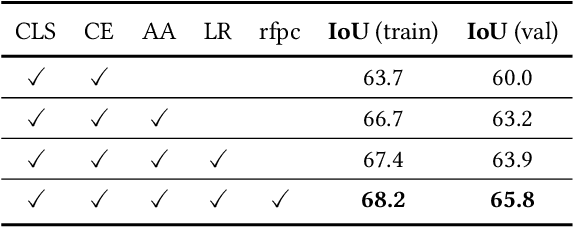
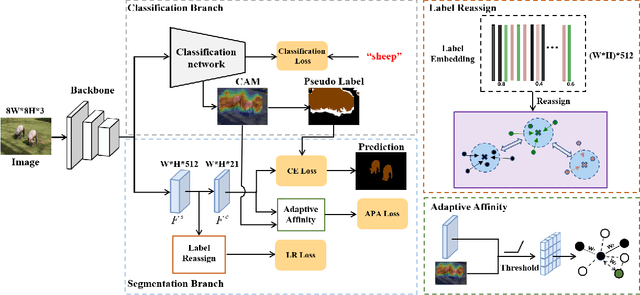
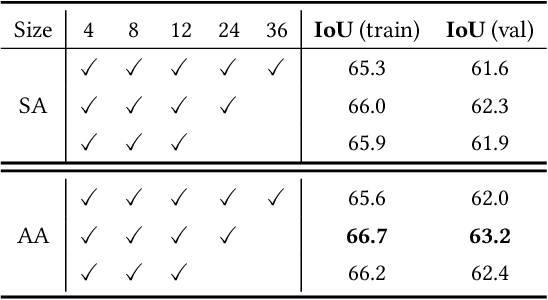
Semantic segmentation has been continuously investigated in the last ten years, and majority of the established technologies are based on supervised models. In recent years, image-level weakly supervised semantic segmentation (WSSS), including single- and multi-stage process, has attracted large attention due to data labeling efficiency. In this paper, we propose to embed affinity learning of multi-stage approaches in a single-stage model. To be specific, we introduce an adaptive affinity loss to thoroughly learn the local pairwise affinity. As such, a deep neural network is used to deliver comprehensive semantic information in the training phase, whilst improving the performance of the final prediction module. On the other hand, considering the existence of errors in the pseudo labels, we propose a novel label reassign loss to mitigate over-fitting. Extensive experiments are conducted on the PASCAL VOC 2012 dataset to evaluate the effectiveness of our proposed approach that outperforms other standard single-stage methods and achieves comparable performance against several multi-stage methods.
Semantic Attention and Scale Complementary Network for Instance Segmentation in Remote Sensing Images
Jul 25, 2021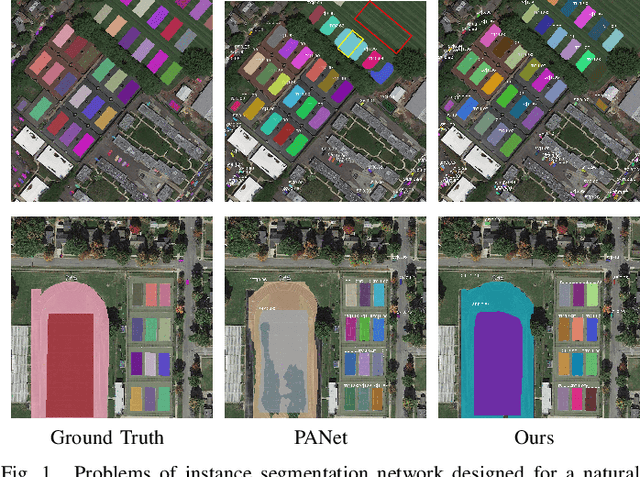

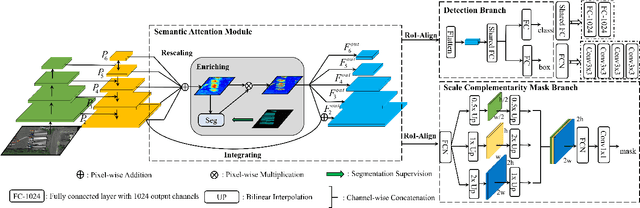
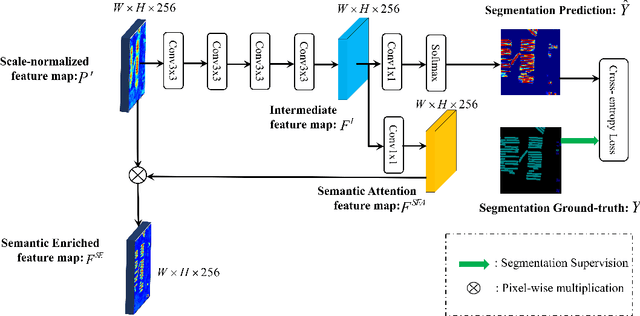
In this paper, we focus on the challenging multicategory instance segmentation problem in remote sensing images (RSIs), which aims at predicting the categories of all instances and localizing them with pixel-level masks. Although many landmark frameworks have demonstrated promising performance in instance segmentation, the complexity in the background and scale variability instances still remain challenging for instance segmentation of RSIs. To address the above problems, we propose an end-to-end multi-category instance segmentation model, namely Semantic Attention and Scale Complementary Network, which mainly consists of a Semantic Attention (SEA) module and a Scale Complementary Mask Branch (SCMB). The SEA module contains a simple fully convolutional semantic segmentation branch with extra supervision to strengthen the activation of interest instances on the feature map and reduce the background noise's interference. To handle the under-segmentation of geospatial instances with large varying scales, we design the SCMB that extends the original single mask branch to trident mask branches and introduces complementary mask supervision at different scales to sufficiently leverage the multi-scale information. We conduct comprehensive experiments to evaluate the effectiveness of our proposed method on the iSAID dataset and the NWPU Instance Segmentation dataset and achieve promising performance.
Incorporating Lambertian Priors into Surface Normals Measurement
Jul 15, 2021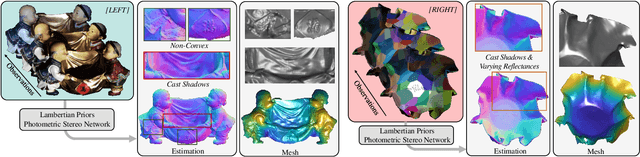
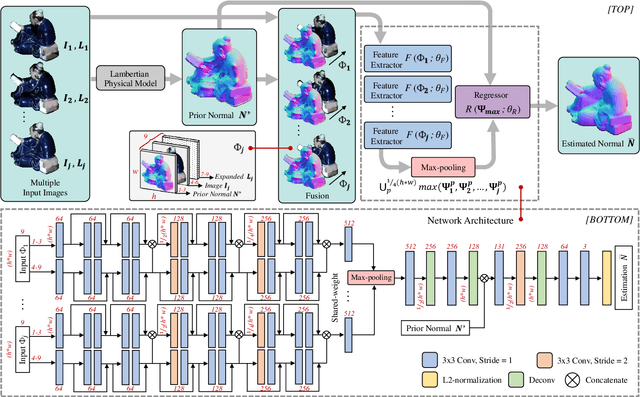
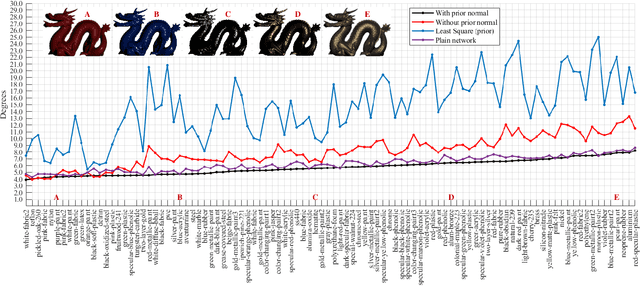
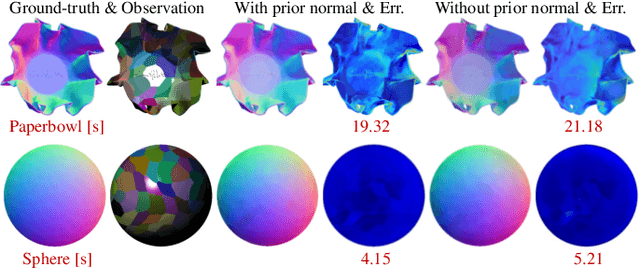
The goal of photometric stereo is to measure the precise surface normal of a 3D object from observations with various shading cues. However, non-Lambertian surfaces influence the measurement accuracy due to irregular shading cues. Despite deep neural networks have been employed to simulate the performance of non-Lambertian surfaces, the error in specularities, shadows, and crinkle regions is hard to be reduced. In order to address this challenge, we here propose a photometric stereo network that incorporates Lambertian priors to better measure the surface normal. In this paper, we use the initial normal under the Lambertian assumption as the prior information to refine the normal measurement, instead of solely applying the observed shading cues to deriving the surface normal. Our method utilizes the Lambertian information to reparameterize the network weights and the powerful fitting ability of deep neural networks to correct these errors caused by general reflectance properties. Our explorations include: the Lambertian priors (1) reduce the learning hypothesis space, making our method learn the mapping in the same surface normal space and improving the accuracy of learning, and (2) provides the differential features learning, improving the surfaces reconstruction of details. Extensive experiments verify the effectiveness of the proposed Lambertian prior photometric stereo network in accurate surface normal measurement, on the challenging benchmark dataset.
Magnification-independent Histopathological Image Classification with Similarity-based Multi-scale Embeddings
Jul 02, 2021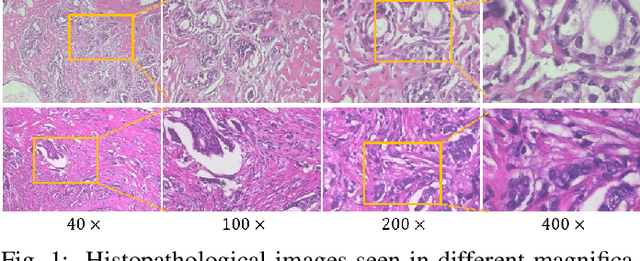
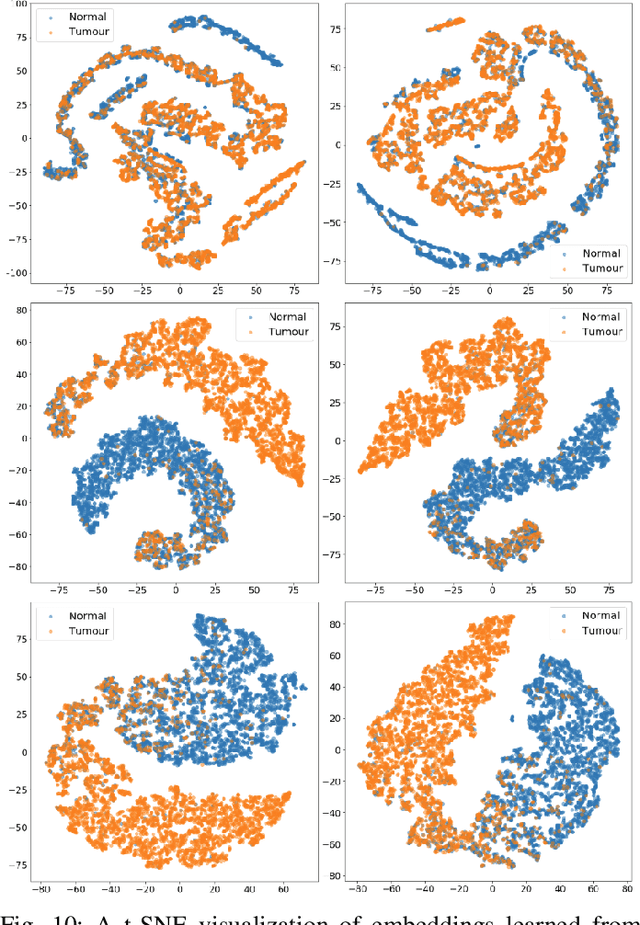
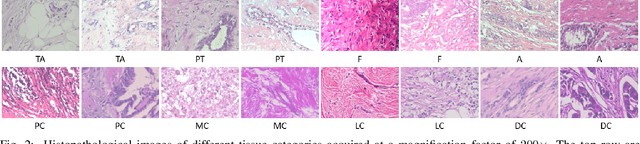
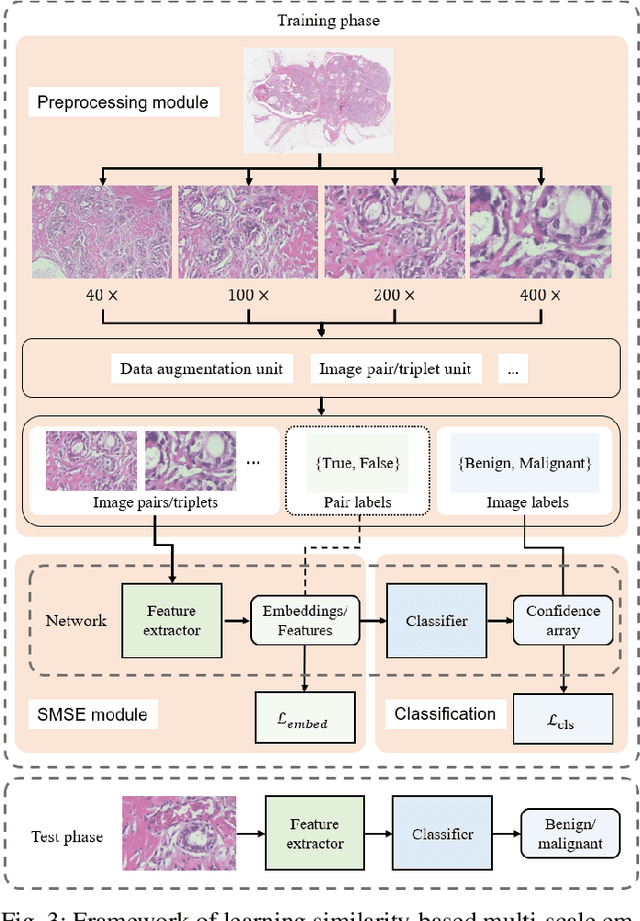
The classification of histopathological images is of great value in both cancer diagnosis and pathological studies. However, multiple reasons, such as variations caused by magnification factors and class imbalance, make it a challenging task where conventional methods that learn from image-label datasets perform unsatisfactorily in many cases. We observe that tumours of the same class often share common morphological patterns. To exploit this fact, we propose an approach that learns similarity-based multi-scale embeddings (SMSE) for magnification-independent histopathological image classification. In particular, a pair loss and a triplet loss are leveraged to learn similarity-based embeddings from image pairs or image triplets. The learned embeddings provide accurate measurements of similarities between images, which are regarded as a more effective form of representation for histopathological morphology than normal image features. Furthermore, in order to ensure the generated models are magnification-independent, images acquired at different magnification factors are simultaneously fed to networks during training for learning multi-scale embeddings. In addition to the SMSE, to eliminate the impact of class imbalance, instead of using the hard sample mining strategy that intuitively discards some easy samples, we introduce a new reinforced focal loss to simultaneously punish hard misclassified samples while suppressing easy well-classified samples. Experimental results show that the SMSE improves the performance for histopathological image classification tasks for both breast and liver cancers by a large margin compared to previous methods. In particular, the SMSE achieves the best performance on the BreakHis benchmark with an improvement ranging from 5% to 18% compared to previous methods using traditional features.
SRPN: similarity-based region proposal networks for nuclei and cells detection in histology images
Jun 25, 2021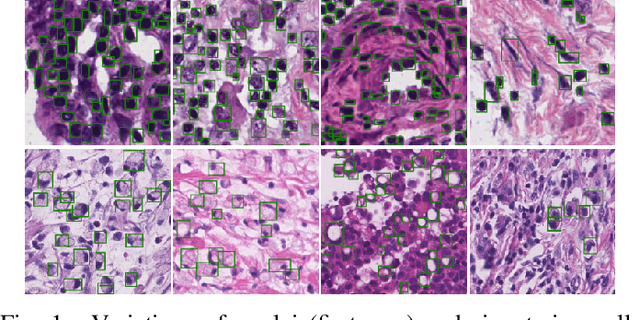
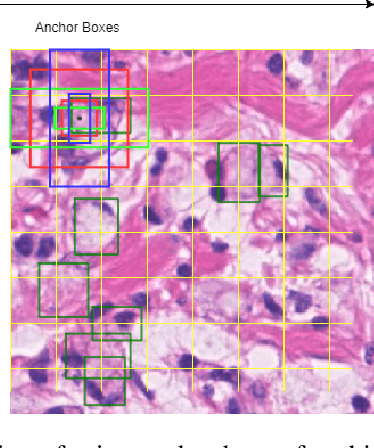
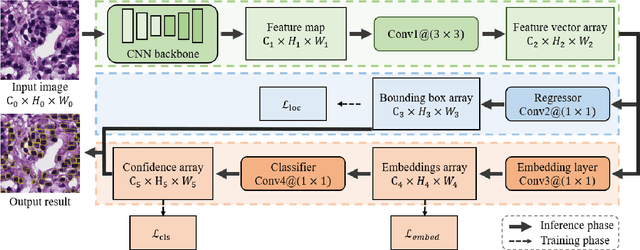
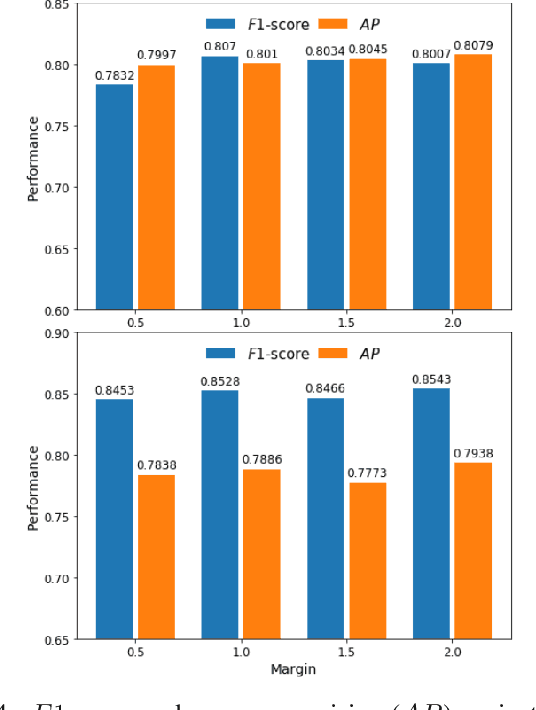
The detection of nuclei and cells in histology images is of great value in both clinical practice and pathological studies. However, multiple reasons such as morphological variations of nuclei or cells make it a challenging task where conventional object detection methods cannot obtain satisfactory performance in many cases. A detection task consists of two sub-tasks, classification and localization. Under the condition of dense object detection, classification is a key to boost the detection performance. Considering this, we propose similarity based region proposal networks (SRPN) for nuclei and cells detection in histology images. In particular, a customized convolution layer termed as embedding layer is designed for network building. The embedding layer is added into the region proposal networks, enabling the networks to learn discriminative features based on similarity learning. Features obtained by similarity learning can significantly boost the classification performance compared to conventional methods. SRPN can be easily integrated into standard convolutional neural networks architectures such as the Faster R-CNN and RetinaNet. We test the proposed approach on tasks of multi-organ nuclei detection and signet ring cells detection in histological images. Experimental results show that networks applying similarity learning achieved superior performance on both tasks when compared to their counterparts. In particular, the proposed SRPN achieve state-of-the-art performance on the MoNuSeg benchmark for nuclei segmentation and detection while compared to previous methods, and on the signet ring cell detection benchmark when compared with baselines. The sourcecode is publicly available at: https://github.com/sigma10010/nuclei_cells_det.
* Accepted by Medical Image Analysis for publication
Wallpaper Texture Generation and Style Transfer Based on Multi-label Semantics
Jun 22, 2021


Textures contain a wealth of image information and are widely used in various fields such as computer graphics and computer vision. With the development of machine learning, the texture synthesis and generation have been greatly improved. As a very common element in everyday life, wallpapers contain a wealth of texture information, making it difficult to annotate with a simple single label. Moreover, wallpaper designers spend significant time to create different styles of wallpaper. For this purpose, this paper proposes to describe wallpaper texture images by using multi-label semantics. Based on these labels and generative adversarial networks, we present a framework for perception driven wallpaper texture generation and style transfer. In this framework, a perceptual model is trained to recognize whether the wallpapers produced by the generator network are sufficiently realistic and have the attribute designated by given perceptual description; these multi-label semantic attributes are treated as condition variables to generate wallpaper images. The generated wallpaper images can be converted to those with well-known artist styles using CycleGAN. Finally, using the aesthetic evaluation method, the generated wallpaper images are quantitatively measured. The experimental results demonstrate that the proposed method can generate wallpaper textures conforming to human aesthetics and have artistic characteristics.
Learning the Precise Feature for Cluster Assignment
Jun 11, 2021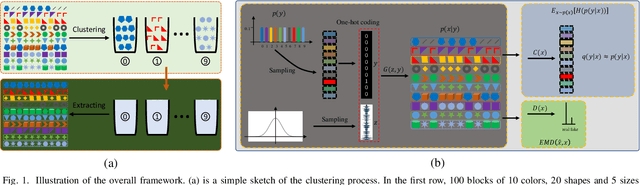
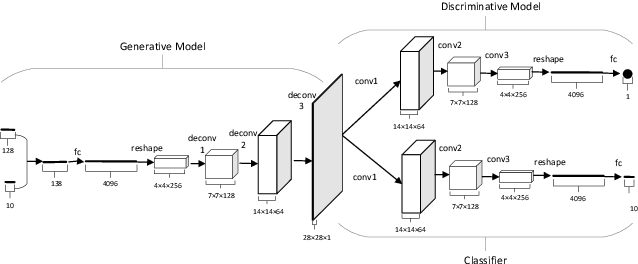
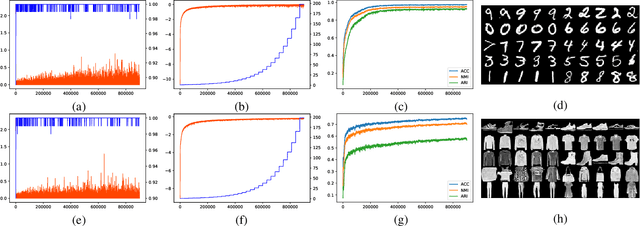
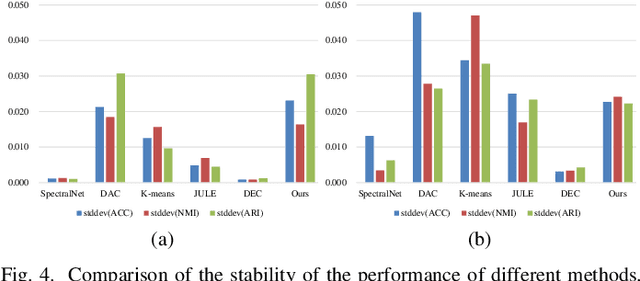
Clustering is one of the fundamental tasks in computer vision and pattern recognition. Recently, deep clustering methods (algorithms based on deep learning) have attracted wide attention with their impressive performance. Most of these algorithms combine deep unsupervised representation learning and standard clustering together. However, the separation of representation learning and clustering will lead to suboptimal solutions because the two-stage strategy prevents representation learning from adapting to subsequent tasks (e.g., clustering according to specific cues). To overcome this issue, efforts have been made in the dynamic adaption of representation and cluster assignment, whereas current state-of-the-art methods suffer from heuristically constructed objectives with representation and cluster assignment alternatively optimized. To further standardize the clustering problem, we audaciously formulate the objective of clustering as finding a precise feature as the cue for cluster assignment. Based on this, we propose a general-purpose deep clustering framework which radically integrates representation learning and clustering into a single pipeline for the first time. The proposed framework exploits the powerful ability of recently developed generative models for learning intrinsic features, and imposes an entropy minimization on the distribution of the cluster assignment by a dedicated variational algorithm. Experimental results show that the performance of the proposed method is superior, or at least comparable to, the state-of-the-art methods on the handwritten digit recognition, fashion recognition, face recognition and object recognition benchmark datasets.
Rotation Equivariant Feature Image Pyramid Network for Object Detection in Optical Remote Sensing Imagery
Jun 03, 2021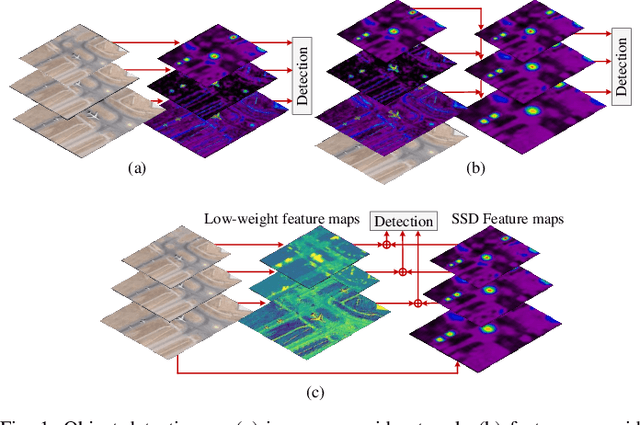
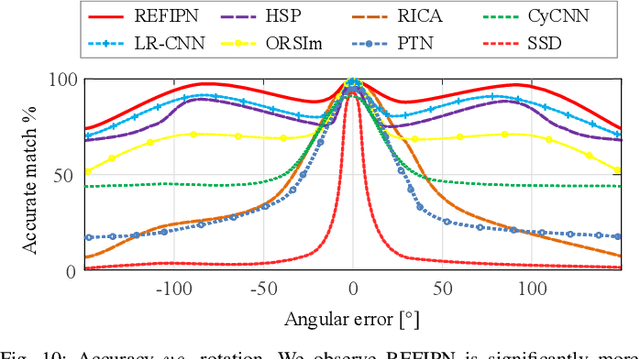
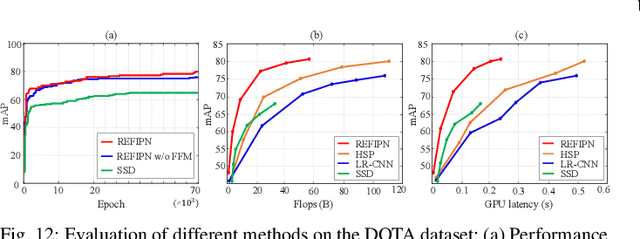
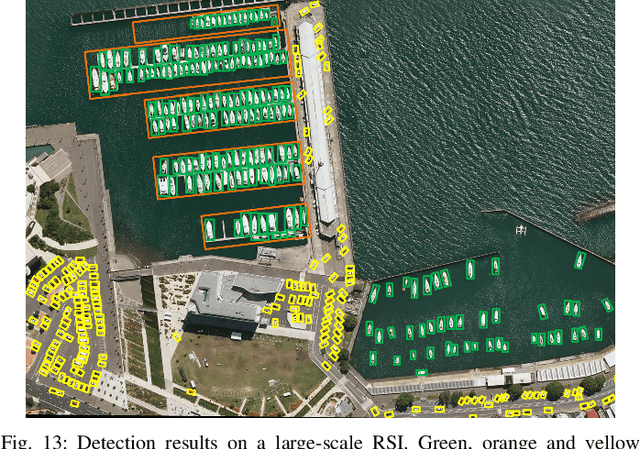
Over the last few years, there has been substantial progress in object detection on remote sensing images (RSIs) where objects are generally distributed with large-scale variations and have different types of orientations. Nevertheless, most of the current convolution neural network approaches lack the ability to deal with the challenges such as size and rotation variations. To address these problems, we propose the rotation equivariant feature image pyramid network (REFIPN), an image pyramid network based on rotation equivariance convolution. The proposed pyramid network extracts features in a wide range of scales and orientations by using novel convolution filters. These features are used to generate vector fields and determine the weight and angle of the highest-scoring orientation for all spatial locations on an image. Finally, the extracted features go through the prediction layers of the detector. The detection performance of the proposed model is validated on two commonly used aerial benchmarks and the results show our propose model can achieve state-of-the-art performance with satisfactory efficiency.