 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBDEC:Brain Deep Embedded Clustering model
Sep 12, 2023An essential premise for neuroscience brain network analysis is the successful segmentation of the cerebral cortex into functionally homogeneous regions. Resting-state functional magnetic resonance imaging (rs-fMRI), capturing the spontaneous activities of the brain, provides the potential for cortical parcellation. Previous parcellation methods can be roughly categorized into three groups, mainly employing either local gradient, global similarity, or a combination of both. The traditional clustering algorithms, such as "K-means" and "Spectral clustering" may affect the reproducibility or the biological interpretation of parcellations; The region growing-based methods influence the expression of functional homogeneity in the brain at a large scale; The parcellation method based on probabilistic graph models inevitably introduce model assumption biases. In this work, we develop an assumption-free model called as BDEC, which leverages the robust data fitting capability of deep learning. To the best of our knowledge, this is the first study that uses deep learning algorithm for rs-fMRI-based parcellation. By comparing with nine commonly used brain parcellation methods, the BDEC model demonstrates significantly superior performance in various functional homogeneity indicators. Furthermore, it exhibits favorable results in terms of validity, network analysis, task homogeneity, and generalization capability. These results suggest that the BDEC parcellation captures the functional characteristics of the brain and holds promise for future voxel-wise brain network analysis in the dimensionality reduction of fMRI data.
ContrastMotion: Self-supervised Scene Motion Learning for Large-Scale LiDAR Point Clouds
Apr 25, 2023



In this paper, we propose a novel self-supervised motion estimator for LiDAR-based autonomous driving via BEV representation. Different from usually adopted self-supervised strategies for data-level structure consistency, we predict scene motion via feature-level consistency between pillars in consecutive frames, which can eliminate the effect caused by noise points and view-changing point clouds in dynamic scenes. Specifically, we propose \textit{Soft Discriminative Loss} that provides the network with more pseudo-supervised signals to learn discriminative and robust features in a contrastive learning manner. We also propose \textit{Gated Multi-frame Fusion} block that learns valid compensation between point cloud frames automatically to enhance feature extraction. Finally, \textit{pillar association} is proposed to predict pillar correspondence probabilities based on feature distance, and whereby further predicts scene motion. Extensive experiments show the effectiveness and superiority of our \textbf{ContrastMotion} on both scene flow and motion prediction tasks. The code is available soon.
Energy-Efficient Cellular-Connected UAV Swarm Control Optimization
Mar 18, 2023Cellular-connected unmanned aerial vehicle (UAV) swarm is a promising solution for diverse applications, including cargo delivery and traffic control. However, it is still challenging to communicate with and control the UAV swarm with high reliability, low latency, and high energy efficiency. In this paper, we propose a two-phase command and control (C&C) transmission scheme in a cellular-connected UAV swarm network, where the ground base station (GBS) broadcasts the common C&C message in Phase I. In Phase II, the UAVs that have successfully decoded the C&C message will relay the message to the rest of UAVs via device-to-device (D2D) communications in either broadcast or unicast mode, under latency and energy constraints. To maximize the number of UAVs that receive the message successfully within the latency and energy constraints, we formulate the problem as a Constrained Markov Decision Process to find the optimal policy. To address this problem, we propose a decentralized constrained graph attention multi-agent Deep-Q-network (DCGA-MADQN) algorithm based on Lagrangian primal-dual policy optimization, where a PID-controller algorithm is utilized to update the Lagrange Multiplier. Simulation results show that our algorithm could maximize the number of UAVs that successfully receive the common C&C under energy constraints.
Task-Oriented and Semantics-Aware 6G Networks
Oct 17, 2022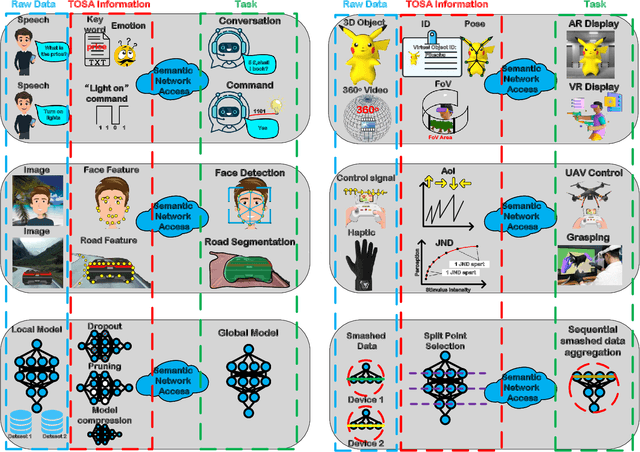
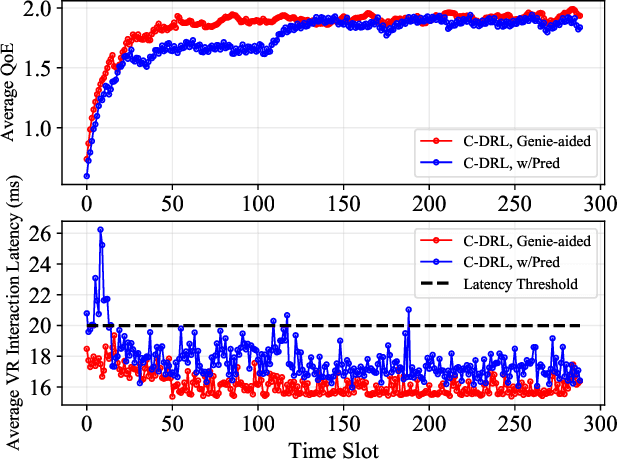
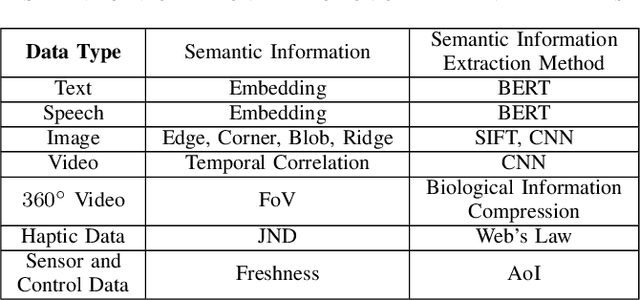
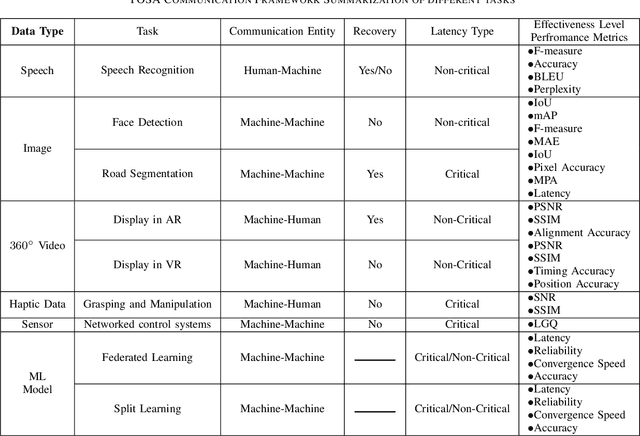
Upon the arrival of emerging devices, including Extended Reality (XR) and Unmanned Aerial Vehicles (UAVs), the traditional bit-oriented communication framework is approaching Shannon's physical capacity limit and fails to guarantee the massive amount of transmission within latency requirements. By jointly exploiting the context of data and its importance to the task, an emerging communication paradigm shift to semantic level and effectiveness level is envisioned to be a key revolution in Sixth Generation (6G) networks. However, an explicit and systematic communication framework incorporating both semantic level and effectiveness level has not been proposed yet. In this article, we propose a generic task-oriented and semantics-aware (TOSA) communication framework for various tasks with diverse data types, which incorporates both semantic level information and effectiveness level performance metrics. We first analyze the unique characteristics of all data types, and summarise the semantic information, along with corresponding extraction methods. We then propose a detailed TOSA communication framework for different time critical and non-critical tasks. In the TOSA framework, we present the TOSA information, extraction methods, recovery methods, and effectiveness level performance metrics. Last but not least, we present a TOSA framework tailored for Virtual Reality (VR) data with interactive VR tasks to validate the effectiveness of the proposed TOSA communication framework.
LiDAR-based 4D Panoptic Segmentation via Dynamic Shifting Network
Mar 14, 2022
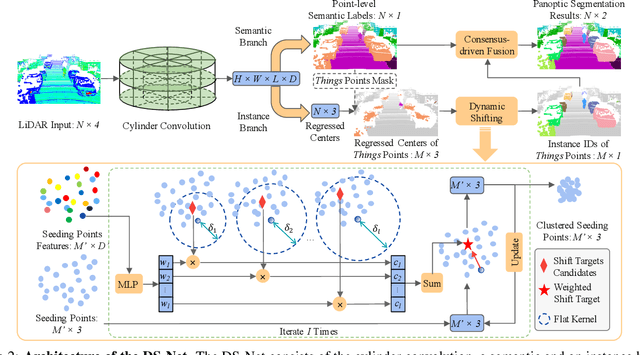

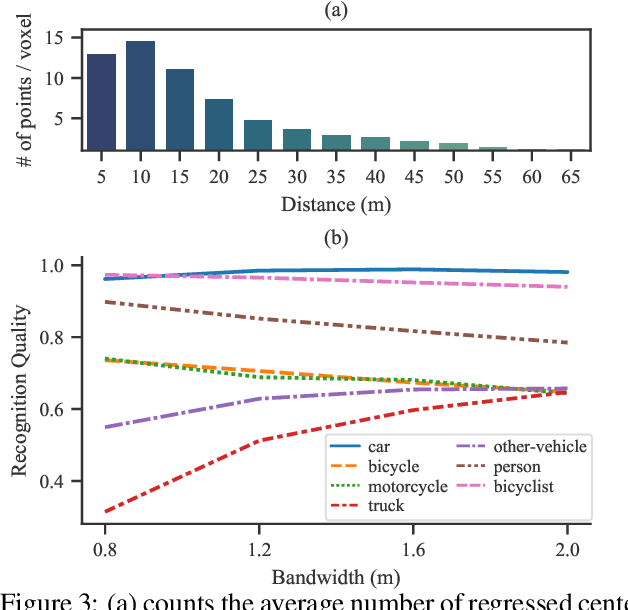
With the rapid advances of autonomous driving, it becomes critical to equip its sensing system with more holistic 3D perception. However, existing works focus on parsing either the objects (e.g. cars and pedestrians) or scenes (e.g. trees and buildings) from the LiDAR sensor. In this work, we address the task of LiDAR-based panoptic segmentation, which aims to parse both objects and scenes in a unified manner. As one of the first endeavors towards this new challenging task, we propose the Dynamic Shifting Network (DS-Net), which serves as an effective panoptic segmentation framework in the point cloud realm. In particular, DS-Net has three appealing properties: 1) Strong backbone design. DS-Net adopts the cylinder convolution that is specifically designed for LiDAR point clouds. 2) Dynamic Shifting for complex point distributions. We observe that commonly-used clustering algorithms are incapable of handling complex autonomous driving scenes with non-uniform point cloud distributions and varying instance sizes. Thus, we present an efficient learnable clustering module, dynamic shifting, which adapts kernel functions on the fly for different instances. 3) Extension to 4D prediction. Furthermore, we extend DS-Net to 4D panoptic LiDAR segmentation by the temporally unified instance clustering on aligned LiDAR frames. To comprehensively evaluate the performance of LiDAR-based panoptic segmentation, we construct and curate benchmarks from two large-scale autonomous driving LiDAR datasets, SemanticKITTI and nuScenes. Extensive experiments demonstrate that our proposed DS-Net achieves superior accuracies over current state-of-the-art methods in both tasks. Notably, in the single frame version of the task, we outperform the SOTA method by 1.8% in terms of the PQ metric. In the 4D version of the task, we surpass 2nd place by 5.4% in terms of the LSTQ metric.
AdaStereo: An Efficient Domain-Adaptive Stereo Matching Approach
Dec 09, 2021
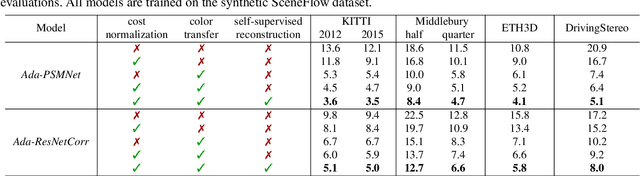
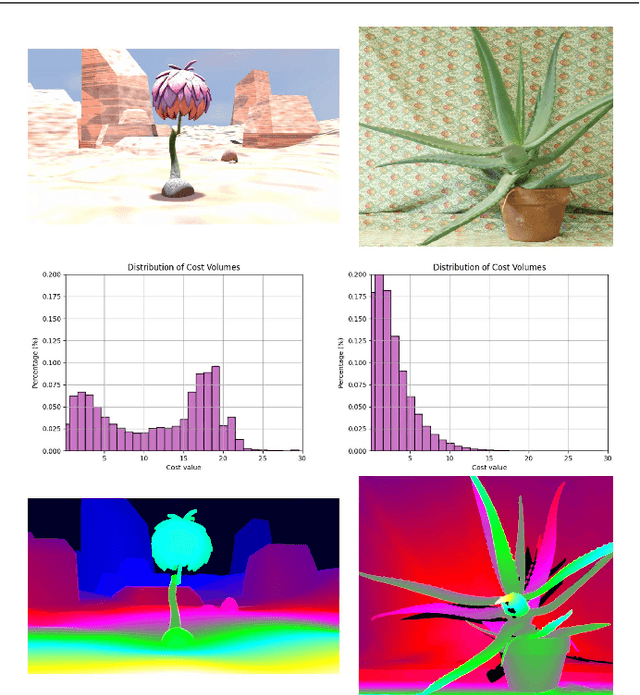
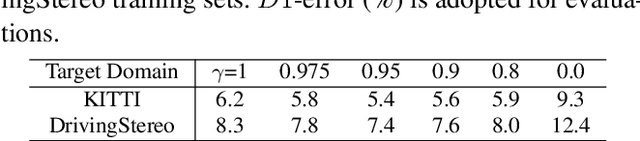
Recently, records on stereo matching benchmarks are constantly broken by end-to-end disparity networks. However, the domain adaptation ability of these deep models is quite limited. Addressing such problem, we present a novel domain-adaptive approach called AdaStereo that aims to align multi-level representations for deep stereo matching networks. Compared to previous methods, our AdaStereo realizes a more standard, complete and effective domain adaptation pipeline. Firstly, we propose a non-adversarial progressive color transfer algorithm for input image-level alignment. Secondly, we design an efficient parameter-free cost normalization layer for internal feature-level alignment. Lastly, a highly related auxiliary task, self-supervised occlusion-aware reconstruction is presented to narrow the gaps in output space. We perform intensive ablation studies and break-down comparisons to validate the effectiveness of each proposed module. With no extra inference overhead and only a slight increase in training complexity, our AdaStereo models achieve state-of-the-art cross-domain performance on multiple benchmarks, including KITTI, Middlebury, ETH3D and DrivingStereo, even outperforming some state-of-the-art disparity networks finetuned with target-domain ground-truths. Moreover, based on two additional evaluation metrics, the superiority of our domain-adaptive stereo matching pipeline is further uncovered from more perspectives. Finally, we demonstrate that our method is robust to various domain adaptation settings, and can be easily integrated into quick adaptation application scenarios and real-world deployments.
Code Clone Detection based on Event Embedding and Event Dependency
Nov 28, 2021
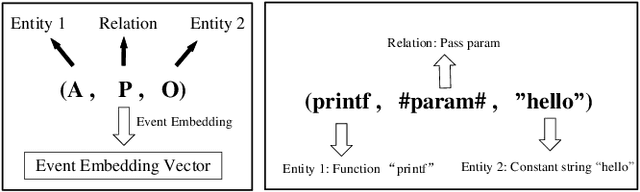
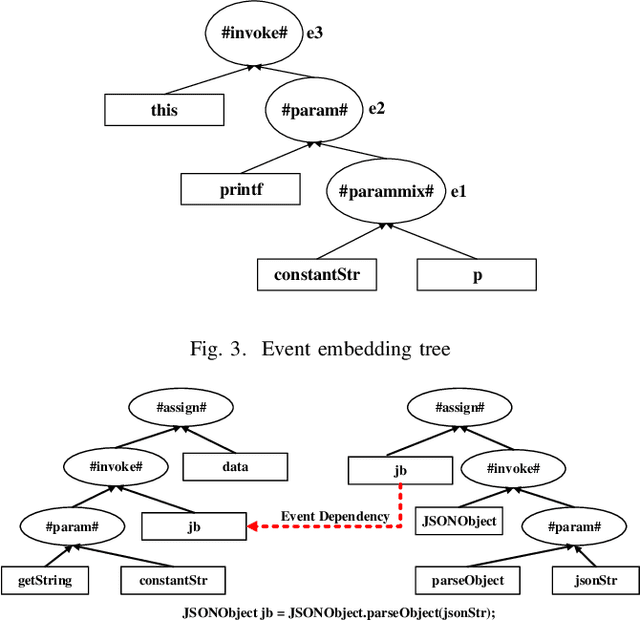
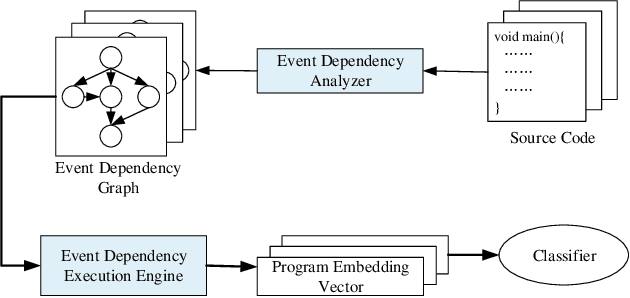
The code clone detection method based on semantic similarity has important value in software engineering tasks (e.g., software evolution, software reuse). Traditional code clone detection technologies pay more attention to the similarity of code at the syntax level, and less attention to the semantic similarity of the code. As a result, candidate codes similar in semantics are ignored. To address this issue, we propose a code clone detection method based on semantic similarity. By treating code as a series of interdependent events that occur continuously, we design a model namely EDAM to encode code semantic information based on event embedding and event dependency. The EDAM model uses the event embedding method to model the execution characteristics of program statements and the data dependence information between all statements. In this way, we can embed the program semantic information into a vector and use the vector to detect codes similar in semantics. Experimental results show that the performance of our EDAM model is superior to state of-the-art open source models for code clone detection.
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR-based Perception
Sep 12, 2021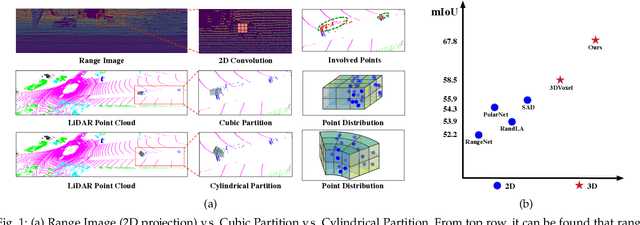
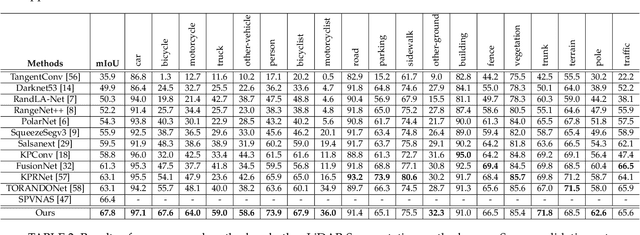
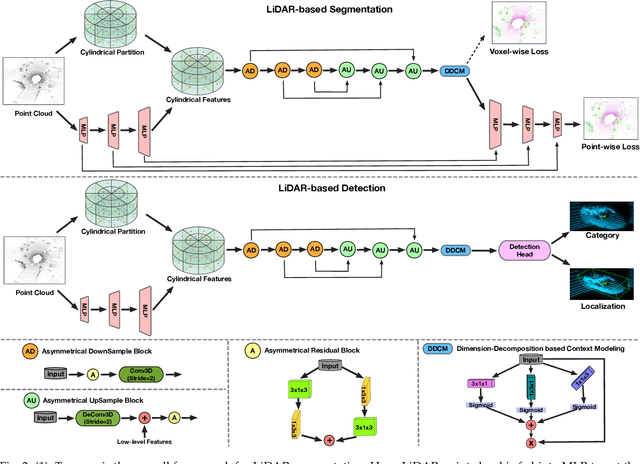
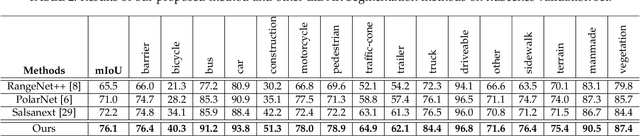
State-of-the-art methods for driving-scene LiDAR-based perception (including point cloud semantic segmentation, panoptic segmentation and 3D detection, \etc) often project the point clouds to 2D space and then process them via 2D convolution. Although this cooperation shows the competitiveness in the point cloud, it inevitably alters and abandons the 3D topology and geometric relations. A natural remedy is to utilize the 3D voxelization and 3D convolution network. However, we found that in the outdoor point cloud, the improvement obtained in this way is quite limited. An important reason is the property of the outdoor point cloud, namely sparsity and varying density. Motivated by this investigation, we propose a new framework for the outdoor LiDAR segmentation, where cylindrical partition and asymmetrical 3D convolution networks are designed to explore the 3D geometric pattern while maintaining these inherent properties. The proposed model acts as a backbone and the learned features from this model can be used for downstream tasks such as point cloud semantic and panoptic segmentation or 3D detection. In this paper, we benchmark our model on these three tasks. For semantic segmentation, we evaluate the proposed model on several large-scale datasets, \ie, SemanticKITTI, nuScenes and A2D2. Our method achieves the state-of-the-art on the leaderboard of SemanticKITTI (both single-scan and multi-scan challenge), and significantly outperforms existing methods on nuScenes and A2D2 dataset. Furthermore, the proposed 3D framework also shows strong performance and good generalization on LiDAR panoptic segmentation and LiDAR 3D detection.
Revisiting Recursive Least Squares for Training Deep Neural Networks
Sep 07, 2021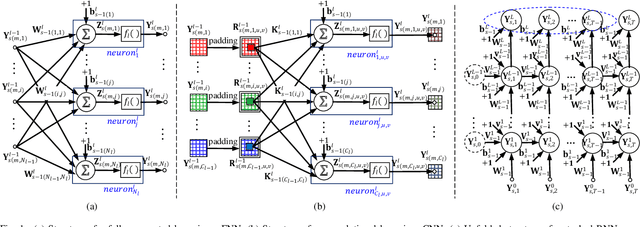
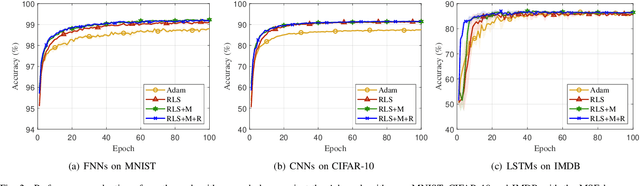
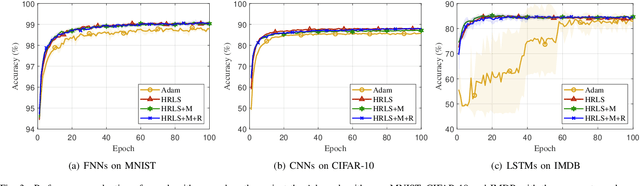
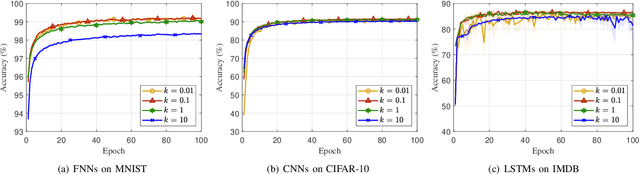
Recursive least squares (RLS) algorithms were once widely used for training small-scale neural networks, due to their fast convergence. However, previous RLS algorithms are unsuitable for training deep neural networks (DNNs), since they have high computational complexity and too many preconditions. In this paper, to overcome these drawbacks, we propose three novel RLS optimization algorithms for training feedforward neural networks, convolutional neural networks and recurrent neural networks (including long short-term memory networks), by using the error backpropagation and our average-approximation RLS method, together with the equivalent gradients of the linear least squares loss function with respect to the linear outputs of hidden layers. Compared with previous RLS optimization algorithms, our algorithms are simple and elegant. They can be viewed as an improved stochastic gradient descent (SGD) algorithm, which uses the inverse autocorrelation matrix of each layer as the adaptive learning rate. Their time and space complexities are only several times those of SGD. They only require the loss function to be the mean squared error and the activation function of the output layer to be invertible. In fact, our algorithms can be also used in combination with other first-order optimization algorithms without requiring these two preconditions. In addition, we present two improved methods for our algorithms. Finally, we demonstrate their effectiveness compared to the Adam algorithm on MNIST, CIFAR-10 and IMDB datasets, and investigate the influences of their hyperparameters experimentally.
LIF-Seg: LiDAR and Camera Image Fusion for 3D LiDAR Semantic Segmentation
Aug 17, 2021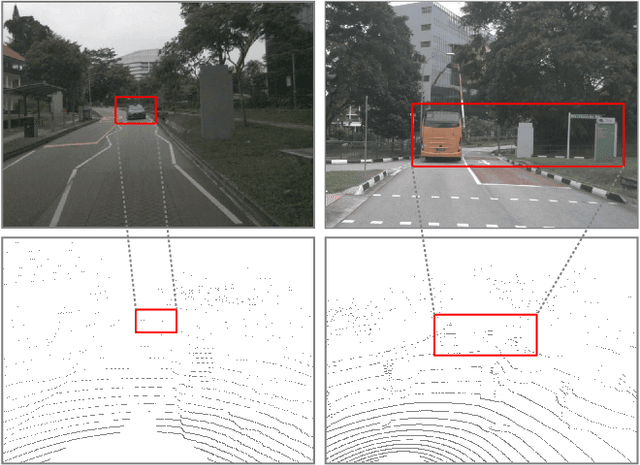

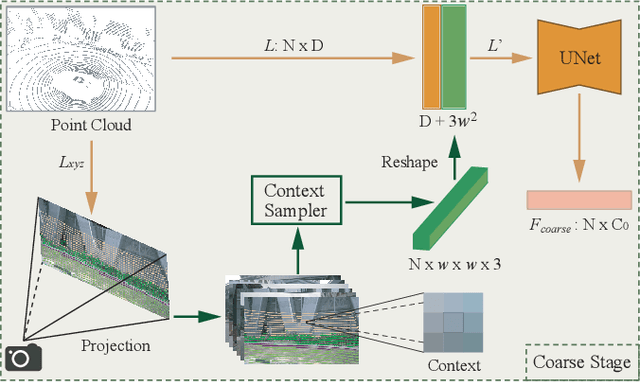
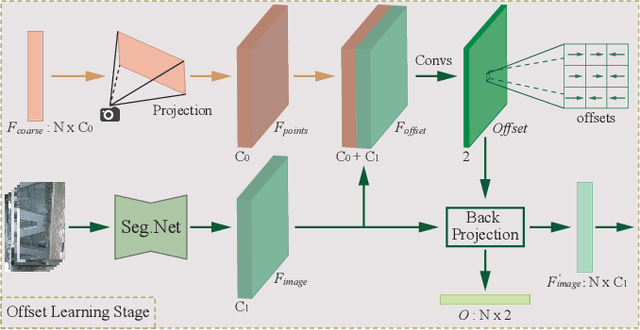
Camera and 3D LiDAR sensors have become indispensable devices in modern autonomous driving vehicles, where the camera provides the fine-grained texture, color information in 2D space and LiDAR captures more precise and farther-away distance measurements of the surrounding environments. The complementary information from these two sensors makes the two-modality fusion be a desired option. However, two major issues of the fusion between camera and LiDAR hinder its performance, \ie, how to effectively fuse these two modalities and how to precisely align them (suffering from the weak spatiotemporal synchronization problem). In this paper, we propose a coarse-to-fine LiDAR and camera fusion-based network (termed as LIF-Seg) for LiDAR segmentation. For the first issue, unlike these previous works fusing the point cloud and image information in a one-to-one manner, the proposed method fully utilizes the contextual information of images and introduces a simple but effective early-fusion strategy. Second, due to the weak spatiotemporal synchronization problem, an offset rectification approach is designed to align these two-modality features. The cooperation of these two components leads to the success of the effective camera-LiDAR fusion. Experimental results on the nuScenes dataset show the superiority of the proposed LIF-Seg over existing methods with a large margin. Ablation studies and analyses demonstrate that our proposed LIF-Seg can effectively tackle the weak spatiotemporal synchronization problem.