 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTP: Attention-Debiased Token Pruning for Video Large Language Models
May 26, 2025Video Large Language Models (Video LLMs) have achieved remarkable results in video understanding tasks. However, they often suffer from heavy computational overhead due to the large number of visual tokens generated from multiple video frames. Existing visual token compression methods often rely on attention scores from language models as guidance. However, these scores exhibit inherent biases: global bias reflects a tendency to focus on the two ends of the visual token sequence, while local bias leads to an over-concentration on the same spatial positions across different frames. To address the issue of attention bias, we propose $\textbf{A}$ttention-$\textbf{D}$ebi$\textbf{a}$sed $\textbf{T}$oken $\textbf{P}$runing for Video Large Language Models ($\textbf{AdaTP}$), a novel token pruning pipeline for Video LLMs. AdaTP integrates two dedicated debiasing modules into the pipeline, targeting global attention bias and local attention bias, respectively. Without the need for additional training, our method significantly reduces the computational overhead of Video LLMs while retaining the performance of vanilla models. Extensive evaluation shows that AdaTP achieves state-of-the-art performance in various commonly used video understanding benchmarks. In particular, on LLaVA-OneVision-7B, AdaTP maintains performance without degradation while using only up to $27.3\%$ FLOPs compared to the vanilla model. Our code will be released soon.
MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research
May 26, 2025Recent advancements in AI agents have demonstrated their growing potential to drive and support scientific discovery. In this work, we introduce MLR-Bench, a comprehensive benchmark for evaluating AI agents on open-ended machine learning research. MLR-Bench includes three key components: (1) 201 research tasks sourced from NeurIPS, ICLR, and ICML workshops covering diverse ML topics; (2) MLR-Judge, an automated evaluation framework combining LLM-based reviewers with carefully designed review rubrics to assess research quality; and (3) MLR-Agent, a modular agent scaffold capable of completing research tasks through four stages: idea generation, proposal formulation, experimentation, and paper writing. Our framework supports both stepwise assessment across these distinct research stages, and end-to-end evaluation of the final research paper. We then use MLR-Bench to evaluate six frontier LLMs and an advanced coding agent, finding that while LLMs are effective at generating coherent ideas and well-structured papers, current coding agents frequently (e.g., in 80% of the cases) produce fabricated or invalidated experimental results--posing a major barrier to scientific reliability. We validate MLR-Judge through human evaluation, showing high agreement with expert reviewers, supporting its potential as a scalable tool for research evaluation. We open-source MLR-Bench to help the community benchmark, diagnose, and improve AI research agents toward trustworthy and transparent scientific discovery.
Fast Quiet-STaR: Thinking Without Thought Tokens
May 23, 2025Large Language Models (LLMs) have achieved impressive performance across a range of natural language processing tasks. However, recent advances demonstrate that further gains particularly in complex reasoning tasks require more than merely scaling up model sizes or training data. One promising direction is to enable models to think during the reasoning process. Recently, Quiet STaR significantly improves reasoning by generating token-level thought traces, but incurs substantial inference overhead. In this work, we propose Fast Quiet STaR, a more efficient reasoning framework that preserves the benefits of token-level reasoning while reducing computational cost. Our method introduces a curriculum learning based training strategy that gradually reduces the number of thought tokens, enabling the model to internalize more abstract and concise reasoning processes. We further extend this approach to the standard Next Token Prediction (NTP) setting through reinforcement learning-based fine-tuning, resulting in Fast Quiet-STaR NTP, which eliminates the need for explicit thought token generation during inference. Experiments on four benchmark datasets with Mistral 7B and Qwen2.5 7B demonstrate that Fast Quiet-STaR consistently outperforms Quiet-STaR in terms of average accuracy under the same inference time budget. Notably, Fast Quiet-STaR NTP achieves an average accuracy improvement of 9\% on Mistral 7B and 5.7\% on Qwen2.5 7B, while maintaining the same inference latency. Our code will be available at https://github.com/huangwei200012/Fast-Quiet-STaR.
RIS Beam Calibration for ISAC Systems: Modeling and Performance Analysis
May 21, 2025High-accuracy localization is a key enabler for integrated sensing and communication (ISAC), playing an essential role in various applications such as autonomous driving. Antenna arrays and reconfigurable intelligent surface (RIS) are incorporated into these systems to achieve high angular resolution, assisting in the localization process. However, array and RIS beam patterns in practice often deviate from the idealized models used for algorithm design, leading to significant degradation in positioning accuracy. This mismatch highlights the need for beam calibration to bridge the gap between theoretical models and real-world hardware behavior. In this paper, we present and analyze three beam models considering several key non-idealities such as mutual coupling, non-ideal codebook, and measurement uncertainties. Based on the models, we then develop calibration algorithms to estimate the model parameters that can be used for future localization tasks. This work evaluates the effectiveness of the beam models and the calibration algorithms using both theoretical bounds and real-world beam pattern data from an RIS prototype. The simulation results show that the model incorporating combined impacts can accurately reconstruct measured beam patterns. This highlights the necessity of realistic beam modeling and calibration to achieve high-accuracy localization.
Near-Field RIS-Assisted Localization Under Mutual Coupling
May 20, 2025



Reconfigurable intelligent surfaces (RISs) have the potential to significantly enhance the performance of integrated sensing and communication (ISAC) systems, particularly in line-of-sight (LoS) blockage scenarios. However, as larger RISs are integrated into ISAC systems, mutual coupling (MC) effects between RIS elements become more pronounced, leading to a substantial degradation in performance, especially for localization applications. In this paper, we first conduct a misspecified and standard Cram\'er-Rao bound analysis to quantify the impact of MC on localization performance, demonstrating severe degradations in accuracy, especially when MC is ignored. Building on this, we propose a novel joint user equipment localization and RIS MC parameter estimation (JLMC) method in near-field wireless systems. Our two-stage MC-aware approach outperforms classical methods that neglect MC, significantly improving localization accuracy and overall system performance. Simulation results validate the effectiveness and advantages of the proposed method in realistic scenarios.
* 6 pages, 4 figures, IEEE ICC 2025 4th Workshop on Synergies of Communication, Localization, and Sensing towards 6G
Cross-layer Integrated Sensing and Communication: A Joint Industrial and Academic Perspective
May 16, 2025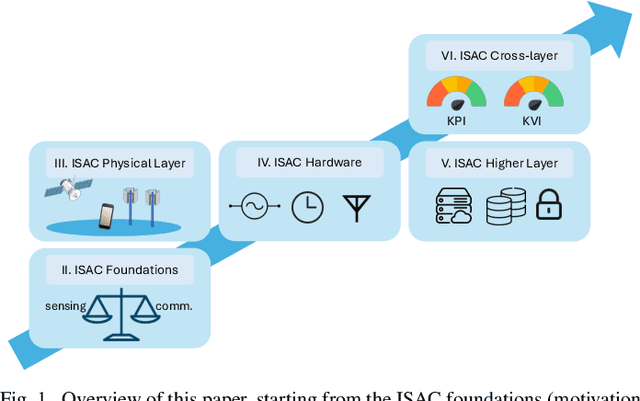



Integrated sensing and communication (ISAC) enables radio systems to simultaneously sense and communicate with their environment. This paper, developed within the Hexa-X-II project funded by the European Union, presents a comprehensive cross-layer vision for ISAC in 6G networks, integrating insights from physical-layer design, hardware architectures, AI-driven intelligence, and protocol-level innovations. We begin by revisiting the foundational principles of ISAC, highlighting synergies and trade-offs between sensing and communication across different integration levels. Enabling technologies, such as multiband operation, massive and distributed MIMO, non-terrestrial networks, reconfigurable intelligent surfaces, and machine learning, are analyzed in conjunction with hardware considerations including waveform design, synchronization, and full-duplex operation. To bridge implementation and system-level evaluation, we introduce a quantitative cross-layer framework linking design parameters to key performance and value indicators. By synthesizing perspectives from both academia and industry, this paper outlines how deeply integrated ISAC can transform 6G into a programmable and context-aware platform supporting applications from reliable wireless access to autonomous mobility and digital twinning.
Large Wireless Localization Model (LWLM): A Foundation Model for Positioning in 6G Networks
May 15, 2025Accurate and robust localization is a critical enabler for emerging 5G and 6G applications, including autonomous driving, extended reality (XR), and smart manufacturing. While data-driven approaches have shown promise, most existing models require large amounts of labeled data and struggle to generalize across deployment scenarios and wireless configurations. To address these limitations, we propose a foundation-model-based solution tailored for wireless localization. We first analyze how different self-supervised learning (SSL) tasks acquire general-purpose and task-specific semantic features based on information bottleneck (IB) theory. Building on this foundation, we design a pretraining methodology for the proposed Large Wireless Localization Model (LWLM). Specifically, we propose an SSL framework that jointly optimizes three complementary objectives: (i) spatial-frequency masked channel modeling (SF-MCM), (ii) domain-transformation invariance (DTI), and (iii) position-invariant contrastive learning (PICL). These objectives jointly capture the underlying semantics of wireless channel from multiple perspectives. We further design lightweight decoders for key downstream tasks, including time-of-arrival (ToA) estimation, angle-of-arrival (AoA) estimation, single base station (BS) localization, and multiple BS localization. Comprehensive experimental results confirm that LWLM consistently surpasses both model-based and supervised learning baselines across all localization tasks. In particular, LWLM achieves 26.0%--87.5% improvement over transformer models without pretraining, and exhibits strong generalization under label-limited fine-tuning and unseen BS configurations, confirming its potential as a foundation model for wireless localization.
Pilot-Based End-to-End Radio Positioning and Mapping for ISAC: Beyond Point-Based Landmarks
May 12, 2025



Integrated sensing and communication enables simultaneous communication and sensing tasks, including precise radio positioning and mapping, essential for future 6G networks. Current methods typically model environmental landmarks as isolated incidence points or small reflection areas, lacking detailed attributes essential for advanced environmental interpretation. This paper addresses these limitations by developing an end-to-end cooperative uplink framework involving multiple base stations and users. Our method uniquely estimates extended landmark objects and incorporates obstruction-based outlier removal to mitigate multi-bounce signal effects. Validation using realistic ray-tracing data demonstrates substantial improvements in the richness of the estimated environmental map.
PREMISE: Matching-based Prediction for Accurate Review Recommendation
May 02, 2025



We present PREMISE (PREdict with Matching ScorEs), a new architecture for the matching-based learning in the multimodal fields for the multimodal review helpfulness (MRHP) task. Distinct to previous fusion-based methods which obtains multimodal representations via cross-modal attention for downstream tasks, PREMISE computes the multi-scale and multi-field representations, filters duplicated semantics, and then obtained a set of matching scores as feature vectors for the downstream recommendation task. This new architecture significantly boosts the performance for such multimodal tasks whose context matching content are highly correlated to the targets of that task, compared to the state-of-the-art fusion-based methods. Experimental results on two publicly available datasets show that PREMISE achieves promising performance with less computational cost.
FigBO: A Generalized Acquisition Function Framework with Look-Ahead Capability for Bayesian Optimization
Apr 28, 2025Bayesian optimization is a powerful technique for optimizing expensive-to-evaluate black-box functions, consisting of two main components: a surrogate model and an acquisition function. In recent years, myopic acquisition functions have been widely adopted for their simplicity and effectiveness. However, their lack of look-ahead capability limits their performance. To address this limitation, we propose FigBO, a generalized acquisition function that incorporates the future impact of candidate points on global information gain. FigBO is a plug-and-play method that can integrate seamlessly with most existing myopic acquisition functions. Theoretically, we analyze the regret bound and convergence rate of FigBO when combined with the myopic base acquisition function expected improvement (EI), comparing them to those of standard EI. Empirically, extensive experimental results across diverse tasks demonstrate that FigBO achieves state-of-the-art performance and significantly faster convergence compared to existing methods.