 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models as Masked Autoencoders
Apr 06, 2023



There has been a longstanding belief that generation can facilitate a true understanding of visual data. In line with this, we revisit generatively pre-training visual representations in light of recent interest in denoising diffusion models. While directly pre-training with diffusion models does not produce strong representations, we condition diffusion models on masked input and formulate diffusion models as masked autoencoders (DiffMAE). Our approach is capable of (i) serving as a strong initialization for downstream recognition tasks, (ii) conducting high-quality image inpainting, and (iii) being effortlessly extended to video where it produces state-of-the-art classification accuracy. We further perform a comprehensive study on the pros and cons of design choices and build connections between diffusion models and masked autoencoders.
Adapting a Language Model While Preserving its General Knowledge
Jan 21, 2023Domain-adaptive pre-training (or DA-training for short), also known as post-training, aims to train a pre-trained general-purpose language model (LM) using an unlabeled corpus of a particular domain to adapt the LM so that end-tasks in the domain can give improved performances. However, existing DA-training methods are in some sense blind as they do not explicitly identify what knowledge in the LM should be preserved and what should be changed by the domain corpus. This paper shows that the existing methods are suboptimal and proposes a novel method to perform a more informed adaptation of the knowledge in the LM by (1) soft-masking the attention heads based on their importance to best preserve the general knowledge in the LM and (2) contrasting the representations of the general and the full (both general and domain knowledge) to learn an integrated representation with both general and domain-specific knowledge. Experimental results will demonstrate the effectiveness of the proposed approach.
CiT: Curation in Training for Effective Vision-Language Data
Jan 05, 2023



Large vision-language models are generally applicable to many downstream tasks, but come at an exorbitant training cost that only large institutions can afford. This paper trades generality for efficiency and presents Curation in Training (CiT), a simple and efficient vision-text learning algorithm that couples a data objective into training. CiT automatically yields quality data to speed-up contrastive image-text training and alleviates the need for an offline data filtering pipeline, allowing broad data sources (including raw image-text pairs from the web). CiT contains two loops: an outer loop curating the training data and an inner loop consuming the curated training data. The text encoder connects the two loops. Given metadata for tasks of interest, e.g., class names, and a large pool of image-text pairs, CiT alternatively selects relevant training data from the pool by measuring the similarity of their text embeddings and embeddings of the metadata. In our experiments, we observe that CiT can speed up training by over an order of magnitude, especially if the raw data size is large.
MAViL: Masked Audio-Video Learners
Dec 15, 2022



We present Masked Audio-Video Learners (MAViL) to train audio-visual representations. Our approach learns with three complementary forms of self-supervision: (1) reconstruction of masked audio and video input data, (2) intra- and inter-modal contrastive learning with masking, and (3) self-training by reconstructing joint audio-video contextualized features learned from the first two objectives. Pre-training with MAViL not only enables the model to perform well in audio-visual classification and retrieval tasks but also improves representations of each modality in isolation, without using information from the other modality for fine-tuning or inference. Empirically, MAViL sets a new state-of-the-art on AudioSet (53.1 mAP) and VGGSound (67.1% accuracy). For the first time, a self-supervised audio-visual model outperforms ones that use external supervision on these benchmarks. Code will be available soon.
Continual Training of Language Models for Few-Shot Learning
Oct 11, 2022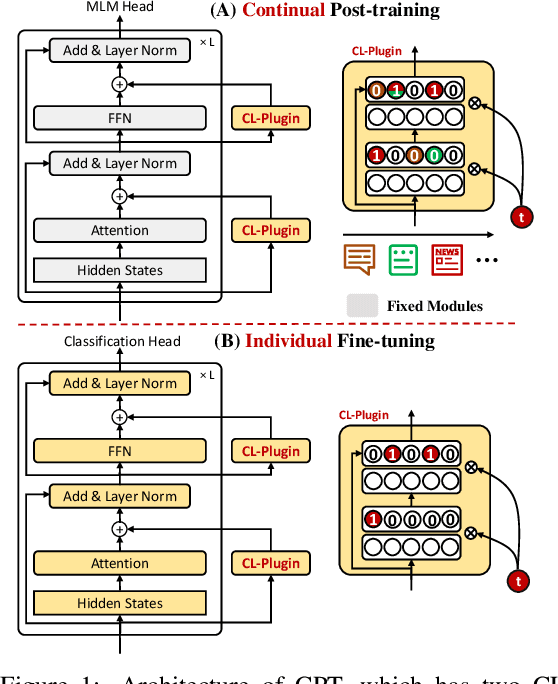
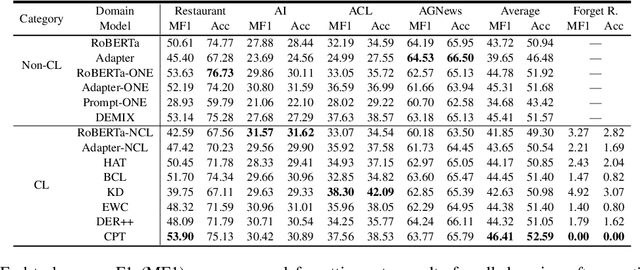
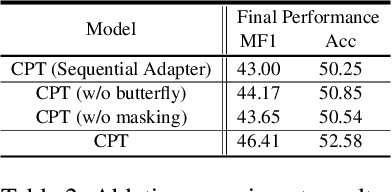
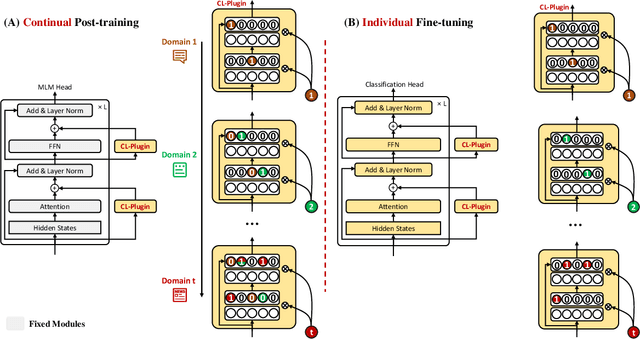
Recent work on applying large language models (LMs) achieves impressive performance in many NLP applications. Adapting or posttraining an LM using an unlabeled domain corpus can produce even better performance for end-tasks in the domain. This paper proposes the problem of continually extending an LM by incrementally post-train the LM with a sequence of unlabeled domain corpora to expand its knowledge without forgetting its previous skills. The goal is to improve the few-shot end-task learning in these domains. The resulting system is called CPT (Continual PostTraining), which to our knowledge, is the first continual post-training system. Experimental results verify its effectiveness.
Masked Autoencoders that Listen
Jul 13, 2022
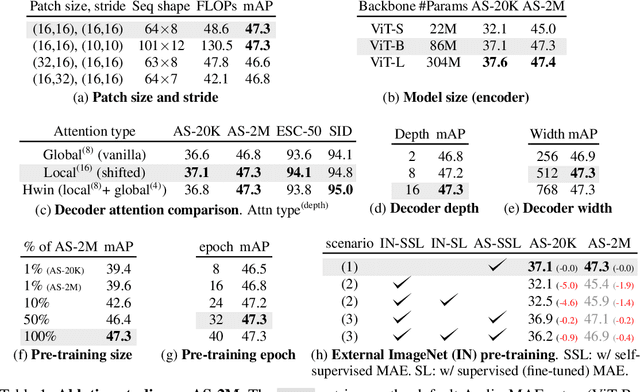

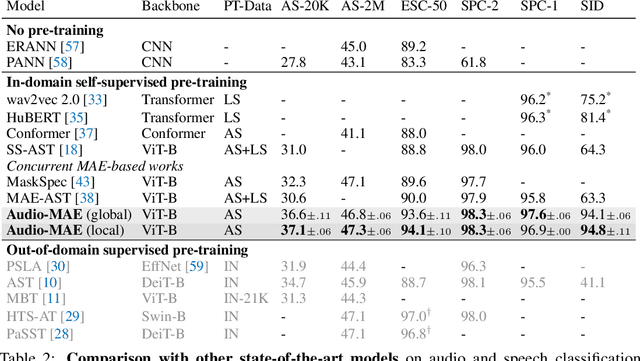
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
Zero-Shot Aspect-Based Sentiment Analysis
Feb 15, 2022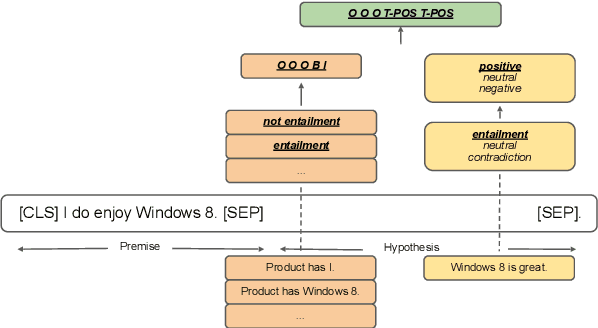


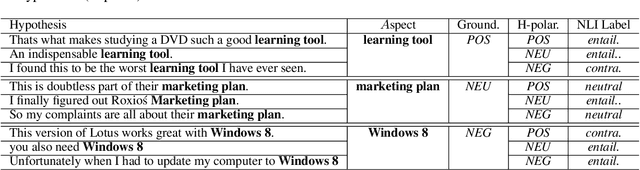
Aspect-based sentiment analysis (ABSA) typically requires in-domain annotated data for supervised training/fine-tuning. It is a big challenge to scale ABSA to a large number of new domains. This paper aims to train a unified model that can perform zero-shot ABSA without using any annotated data for a new domain. We propose a method called contrastive post-training on review Natural Language Inference (CORN). Later ABSA tasks can be cast into NLI for zero-shot transfer. We evaluate CORN on ABSA tasks, ranging from aspect extraction (AE), aspect sentiment classification (ASC), to end-to-end aspect-based sentiment analysis (E2E ABSA), which show ABSA can be conducted without any human annotated ABSA data.
CM3: A Causal Masked Multimodal Model of the Internet
Jan 19, 2022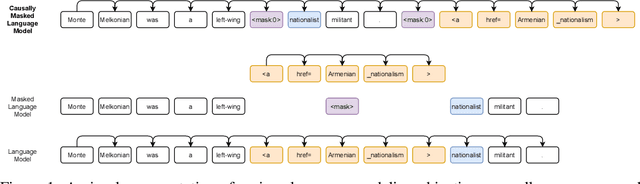
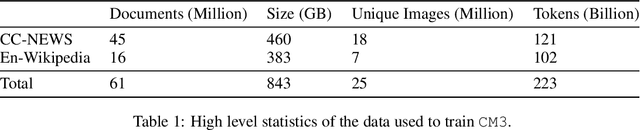
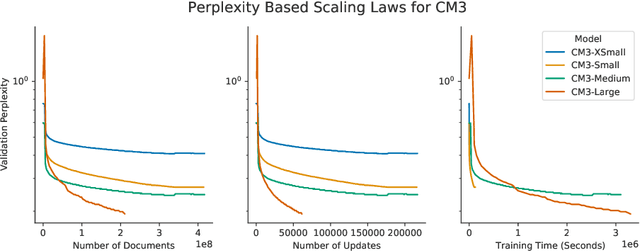
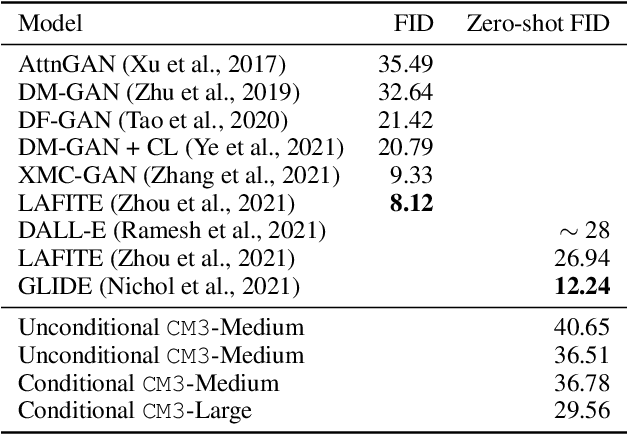
We introduce CM3, a family of causally masked generative models trained over a large corpus of structured multi-modal documents that can contain both text and image tokens. Our new causally masked approach generates tokens left to right while also masking out a small number of long token spans that are generated at the end of the string, instead of their original positions. The casual masking object provides a type of hybrid of the more common causal and masked language models, by enabling full generative modeling while also providing bidirectional context when generating the masked spans. We train causally masked language-image models on large-scale web and Wikipedia articles, where each document contains all of the text, hypertext markup, hyperlinks, and image tokens (from a VQVAE-GAN), provided in the order they appear in the original HTML source (before masking). The resulting CM3 models can generate rich structured, multi-modal outputs while conditioning on arbitrary masked document contexts, and thereby implicitly learn a wide range of text, image, and cross modal tasks. They can be prompted to recover, in a zero-shot fashion, the functionality of models such as DALL-E, GENRE, and HTLM. We set the new state-of-the-art in zero-shot summarization, entity linking, and entity disambiguation while maintaining competitive performance in the fine-tuning setting. We can generate images unconditionally, conditioned on text (like DALL-E) and do captioning all in a zero-shot setting with a single model.
Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks
Dec 06, 2021
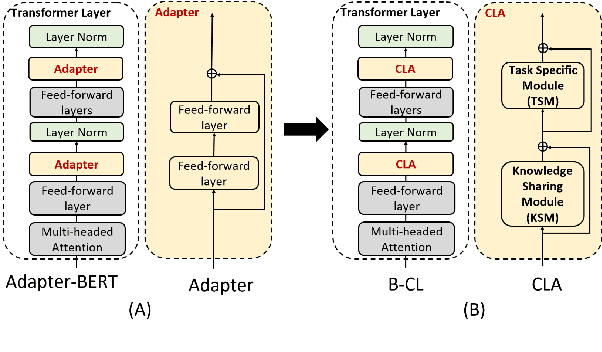
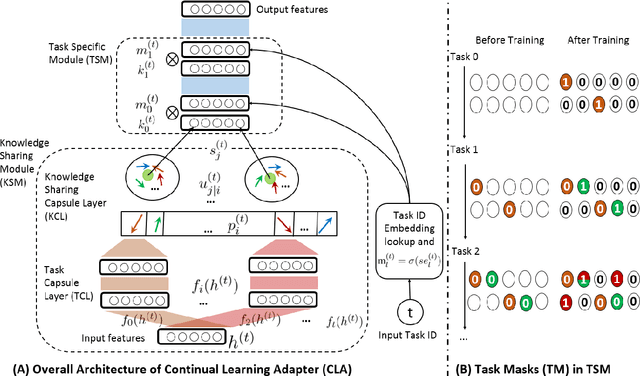
This paper studies continual learning (CL) of a sequence of aspect sentiment classification (ASC) tasks. Although some CL techniques have been proposed for document sentiment classification, we are not aware of any CL work on ASC. A CL system that incrementally learns a sequence of ASC tasks should address the following two issues: (1) transfer knowledge learned from previous tasks to the new task to help it learn a better model, and (2) maintain the performance of the models for previous tasks so that they are not forgotten. This paper proposes a novel capsule network based model called B-CL to address these issues. B-CL markedly improves the ASC performance on both the new task and the old tasks via forward and backward knowledge transfer. The effectiveness of B-CL is demonstrated through extensive experiments.
* arXiv admin note: text overlap with arXiv:2112.02714, arXiv:2112.02706
CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks
Dec 05, 2021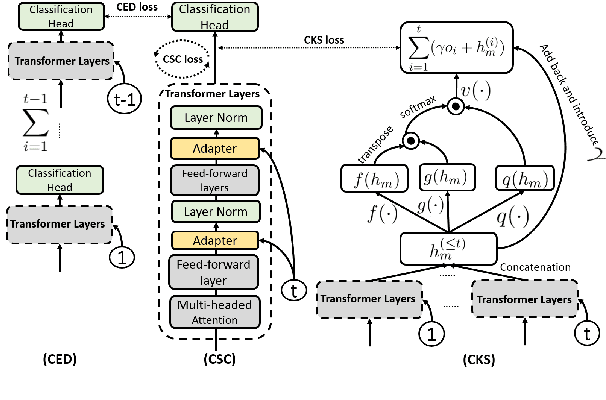
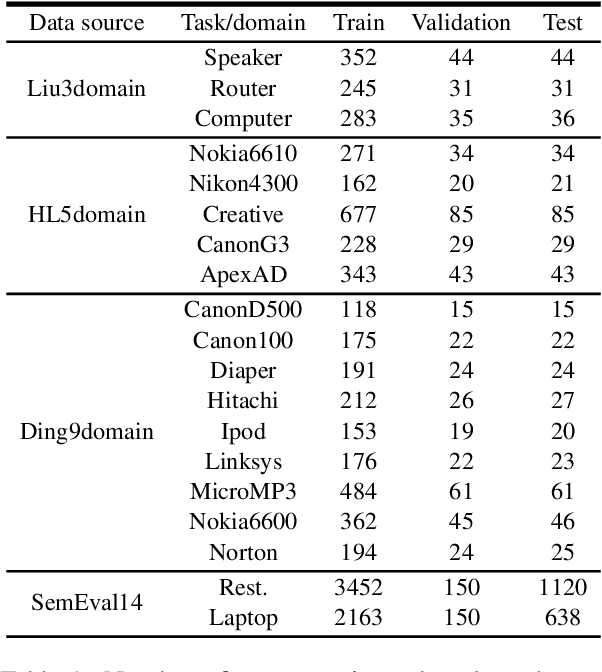
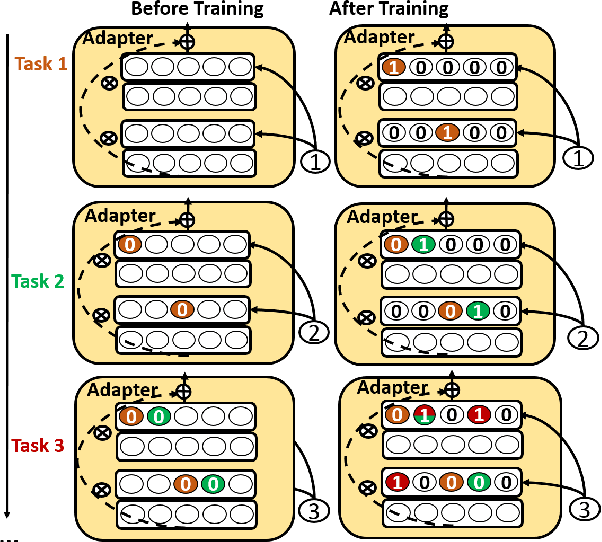

This paper studies continual learning (CL) of a sequence of aspect sentiment classification(ASC) tasks in a particular CL setting called domain incremental learning (DIL). Each task is from a different domain or product. The DIL setting is particularly suited to ASC because in testing the system needs not know the task/domain to which the test data belongs. To our knowledge, this setting has not been studied before for ASC. This paper proposes a novel model called CLASSIC. The key novelty is a contrastive continual learning method that enables both knowledge transfer across tasks and knowledge distillation from old tasks to the new task, which eliminates the need for task ids in testing. Experimental results show the high effectiveness of CLASSIC.