 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIA-MVS: Instance-Focused Adaptive Depth Sampling for Multi-View Stereo
May 19, 2025Multi-view stereo (MVS) models based on progressive depth hypothesis narrowing have made remarkable advancements. However, existing methods haven't fully utilized the potential that the depth coverage of individual instances is smaller than that of the entire scene, which restricts further improvements in depth estimation precision. Moreover, inevitable deviations in the initial stage accumulate as the process advances. In this paper, we propose Instance-Adaptive MVS (IA-MVS). It enhances the precision of depth estimation by narrowing the depth hypothesis range and conducting refinement on each instance. Additionally, a filtering mechanism based on intra-instance depth continuity priors is incorporated to boost robustness. Furthermore, recognizing that existing confidence estimation can degrade IA-MVS performance on point clouds. We have developed a detailed mathematical model for confidence estimation based on conditional probability. The proposed method can be widely applied in models based on MVSNet without imposing extra training burdens. Our method achieves state-of-the-art performance on the DTU benchmark. The source code is available at https://github.com/KevinWang73106/IA-MVS.
Information Entropy Invariance: Enhancing Length Extrapolation in Attention Mechanisms
Jan 15, 2025Improving the length extrapolation capabilities of Large Language Models (LLMs) remains a critical challenge in natural language processing. Many recent efforts have focused on modifying the scaled dot-product attention mechanism, and often introduce scaled temperatures without rigorous theoretical justification. To fill this gap, we introduce a novel approach based on information entropy invariance. We propose two new scaled temperatures to enhance length extrapolation. First, a training-free method InfoScale is designed for dot-product attention, and preserves focus on original tokens during length extrapolation by ensuring information entropy remains consistent. Second, we theoretically analyze the impact of scaling (CosScale) on cosine attention. Experimental data demonstrates that combining InfoScale and CosScale achieves state-of-the-art performance on the GAU-{\alpha} model with a context window extended to 64 times the training length, and outperforms seven existing methods. Our analysis reveals that significantly increasing CosScale approximates windowed attention, and highlights the significance of attention score dilution as a key challenge in long-range context handling. The code and data are available at https://github.com/HT-NEKO/InfoScale.
Limited Gradient Descent: Learning With Noisy Labels
Dec 06, 2018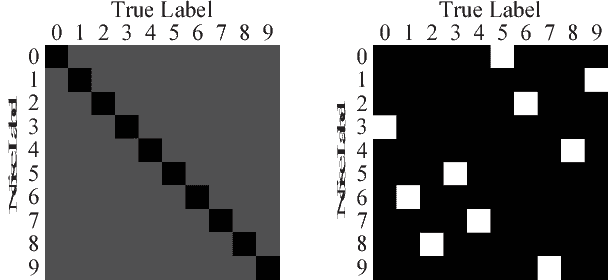

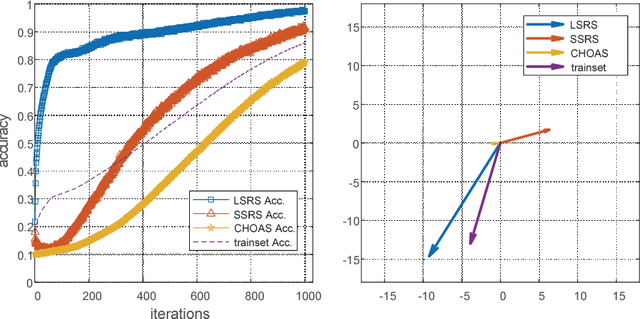
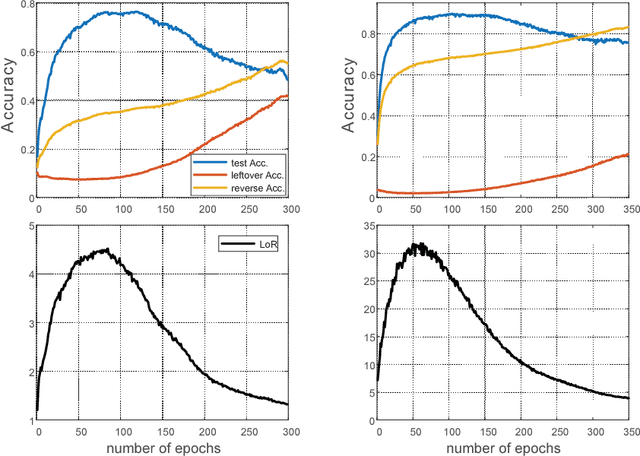
Label noise may handicap the generalization of classifiers, and the effective learning of the main pattern from samples with noisy labels is an important issue. Recent studies have shown that deep neural networks tend to prioritize the learning of simple patterns over the memorization of noise patterns. This suggests the need for a method to search for the best generalization that learns the main pattern until noise begins to be memorized. An intuitive idea is to use a supervised approach to find the stop timing of learning by, for example, employing a clean verification set. In practice, however, a clean verification set is sometimes difficult to obtain. To solve this problem, we propose an unsupervised method called limited gradient descent to estimate the best stop timing. We modified the labels of a few samples in a noisy dataset to be almost false labels, creating a reverse pattern. By monitoring the learning progresses of the noisy samples and the reverse samples, we could determine the stop timing of learning. In this paper, we also provide some sufficient conditions on learning with noisy labels. Experimental results on CIFAR-10 demonstrate that our approach has a similar generalization performance to supervised methods. For uncomplicated datasets, such as MNIST, we add a relabeling strategy to further improve generalization and achieve state-of-the-art performance.