 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Adaptive RGBT Tracking with Modality Prompt
Jan 02, 2024RGBT tracking has been widely used in various fields such as robotics, surveillance processing, and autonomous driving. Existing RGBT trackers fully explore the spatial information between the template and the search region and locate the target based on the appearance matching results. However, these RGBT trackers have very limited exploitation of temporal information, either ignoring temporal information or exploiting it through online sampling and training. The former struggles to cope with the object state changes, while the latter neglects the correlation between spatial and temporal information. To alleviate these limitations, we propose a novel Temporal Adaptive RGBT Tracking framework, named as TATrack. TATrack has a spatio-temporal two-stream structure and captures temporal information by an online updated template, where the two-stream structure refers to the multi-modal feature extraction and cross-modal interaction for the initial template and the online update template respectively. TATrack contributes to comprehensively exploit spatio-temporal information and multi-modal information for target localization. In addition, we design a spatio-temporal interaction (STI) mechanism that bridges two branches and enables cross-modal interaction to span longer time scales. Extensive experiments on three popular RGBT tracking benchmarks show that our method achieves state-of-the-art performance, while running at real-time speed.
BitNet: Scaling 1-bit Transformers for Large Language Models
Oct 17, 2023The increasing size of large language models has posed challenges for deployment and raised concerns about environmental impact due to high energy consumption. In this work, we introduce BitNet, a scalable and stable 1-bit Transformer architecture designed for large language models. Specifically, we introduce BitLinear as a drop-in replacement of the nn.Linear layer in order to train 1-bit weights from scratch. Experimental results on language modeling show that BitNet achieves competitive performance while substantially reducing memory footprint and energy consumption, compared to state-of-the-art 8-bit quantization methods and FP16 Transformer baselines. Furthermore, BitNet exhibits a scaling law akin to full-precision Transformers, suggesting its potential for effective scaling to even larger language models while maintaining efficiency and performance benefits.
PREFER: Prompt Ensemble Learning via Feedback-Reflect-Refine
Aug 23, 2023As an effective tool for eliciting the power of Large Language Models (LLMs), prompting has recently demonstrated unprecedented abilities across a variety of complex tasks. To further improve the performance, prompt ensemble has attracted substantial interest for tackling the hallucination and instability of LLMs. However, existing methods usually adopt a two-stage paradigm, which requires a pre-prepared set of prompts with substantial manual effort, and is unable to perform directed optimization for different weak learners. In this paper, we propose a simple, universal, and automatic method named PREFER (Pompt Ensemble learning via Feedback-Reflect-Refine) to address the stated limitations. Specifically, given the fact that weak learners are supposed to focus on hard examples during boosting, PREFER builds a feedback mechanism for reflecting on the inadequacies of existing weak learners. Based on this, the LLM is required to automatically synthesize new prompts for iterative refinement. Moreover, to enhance stability of the prompt effect evaluation, we propose a novel prompt bagging method involving forward and backward thinking, which is superior to majority voting and is beneficial for both feedback and weight calculation in boosting. Extensive experiments demonstrate that our PREFER achieves state-of-the-art performance in multiple types of tasks by a significant margin. We have made our code publicly available.
Hyperspectral Target Detection Based on Low-Rank Background Subspace Learning and Graph Laplacian Regularization
Jun 01, 2023Hyperspectral target detection is good at finding dim and small objects based on spectral characteristics. However, existing representation-based methods are hindered by the problem of the unknown background dictionary and insufficient utilization of spatial information. To address these issues, this paper proposes an efficient optimizing approach based on low-rank representation (LRR) and graph Laplacian regularization (GLR). Firstly, to obtain a complete and pure background dictionary, we propose a LRR-based background subspace learning method by jointly mining the low-dimensional structure of all pixels. Secondly, to fully exploit local spatial relationships and capture the underlying geometric structure, a local region-based GLR is employed to estimate the coefficients. Finally, the desired detection map is generated by computing the ratio of representation errors from binary hypothesis testing. The experiments conducted on two benchmark datasets validate the effectiveness and superiority of the approach. For reproduction, the accompanying code is available at https://github.com/shendb2022/LRBSL-GLR.
The state-of-the-art 3D anisotropic intracranial hemorrhage segmentation on non-contrast head CT: The INSTANCE challenge
Jan 12, 2023Automatic intracranial hemorrhage segmentation in 3D non-contrast head CT (NCCT) scans is significant in clinical practice. Existing hemorrhage segmentation methods usually ignores the anisotropic nature of the NCCT, and are evaluated on different in-house datasets with distinct metrics, making it highly challenging to improve segmentation performance and perform objective comparisons among different methods. The INSTANCE 2022 was a grand challenge held in conjunction with the 2022 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). It is intended to resolve the above-mentioned problems and promote the development of both intracranial hemorrhage segmentation and anisotropic data processing. The INSTANCE released a training set of 100 cases with ground-truth and a validation set with 30 cases without ground-truth labels that were available to the participants. A held-out testing set with 70 cases is utilized for the final evaluation and ranking. The methods from different participants are ranked based on four metrics, including Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), Relative Volume Difference (RVD) and Normalized Surface Dice (NSD). A total of 13 teams submitted distinct solutions to resolve the challenges, making several baseline models, pre-processing strategies and anisotropic data processing techniques available to future researchers. The winner method achieved an average DSC of 0.6925, demonstrating a significant growth over our proposed baseline method. To the best of our knowledge, the proposed INSTANCE challenge releases the first intracranial hemorrhage segmentation benchmark, and is also the first challenge that intended to resolve the anisotropic problem in 3D medical image segmentation, which provides new alternatives in these research fields.
TorchScale: Transformers at Scale
Nov 23, 2022Large Transformers have achieved state-of-the-art performance across many tasks. Most open-source libraries on scaling Transformers focus on improving training or inference with better parallelization. In this work, we present TorchScale, an open-source toolkit that allows researchers and developers to scale up Transformers efficiently and effectively. TorchScale has the implementation of several modeling techniques, which can improve modeling generality and capability, as well as training stability and efficiency. Experimental results on language modeling and neural machine translation demonstrate that TorchScale can successfully scale Transformers to different sizes without tears. The library is available at https://aka.ms/torchscale.
Foundation Transformers
Oct 19, 2022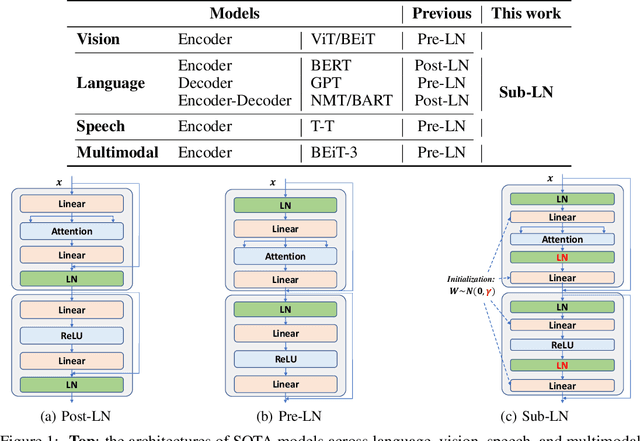
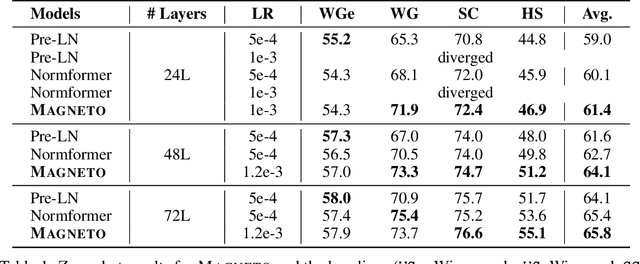
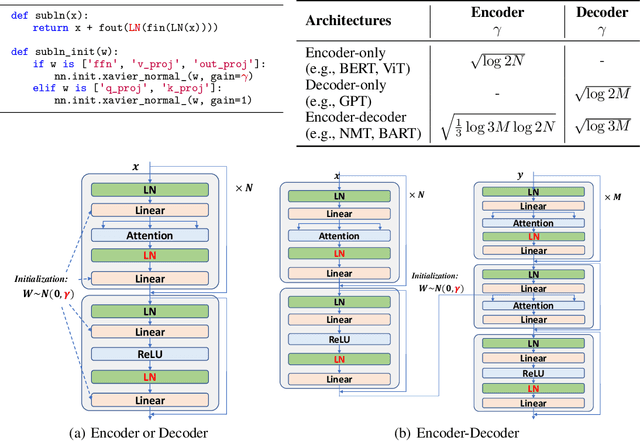
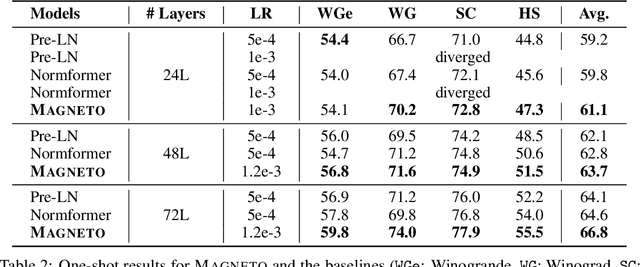
A big convergence of model architectures across language, vision, speech, and multimodal is emerging. However, under the same name "Transformers", the above areas use different implementations for better performance, e.g., Post-LayerNorm for BERT, and Pre-LayerNorm for GPT and vision Transformers. We call for the development of Foundation Transformer for true general-purpose modeling, which serves as a go-to architecture for various tasks and modalities with guaranteed training stability. In this work, we introduce a Transformer variant, named Magneto, to fulfill the goal. Specifically, we propose Sub-LayerNorm for good expressivity, and the initialization strategy theoretically derived from DeepNet for stable scaling up. Extensive experiments demonstrate its superior performance and better stability than the de facto Transformer variants designed for various applications, including language modeling (i.e., BERT, and GPT), machine translation, vision pretraining (i.e., BEiT), speech recognition, and multimodal pretraining (i.e., BEiT-3).
End-User Puppeteering of Expressive Movements
Jul 25, 2022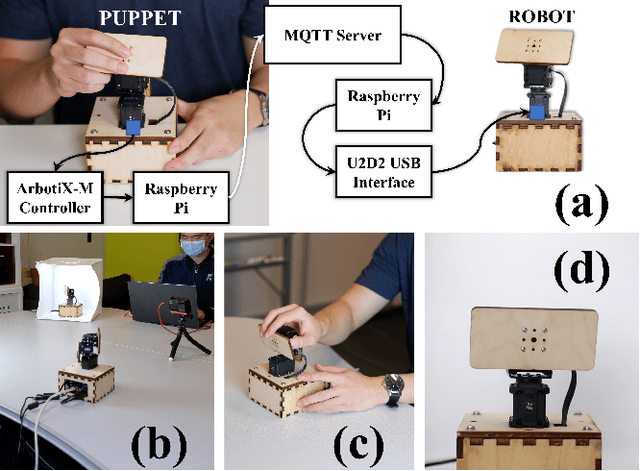
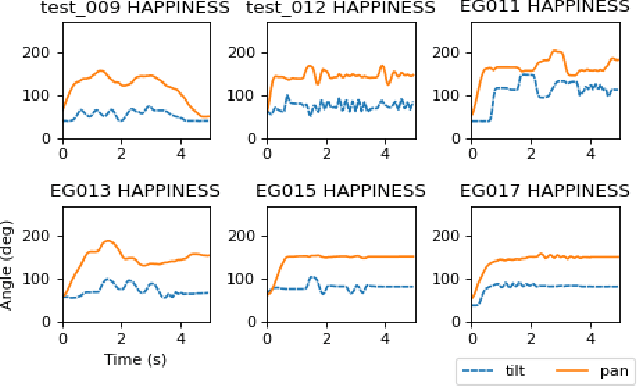
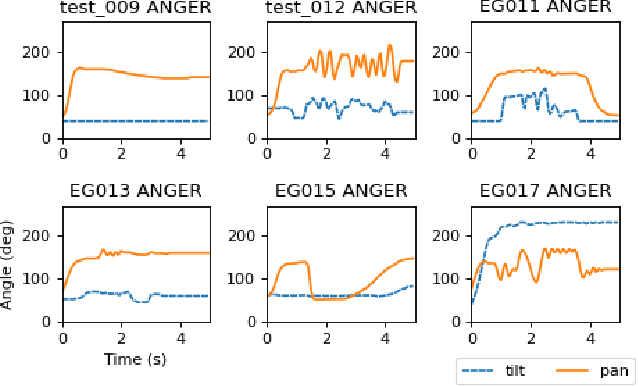
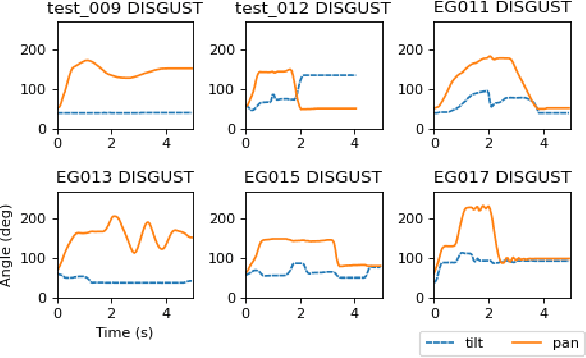
The end-user programming of social robot behavior is usually limited by a predefined set of movements. We are proposing a puppeteering robotic interface that provides a more intuitive method of programming robot expressive movements. As the user manipulates the puppet of a robot, the actual robot replicates the movements, providing real-time visual feedback. Through this proposed interface, even with limited training, a novice user can design and program expressive movements efficiently. We present our preliminary user study results in this extended abstract.
Cross-domain Few-shot Meta-learning Using Stacking
May 12, 2022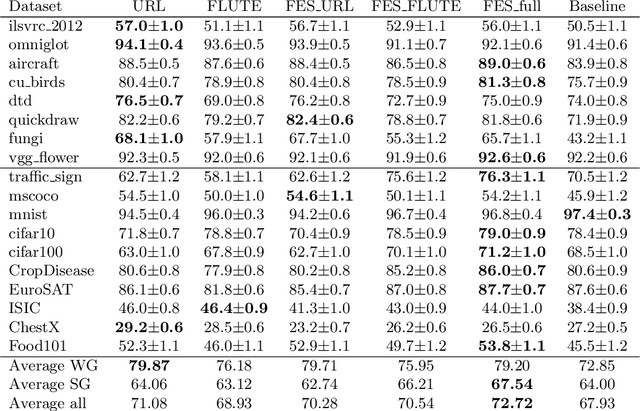
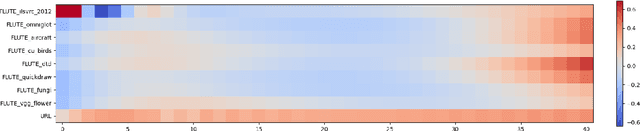
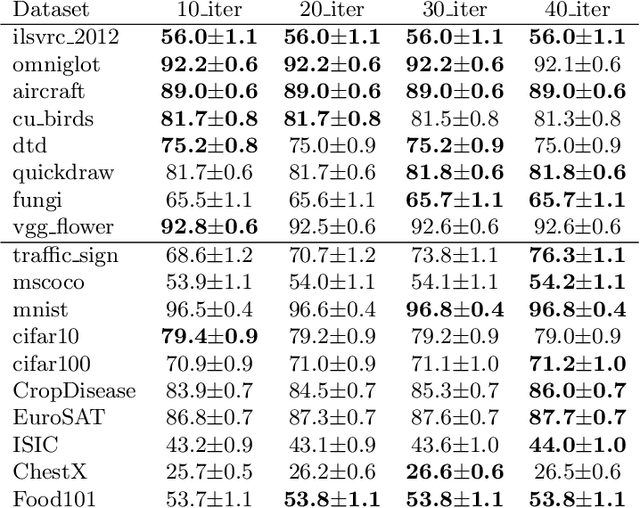
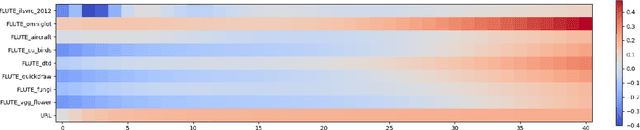
Cross-domain few-shot meta-learning (CDFSML) addresses learning problems where knowledge needs to be transferred from several source domains into an instance-scarce target domain with an explicitly different input distribution. Recently published CDFSML methods generally construct a "universal model" that combines knowledge of multiple source domains into one backbone feature extractor. This enables efficient inference but necessitates re-computation of the backbone whenever a new source domain is added. Moreover, state-of-the-art methods derive their universal model from a collection of backbones -- normally one for each source domain -- and the backbones may be constrained to have the same architecture as the universal model. We propose a CDFSML method that is inspired by the classic stacking approach to meta learning. It imposes no constraints on the backbones' architecture or feature shape and does not incur the computational overhead of (re-)computing a universal model. Given a target-domain task, it fine-tunes each backbone independently, uses cross-validation to extract meta training data from the task's instance-scarce support set, and learns a simple linear meta classifier from this data. We evaluate our stacking approach on the well-known Meta-Dataset benchmark, targeting image classification with convolutional neural networks, and show that it often yields substantially higher accuracy than competing methods.
DeepNet: Scaling Transformers to 1,000 Layers
Mar 01, 2022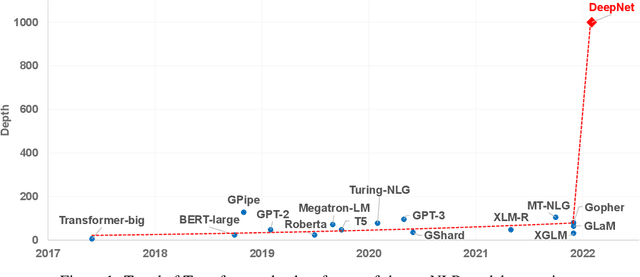
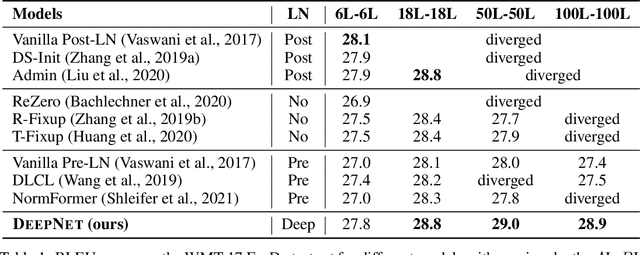

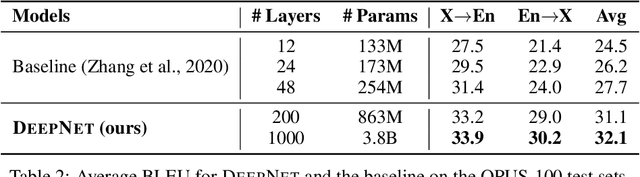
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection in Transformer, accompanying with theoretically derived initialization. In-depth theoretical analysis shows that model updates can be bounded in a stable way. The proposed method combines the best of two worlds, i.e., good performance of Post-LN and stable training of Pre-LN, making DeepNorm a preferred alternative. We successfully scale Transformers up to 1,000 layers (i.e., 2,500 attention and feed-forward network sublayers) without difficulty, which is one order of magnitude deeper than previous deep Transformers. Remarkably, on a multilingual benchmark with 7,482 translation directions, our 200-layer model with 3.2B parameters significantly outperforms the 48-layer state-of-the-art model with 12B parameters by 5 BLEU points, which indicates a promising scaling direction.