 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs
Feb 05, 2026Multimodal Large Language Models (MLLMs) have made remarkable progress in multimodal perception and reasoning by bridging vision and language. However, most existing MLLMs perform reasoning primarily with textual CoT, which limits their effectiveness on vision-intensive tasks. Recent approaches inject a fixed number of continuous hidden states as "visual thoughts" into the reasoning process and improve visual performance, but often at the cost of degraded text-based logical reasoning. We argue that the core limitation lies in a rigid, pre-defined reasoning pattern that cannot adaptively choose the most suitable thinking modality for different user queries. We introduce SwimBird, a reasoning-switchable MLLM that dynamically switches among three reasoning modes conditioned on the input: (1) text-only reasoning, (2) vision-only reasoning (continuous hidden states as visual thoughts), and (3) interleaved vision-text reasoning. To enable this capability, we adopt a hybrid autoregressive formulation that unifies next-token prediction for textual thoughts with next-embedding prediction for visual thoughts, and design a systematic reasoning-mode curation strategy to construct SwimBird-SFT-92K, a diverse supervised fine-tuning dataset covering all three reasoning patterns. By enabling flexible, query-adaptive mode selection, SwimBird preserves strong textual logic while substantially improving performance on vision-dense tasks. Experiments across diverse benchmarks covering textual reasoning and challenging visual understanding demonstrate that SwimBird achieves state-of-the-art results and robust gains over prior fixed-pattern multimodal reasoning methods.
CrossLMM: Decoupling Long Video Sequences from LMMs via Dual Cross-Attention Mechanisms
May 22, 2025The advent of Large Multimodal Models (LMMs) has significantly enhanced Large Language Models (LLMs) to process and interpret diverse data modalities (e.g., image and video). However, as input complexity increases, particularly with long video sequences, the number of required tokens has grown significantly, leading to quadratically computational costs. This has made the efficient compression of video tokens in LMMs, while maintaining performance integrity, a pressing research challenge. In this paper, we introduce CrossLMM, decoupling long video sequences from LMMs via a dual cross-attention mechanism, which substantially reduces visual token quantity with minimal performance degradation. Specifically, we first implement a significant token reduction from pretrained visual encoders through a pooling methodology. Then, within LLM layers, we employ a visual-to-visual cross-attention mechanism, wherein the pooled visual tokens function as queries against the original visual token set. This module enables more efficient token utilization while retaining fine-grained informational fidelity. In addition, we introduce a text-to-visual cross-attention mechanism, for which the text tokens are enhanced through interaction with the original visual tokens, enriching the visual comprehension of the text tokens. Comprehensive empirical evaluation demonstrates that our approach achieves comparable or superior performance across diverse video-based LMM benchmarks, despite utilizing substantially fewer computational resources.
Visual Perception by Large Language Model's Weights
May 30, 2024



Existing Multimodal Large Language Models (MLLMs) follow the paradigm that perceives visual information by aligning visual features with the input space of Large Language Models (LLMs), and concatenating visual tokens with text tokens to form a unified sequence input for LLMs. These methods demonstrate promising results on various vision-language tasks but are limited by the high computational effort due to the extended input sequence resulting from the involvement of visual tokens. In this paper, instead of input space alignment, we propose a novel parameter space alignment paradigm that represents visual information as model weights. For each input image, we use a vision encoder to extract visual features, convert features into perceptual weights, and merge the perceptual weights with LLM's weights. In this way, the input of LLM does not require visual tokens, which reduces the length of the input sequence and greatly improves efficiency. Following this paradigm, we propose VLoRA with the perceptual weights generator. The perceptual weights generator is designed to convert visual features to perceptual weights with low-rank property, exhibiting a form similar to LoRA. The experimental results show that our VLoRA achieves comparable performance on various benchmarks for MLLMs, while significantly reducing the computational costs for both training and inference. The code and models will be made open-source.
Multi-Modal Generative Embedding Model
May 29, 2024



Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.
Stare at What You See: Masked Image Modeling without Reconstruction
Nov 16, 2022



Masked Autoencoders (MAE) have been prevailing paradigms for large-scale vision representation pre-training. By reconstructing masked image patches from a small portion of visible image regions, MAE forces the model to infer semantic correlation within an image. Recently, some approaches apply semantic-rich teacher models to extract image features as the reconstruction target, leading to better performance. However, unlike the low-level features such as pixel values, we argue the features extracted by powerful teacher models already encode rich semantic correlation across regions in an intact image.This raises one question: is reconstruction necessary in Masked Image Modeling (MIM) with a teacher model? In this paper, we propose an efficient MIM paradigm named MaskAlign. MaskAlign simply learns the consistency of visible patch features extracted by the student model and intact image features extracted by the teacher model. To further advance the performance and tackle the problem of input inconsistency between the student and teacher model, we propose a Dynamic Alignment (DA) module to apply learnable alignment. Our experimental results demonstrate that masked modeling does not lose effectiveness even without reconstruction on masked regions. Combined with Dynamic Alignment, MaskAlign can achieve state-of-the-art performance with much higher efficiency. Code and models will be available at https://github.com/OpenPerceptionX/maskalign.
Long-Form Video-Language Pre-Training with Multimodal Temporal Contrastive Learning
Oct 12, 2022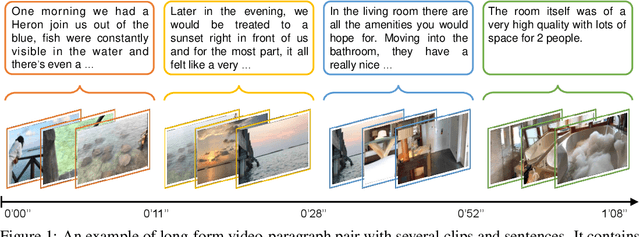
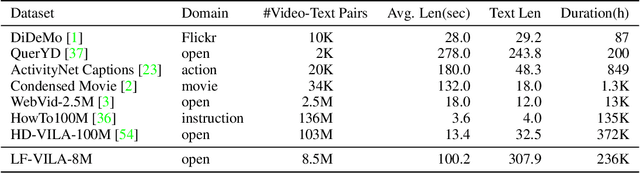
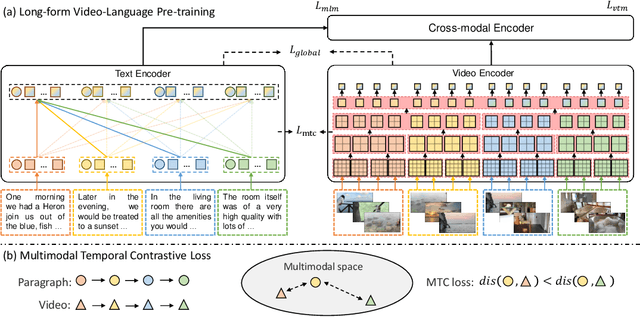
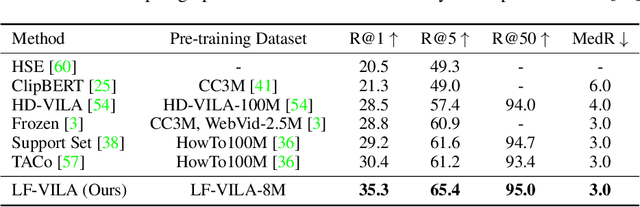
Large-scale video-language pre-training has shown significant improvement in video-language understanding tasks. Previous studies of video-language pretraining mainly focus on short-form videos (i.e., within 30 seconds) and sentences, leaving long-form video-language pre-training rarely explored. Directly learning representation from long-form videos and language may benefit many long-form video-language understanding tasks. However, it is challenging due to the difficulty of modeling long-range relationships and the heavy computational burden caused by more frames. In this paper, we introduce a Long-Form VIdeo-LAnguage pre-training model (LF-VILA) and train it on a large-scale long-form video and paragraph dataset constructed from an existing public dataset. To effectively capture the rich temporal dynamics and to better align video and language in an efficient end-to-end manner, we introduce two novel designs in our LF-VILA model. We first propose a Multimodal Temporal Contrastive (MTC) loss to learn the temporal relation across different modalities by encouraging fine-grained alignment between long-form videos and paragraphs. Second, we propose a Hierarchical Temporal Window Attention (HTWA) mechanism to effectively capture long-range dependency while reducing computational cost in Transformer. We fine-tune the pre-trained LF-VILA model on seven downstream long-form video-language understanding tasks of paragraph-to-video retrieval and long-form video question-answering, and achieve new state-of-the-art performances. Specifically, our model achieves 16.1% relative improvement on ActivityNet paragraph-to-video retrieval task and 2.4% on How2QA task, respectively. We release our code, dataset, and pre-trained models at https://github.com/microsoft/XPretrain.
CLIP-ViP: Adapting Pre-trained Image-Text Model to Video-Language Representation Alignment
Sep 23, 2022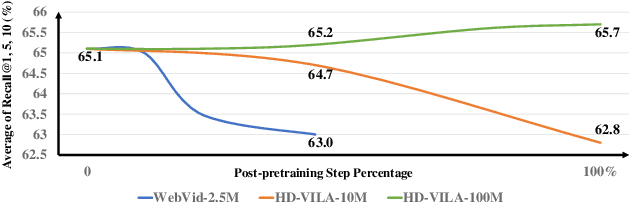
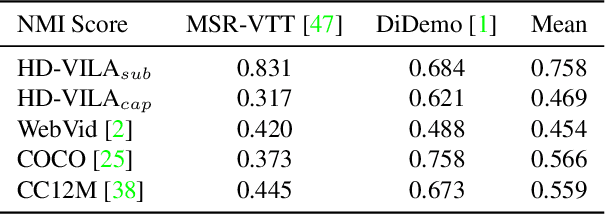
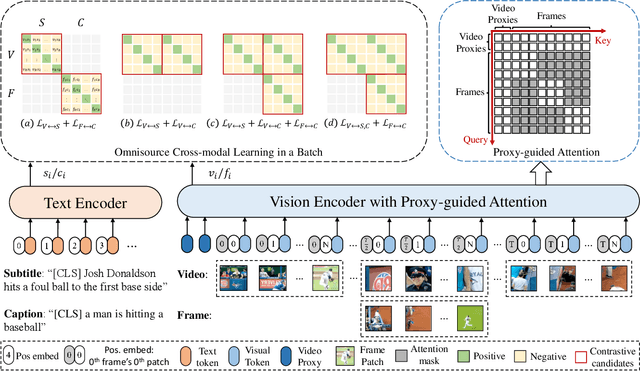
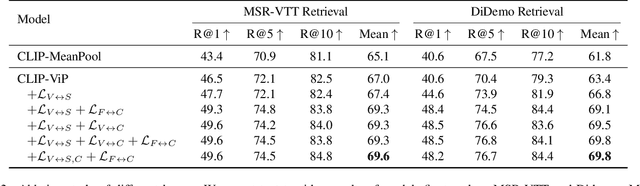
The pre-trained image-text models, like CLIP, have demonstrated the strong power of vision-language representation learned from a large scale of web-collected image-text data. In light of the well-learned visual features, some existing works transfer image representation to video domain and achieve good results. However, how to utilize image-language pre-trained model (e.g., CLIP) for video-language pre-training (post-pretraining) is still under explored. In this paper, we investigate two questions: 1) what are the factors hindering post-pretraining CLIP to further improve the performance on video-language tasks? and 2) how to mitigate the impact of these factors? Through a series of comparative experiments and analyses, we find that the data scale and domain gap between language sources have great impacts. Motivated by these, we propose a Omnisource Cross-modal Learning method equipped with a Video Proxy mechanism on the basis of CLIP, namely CLIP-ViP. Extensive results show that our approach improves the performance of CLIP on video-text retrieval by a large margin. Our model also achieves SOTA results on a variety of datasets, including MSR-VTT, DiDeMo, LSMDC, and ActivityNet. We will release our code and pre-trained CLIP-ViP models at https://github.com/microsoft/XPretrain/tree/main/CLIP-ViP.
Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions
Nov 19, 2021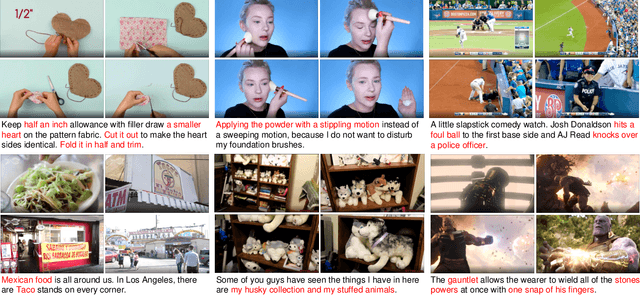
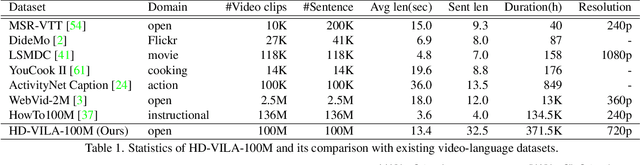
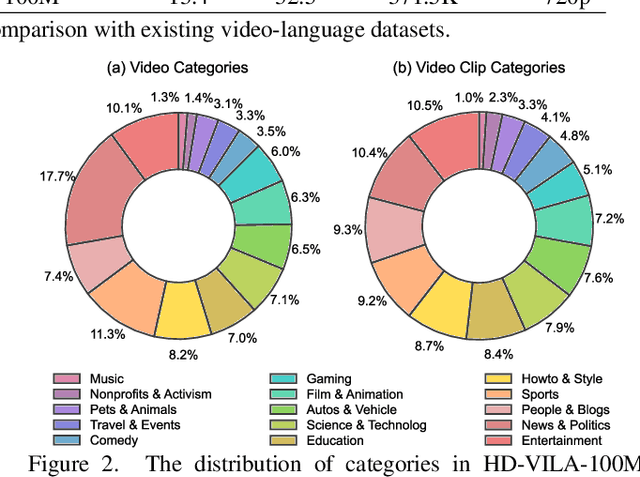

We study joint video and language (VL) pre-training to enable cross-modality learning and benefit plentiful downstream VL tasks. Existing works either extract low-quality video features or learn limited text embedding, while neglecting that high-resolution videos and diversified semantics can significantly improve cross-modality learning. In this paper, we propose a novel High-resolution and Diversified VIdeo-LAnguage pre-training model (HD-VILA) for many visual tasks. In particular, we collect a large dataset with two distinct properties: 1) the first high-resolution dataset including 371.5k hours of 720p videos, and 2) the most diversified dataset covering 15 popular YouTube categories. To enable VL pre-training, we jointly optimize the HD-VILA model by a hybrid Transformer that learns rich spatiotemporal features, and a multimodal Transformer that enforces interactions of the learned video features with diversified texts. Our pre-training model achieves new state-of-the-art results in 10 VL understanding tasks and 2 more novel text-to-visual generation tasks. For example, we outperform SOTA models with relative increases of 38.5% R@1 in zero-shot MSR-VTT text-to-video retrieval task, and 53.6% in high-resolution dataset LSMDC. The learned VL embedding is also effective in generating visually pleasing and semantically relevant results in text-to-visual manipulation and super-resolution tasks.
Unifying Multimodal Transformer for Bi-directional Image and Text Generation
Oct 19, 2021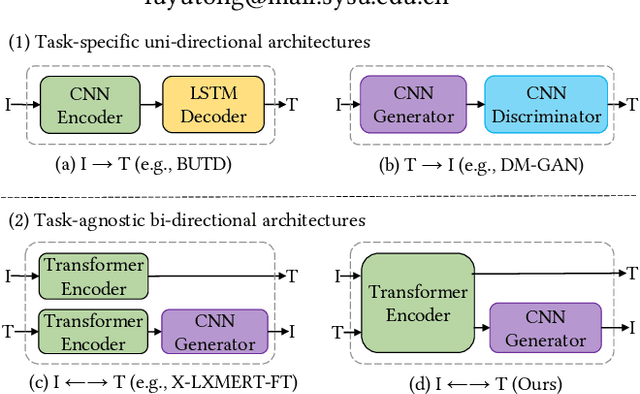
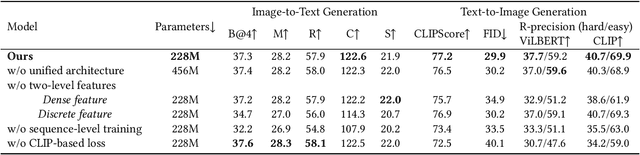
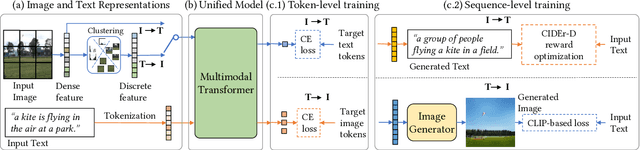
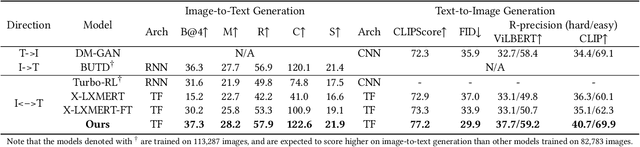
We study the joint learning of image-to-text and text-to-image generations, which are naturally bi-directional tasks. Typical existing works design two separate task-specific models for each task, which impose expensive design efforts. In this work, we propose a unified image-and-text generative framework based on a single multimodal model to jointly study the bi-directional tasks. We adopt Transformer as our unified architecture for its strong performance and task-agnostic design. Specifically, we formulate both tasks as sequence generation tasks, where we represent images and text as unified sequences of tokens, and the Transformer learns multimodal interactions to generate sequences. We further propose two-level granularity feature representations and sequence-level training to improve the Transformer-based unified framework. Experiments show that our approach significantly improves previous Transformer-based model X-LXMERT's FID from 37.0 to 29.9 (lower is better) for text-to-image generation, and improves CIDEr-D score from 100.9% to 122.6% for fine-tuned image-to-text generation on the MS-COCO dataset. Our code is available online.
Learning Fine-Grained Motion Embedding for Landscape Animation
Sep 13, 2021

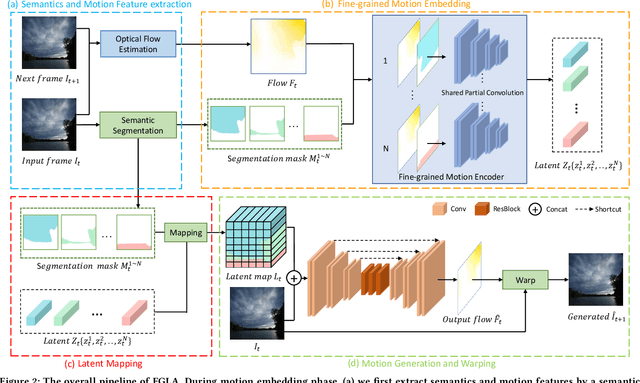
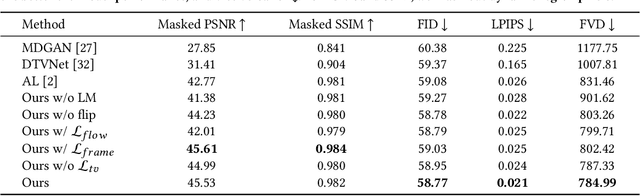
In this paper we focus on landscape animation, which aims to generate time-lapse videos from a single landscape image. Motion is crucial for landscape animation as it determines how objects move in videos. Existing methods are able to generate appealing videos by learning motion from real time-lapse videos. However, current methods suffer from inaccurate motion generation, which leads to unrealistic video results. To tackle this problem, we propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. Our model consists of two parts: (1) a motion encoder which embeds time-lapse motion in a fine-grained way. (2) a motion generator which generates realistic motion to animate input images. To train and evaluate on diverse time-lapse videos, we build the largest high-resolution Time-lapse video dataset with Diverse scenes, namely Time-lapse-D, which includes 16,874 video clips with over 10 million frames. Quantitative and qualitative experimental results demonstrate the superiority of our method. In particular, our method achieves relative improvements by 19% on LIPIS and 5.6% on FVD compared with state-of-the-art methods on our dataset. A user study carried out with 700 human subjects shows that our approach visually outperforms existing methods by a large margin.