 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowFormer: A Transformer Architecture and Its Masked Cost Volume Autoencoding for Optical Flow
Jun 08, 2023This paper introduces a novel transformer-based network architecture, FlowFormer, along with the Masked Cost Volume AutoEncoding (MCVA) for pretraining it to tackle the problem of optical flow estimation. FlowFormer tokenizes the 4D cost-volume built from the source-target image pair and iteratively refines flow estimation with a cost-volume encoder-decoder architecture. The cost-volume encoder derives a cost memory with alternate-group transformer~(AGT) layers in a latent space and the decoder recurrently decodes flow from the cost memory with dynamic positional cost queries. On the Sintel benchmark, FlowFormer architecture achieves 1.16 and 2.09 average end-point-error~(AEPE) on the clean and final pass, a 16.5\% and 15.5\% error reduction from the GMA~(1.388 and 2.47). MCVA enhances FlowFormer by pretraining the cost-volume encoder with a masked autoencoding scheme, which further unleashes the capability of FlowFormer with unlabeled data. This is especially critical in optical flow estimation because ground truth flows are more expensive to acquire than labels in other vision tasks. MCVA improves FlowFormer all-sided and FlowFormer+MCVA ranks 1st among all published methods on both Sintel and KITTI-2015 benchmarks and achieves the best generalization performance. Specifically, FlowFormer+MCVA achieves 1.07 and 1.94 AEPE on the Sintel benchmark, leading to 7.76\% and 7.18\% error reductions from FlowFormer.
Context-TAP: Tracking Any Point Demands Spatial Context Features
Jun 03, 2023



We tackle the problem of Tracking Any Point (TAP) in videos, which specifically aims at estimating persistent long-term trajectories of query points in videos. Previous methods attempted to estimate these trajectories independently to incorporate longer image sequences, therefore, ignoring the potential benefits of incorporating spatial context features. We argue that independent video point tracking also demands spatial context features. To this end, we propose a novel framework Context-TAP, which effectively improves point trajectory accuracy by aggregating spatial context features in videos. Context-TAP contains two main modules: 1) a SOurse Feature Enhancement (SOFE) module, and 2) a TArget Feature Aggregation (TAFA) module. Context-TAP significantly improves PIPs all-sided, reducing 11.4% Average Trajectory Error of Occluded Points (ATE-Occ) on CroHD and increasing 11.8% Average Percentage of Correct Keypoint (A-PCK) on TAP-Vid-Kinectics. Demos are available at this $\href{https://wkbian.github.io/Projects/Context-TAP/}{webpage}$.
A Unified Conditional Framework for Diffusion-based Image Restoration
May 31, 2023



Diffusion Probabilistic Models (DPMs) have recently shown remarkable performance in image generation tasks, which are capable of generating highly realistic images. When adopting DPMs for image restoration tasks, the crucial aspect lies in how to integrate the conditional information to guide the DPMs to generate accurate and natural output, which has been largely overlooked in existing works. In this paper, we present a unified conditional framework based on diffusion models for image restoration. We leverage a lightweight UNet to predict initial guidance and the diffusion model to learn the residual of the guidance. By carefully designing the basic module and integration module for the diffusion model block, we integrate the guidance and other auxiliary conditional information into every block of the diffusion model to achieve spatially-adaptive generation conditioning. To handle high-resolution images, we propose a simple yet effective inter-step patch-splitting strategy to produce arbitrary-resolution images without grid artifacts. We evaluate our conditional framework on three challenging tasks: extreme low-light denoising, deblurring, and JPEG restoration, demonstrating its significant improvements in perceptual quality and the generalization to restoration tasks.
Voxel2Hemodynamics: An End-to-end Deep Learning Method for Predicting Coronary Artery Hemodynamics
May 30, 2023Local hemodynamic forces play an important role in determining the functional significance of coronary arterial stenosis and understanding the mechanism of coronary disease progression. Computational fluid dynamics (CFD) have been widely performed to simulate hemodynamics non-invasively from coronary computed tomography angiography (CCTA) images. However, accurate computational analysis is still limited by the complex construction of patient-specific modeling and time-consuming computation. In this work, we proposed an end-to-end deep learning framework, which could predict the coronary artery hemodynamics from CCTA images. The model was trained on the hemodynamic data obtained from 3D simulations of synthetic and real datasets. Extensive experiments demonstrated that the predicted hemdynamic distributions by our method agreed well with the CFD-derived results. Quantitatively, the proposed method has the capability of predicting the fractional flow reserve with an average error of 0.5\% and 2.5\% for the synthetic dataset and real dataset, respectively. Particularly, our method achieved much better accuracy for the real dataset compared to PointNet++ with the point cloud input. This study demonstrates the feasibility and great potential of our end-to-end deep learning method as a fast and accurate approach for hemodynamic analysis.
Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising
May 29, 2023



Leveraging large-scale image-text datasets and advancements in diffusion models, text-driven generative models have made remarkable strides in the field of image generation and editing. This study explores the potential of extending the text-driven ability to the generation and editing of multi-text conditioned long videos. Current methodologies for video generation and editing, while innovative, are often confined to extremely short videos (typically less than 24 frames) and are limited to a single text condition. These constraints significantly limit their applications given that real-world videos usually consist of multiple segments, each bearing different semantic information. To address this challenge, we introduce a novel paradigm dubbed as Gen-L-Video, capable of extending off-the-shelf short video diffusion models for generating and editing videos comprising hundreds of frames with diverse semantic segments without introducing additional training, all while preserving content consistency. We have implemented three mainstream text-driven video generation and editing methodologies and extended them to accommodate longer videos imbued with a variety of semantic segments with our proposed paradigm. Our experimental outcomes reveal that our approach significantly broadens the generative and editing capabilities of video diffusion models, offering new possibilities for future research and applications. The code is available at https://github.com/G-U-N/Gen-L-Video.
Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model
May 24, 2023



Foundation models have made significant strides in various applications, including text-to-image generation, panoptic segmentation, and natural language processing. This paper presents Instruct2Act, a framework that utilizes Large Language Models to map multi-modal instructions to sequential actions for robotic manipulation tasks. Specifically, Instruct2Act employs the LLM model to generate Python programs that constitute a comprehensive perception, planning, and action loop for robotic tasks. In the perception section, pre-defined APIs are used to access multiple foundation models where the Segment Anything Model (SAM) accurately locates candidate objects, and CLIP classifies them. In this way, the framework leverages the expertise of foundation models and robotic abilities to convert complex high-level instructions into precise policy codes. Our approach is adjustable and flexible in accommodating various instruction modalities and input types and catering to specific task demands. We validated the practicality and efficiency of our approach by assessing it on robotic tasks in different scenarios within tabletop manipulation domains. Furthermore, our zero-shot method outperformed many state-of-the-art learning-based policies in several tasks. The code for our proposed approach is available at https://github.com/OpenGVLab/Instruct2Act, serving as a robust benchmark for high-level robotic instruction tasks with assorted modality inputs.
ReasonNet: End-to-End Driving with Temporal and Global Reasoning
May 17, 2023



The large-scale deployment of autonomous vehicles is yet to come, and one of the major remaining challenges lies in urban dense traffic scenarios. In such cases, it remains challenging to predict the future evolution of the scene and future behaviors of objects, and to deal with rare adverse events such as the sudden appearance of occluded objects. In this paper, we present ReasonNet, a novel end-to-end driving framework that extensively exploits both temporal and global information of the driving scene. By reasoning on the temporal behavior of objects, our method can effectively process the interactions and relationships among features in different frames. Reasoning about the global information of the scene can also improve overall perception performance and benefit the detection of adverse events, especially the anticipation of potential danger from occluded objects. For comprehensive evaluation on occlusion events, we also release publicly a driving simulation benchmark DriveOcclusionSim consisting of diverse occlusion events. We conduct extensive experiments on multiple CARLA benchmarks, where our model outperforms all prior methods, ranking first on the sensor track of the public CARLA Leaderboard.
SUG: Single-dataset Unified Generalization for 3D Point Cloud Classification
May 16, 2023Although Domain Generalization (DG) problem has been fast-growing in the 2D image tasks, its exploration on 3D point cloud data is still insufficient and challenged by more complex and uncertain cross-domain variances with uneven inter-class modality distribution. In this paper, different from previous 2D DG works, we focus on the 3D DG problem and propose a Single-dataset Unified Generalization (SUG) framework that only leverages a single source dataset to alleviate the unforeseen domain differences faced by a well-trained source model. Specifically, we first design a Multi-grained Sub-domain Alignment (MSA) method, which can constrain the learned representations to be domain-agnostic and discriminative, by performing a multi-grained feature alignment process between the splitted sub-domains from the single source dataset. Then, a Sample-level Domain-aware Attention (SDA) strategy is presented, which can selectively enhance easy-to-adapt samples from different sub-domains according to the sample-level inter-domain distance to avoid the negative transfer. Experiments demonstrate that our SUG can boost the generalization ability for unseen target domains, even outperforming the existing unsupervised domain adaptation methods that have to access extensive target domain data. Our code is available at https://github.com/SiyuanHuang95/SUG.
Segmentation and Vascular Vectorization for Coronary Artery by Geometry-based Cascaded Neural Network
May 07, 2023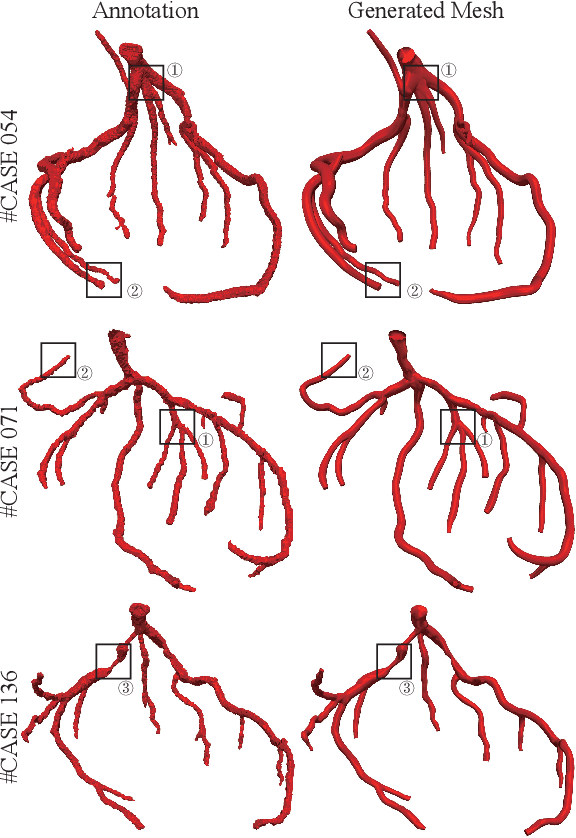
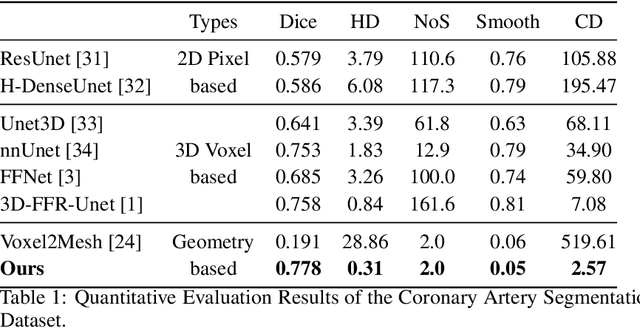
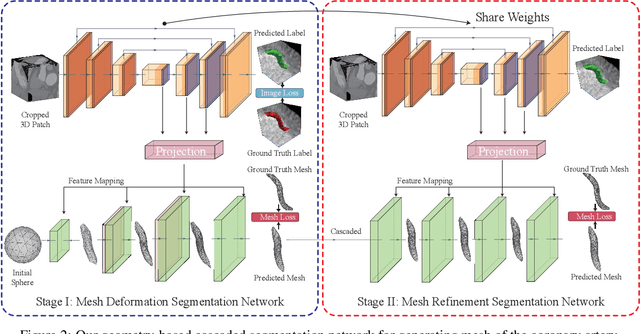
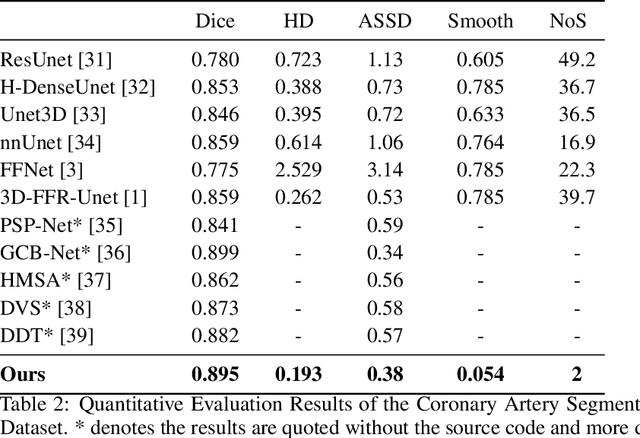
Segmentation of the coronary artery is an important task for the quantitative analysis of coronary computed tomography angiography (CCTA) images and is being stimulated by the field of deep learning. However, the complex structures with tiny and narrow branches of the coronary artery bring it a great challenge. Coupled with the medical image limitations of low resolution and poor contrast, fragmentations of segmented vessels frequently occur in the prediction. Therefore, a geometry-based cascaded segmentation method is proposed for the coronary artery, which has the following innovations: 1) Integrating geometric deformation networks, we design a cascaded network for segmenting the coronary artery and vectorizing results. The generated meshes of the coronary artery are continuous and accurate for twisted and sophisticated coronary artery structures, without fragmentations. 2) Different from mesh annotations generated by the traditional marching cube method from voxel-based labels, a finer vectorized mesh of the coronary artery is reconstructed with the regularized morphology. The novel mesh annotation benefits the geometry-based segmentation network, avoiding bifurcation adhesion and point cloud dispersion in intricate branches. 3) A dataset named CCA-200 is collected, consisting of 200 CCTA images with coronary artery disease. The ground truths of 200 cases are coronary internal diameter annotations by professional radiologists. Extensive experiments verify our method on our collected dataset CCA-200 and public ASOCA dataset, with a Dice of 0.778 on CCA-200 and 0.895 on ASOCA, showing superior results. Especially, our geometry-based model generates an accurate, intact and smooth coronary artery, devoid of any fragmentations of segmented vessels.
Personalize Segment Anything Model with One Shot
May 04, 2023Driven by large-data pre-training, Segment Anything Model (SAM) has been demonstrated as a powerful and promptable framework, revolutionizing the segmentation models. Despite the generality, customizing SAM for specific visual concepts without man-powered prompting is under explored, e.g., automatically segmenting your pet dog in different images. In this paper, we propose a training-free Personalization approach for SAM, termed as PerSAM. Given only a single image with a reference mask, PerSAM first localizes the target concept by a location prior, and segments it within other images or videos via three techniques: target-guided attention, target-semantic prompting, and cascaded post-refinement. In this way, we effectively adapt SAM for private use without any training. To further alleviate the mask ambiguity, we present an efficient one-shot fine-tuning variant, PerSAM-F. Freezing the entire SAM, we introduce two learnable weights for multi-scale masks, only training 2 parameters within 10 seconds for improved performance. To demonstrate our efficacy, we construct a new segmentation dataset, PerSeg, for personalized evaluation, and test our methods on video object segmentation with competitive performance. Besides, our approach can also enhance DreamBooth to personalize Stable Diffusion for text-to-image generation, which discards the background disturbance for better target appearance learning. Code is released at https://github.com/ZrrSkywalker/Personalize-SAM