 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressNet: Generative Compression at Extremely Low Bitrates
Jun 14, 2020
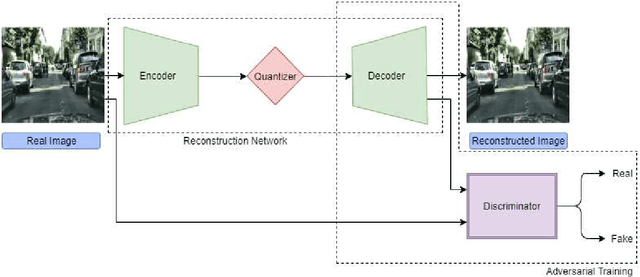
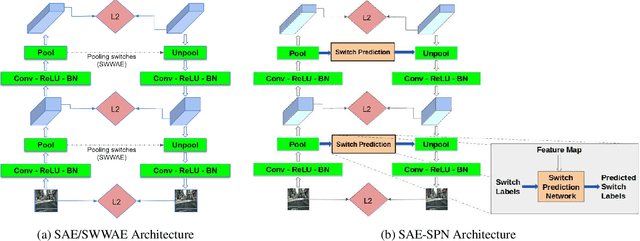

Compressing images at extremely low bitrates (< 0.1 bpp) has always been a challenging task since the quality of reconstruction significantly reduces due to the strong imposed constraint on the number of bits allocated for the compressed data. With the increasing need to transfer large amounts of images with limited bandwidth, compressing images to very low sizes is a crucial task. However, the existing methods are not effective at extremely low bitrates. To address this need, we propose a novel network called CompressNet which augments a Stacked Autoencoder with a Switch Prediction Network (SAE-SPN). This helps in the reconstruction of visually pleasing images at these low bitrates (< 0.1 bpp). We benchmark the performance of our proposed method on the Cityscapes dataset, evaluating over different metrics at extremely low bitrates to show that our method outperforms the other state-of-the-art. In particular, at a bitrate of 0.07, CompressNet achieves 22% lower Perceptual Loss and 55% lower Frechet Inception Distance (FID) compared to the deep learning SOTA methods.
Context-aware Dynamics Model for Generalization in Model-Based Reinforcement Learning
May 14, 2020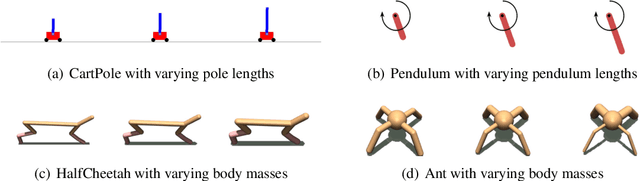

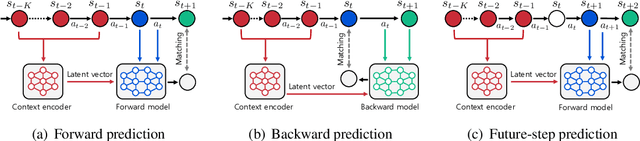
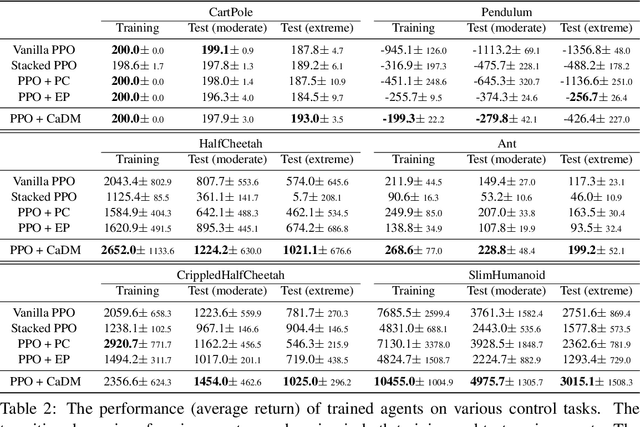
Model-based reinforcement learning (RL) enjoys several benefits, such as data-efficiency and planning, by learning a model of the environment's dynamics. However, learning a global model that can generalize across different dynamics is a challenging task. To tackle this problem, we decompose the task of learning a global dynamics model into two stages: (a) learning a context latent vector that captures the local dynamics, then (b) predicting the next state conditioned on it. In order to encode dynamics-specific information into the context latent vector, we introduce a novel loss function that encourages the context latent vector to be useful for predicting both forward and backward dynamics. The proposed method achieves superior generalization ability across various simulated robotics and control tasks, compared to existing RL schemes.
Time Dependence in Non-Autonomous Neural ODEs
May 06, 2020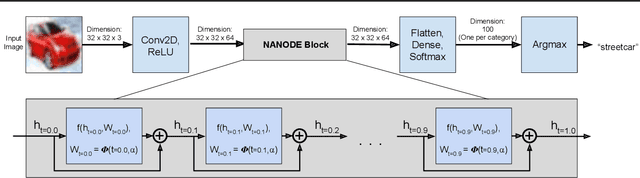
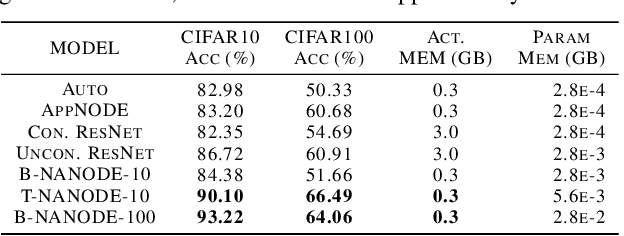
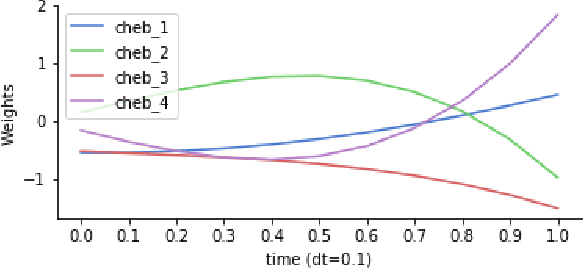
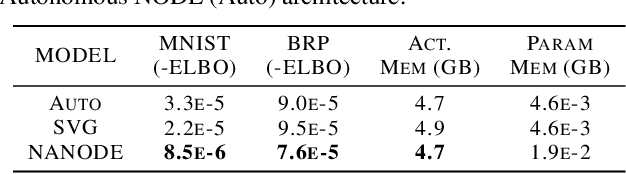
Neural Ordinary Differential Equations (ODEs) are elegant reinterpretations of deep networks where continuous time can replace the discrete notion of depth, ODE solvers perform forward propagation, and the adjoint method enables efficient, constant memory backpropagation. Neural ODEs are universal approximators only when they are non-autonomous, that is, the dynamics depends explicitly on time. We propose a novel family of Neural ODEs with time-varying weights, where time-dependence is non-parametric, and the smoothness of weight trajectories can be explicitly controlled to allow a tradeoff between expressiveness and efficiency. Using this enhanced expressiveness, we outperform previous Neural ODE variants in both speed and representational capacity, ultimately outperforming standard ResNet and CNN models on select image classification and video prediction tasks.
Improved Consistency Regularization for GANs
Feb 11, 2020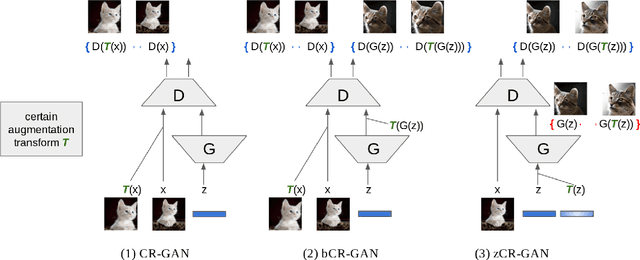
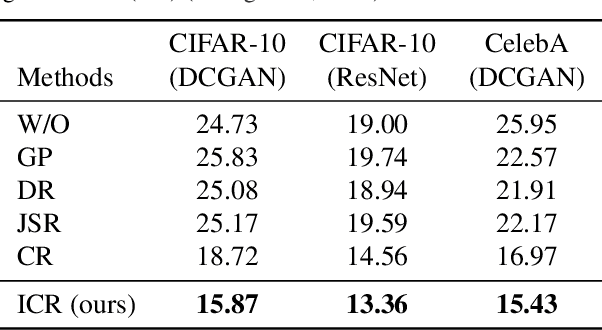


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
BRPO: Batch Residual Policy Optimization
Feb 08, 2020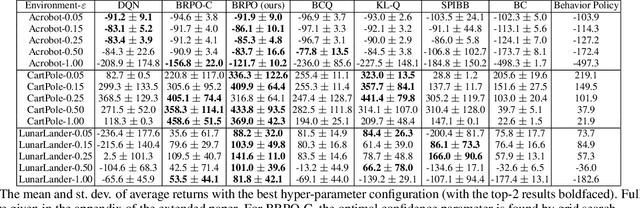

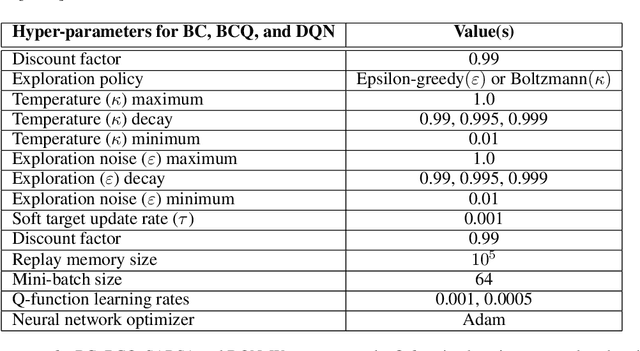
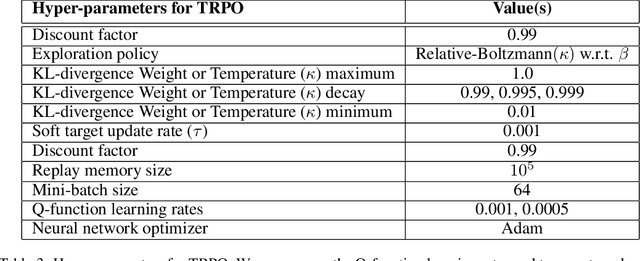
In batch reinforcement learning (RL), one often constrains a learned policy to be close to the behavior (data-generating) policy, e.g., by constraining the learned action distribution to differ from the behavior policy by some maximum degree that is the same at each state. This can cause batch RL to be overly conservative, unable to exploit large policy changes at frequently-visited, high-confidence states without risking poor performance at sparsely-visited states. To remedy this, we propose residual policies, where the allowable deviation of the learned policy is state-action-dependent. We derive a new for RL method, BRPO, which learns both the policy and allowable deviation that jointly maximize a lower bound on policy performance. We show that BRPO achieves the state-of-the-art performance in a number of tasks.
High-Fidelity Synthesis with Disentangled Representation
Jan 13, 2020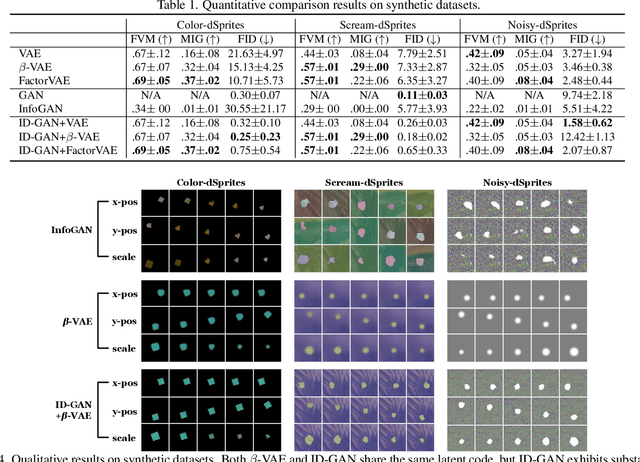
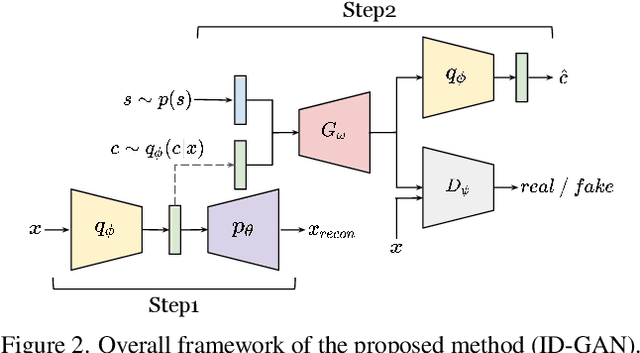
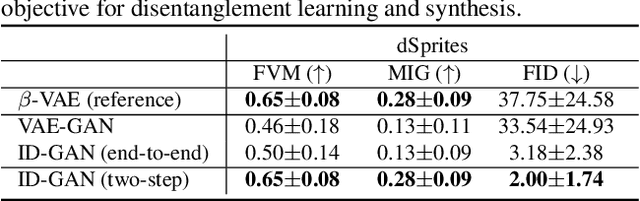
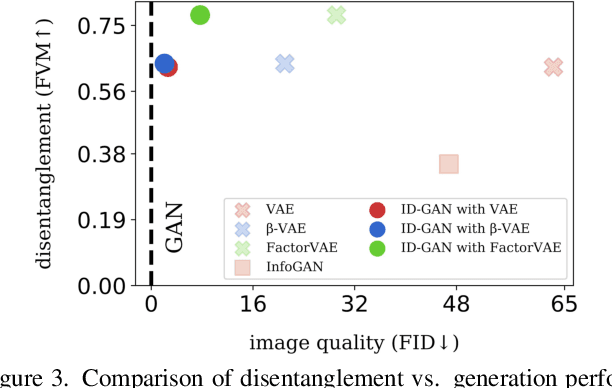
Learning disentangled representation of data without supervision is an important step towards improving the interpretability of generative models. Despite recent advances in disentangled representation learning, existing approaches often suffer from the trade-off between representation learning and generation performance i.e. improving generation quality sacrifices disentanglement performance). We propose an Information-Distillation Generative Adversarial Network (ID-GAN), a simple yet generic framework that easily incorporates the existing state-of-the-art models for both disentanglement learning and high-fidelity synthesis. Our method learns disentangled representation using VAE-based models, and distills the learned representation with an additional nuisance variable to the separate GAN-based generator for high-fidelity synthesis. To ensure that both generative models are aligned to render the same generative factors, we further constrain the GAN generator to maximize the mutual information between the learned latent code and the output. Despite the simplicity, we show that the proposed method is highly effective, achieving comparable image generation quality to the state-of-the-art methods using the disentangled representation. We also show that the proposed decomposition leads to an efficient and stable model design, and we demonstrate photo-realistic high-resolution image synthesis results (1024x1024 pixels) for the first time using the disentangled representations.
Meta Reinforcement Learning with Autonomous Inference of Subtask Dependencies
Jan 01, 2020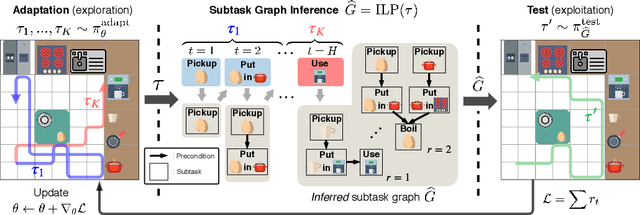
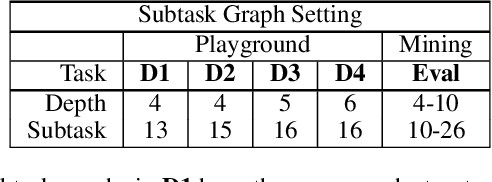
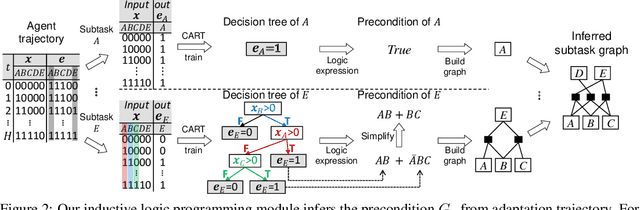
We propose and address a novel few-shot RL problem, where a task is characterized by a subtask graph which describes a set of subtasks and their dependencies that are unknown to the agent. The agent needs to quickly adapt to the task over few episodes during adaptation phase to maximize the return in the test phase. Instead of directly learning a meta-policy, we develop a Meta-learner with Subtask Graph Inference(MSGI), which infers the latent parameter of the task by interacting with the environment and maximizes the return given the latent parameter. To facilitate learning, we adopt an intrinsic reward inspired by upper confidence bound (UCB) that encourages efficient exploration. Our experiment results on two grid-world domains and StarCraft II environments show that the proposed method is able to accurately infer the latent task parameter, and to adapt more efficiently than existing meta RL and hierarchical RL methods.
Efficient Adversarial Training with Transferable Adversarial Examples
Dec 27, 2019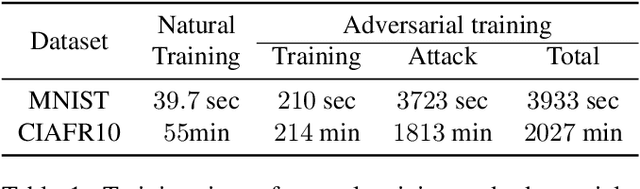
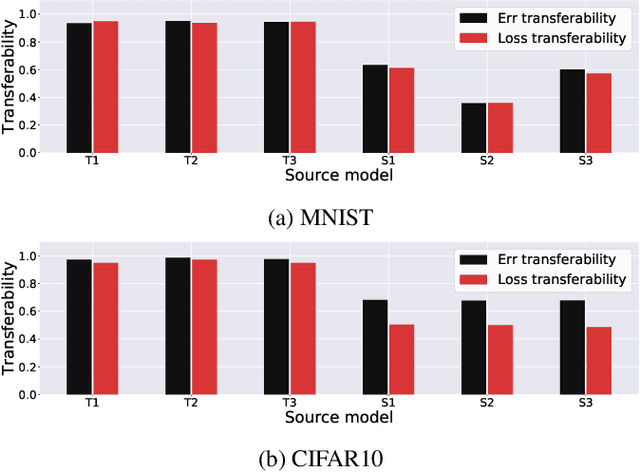
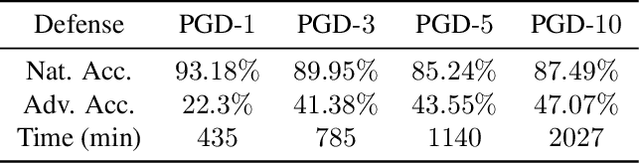
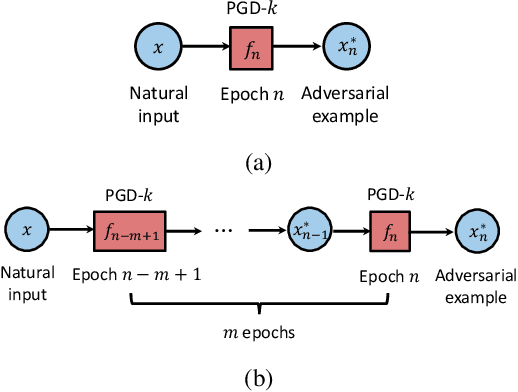
Adversarial training is an effective defense method to protect classification models against adversarial attacks. However, one limitation of this approach is that it can require orders of magnitude additional training time due to high cost of generating strong adversarial examples during training. In this paper, we first show that there is high transferability between models from neighboring epochs in the same training process, i.e., adversarial examples from one epoch continue to be adversarial in subsequent epochs. Leveraging this property, we propose a novel method, Adversarial Training with Transferable Adversarial Examples (ATTA), that can enhance the robustness of trained models and greatly improve the training efficiency by accumulating adversarial perturbations through epochs. Compared to state-of-the-art adversarial training methods, ATTA enhances adversarial accuracy by up to 7.2% on CIFAR10 and requires 12~14x less training time on MNIST and CIFAR10 datasets with comparable model robustness.
How Should an Agent Practice?
Dec 15, 2019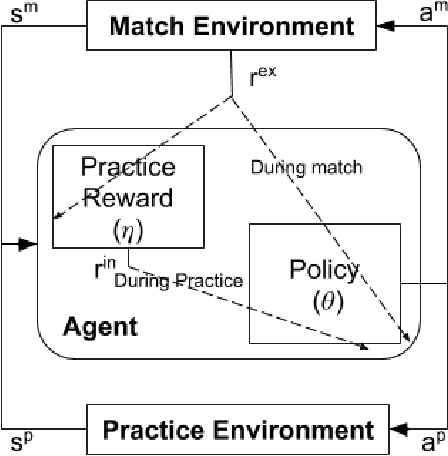
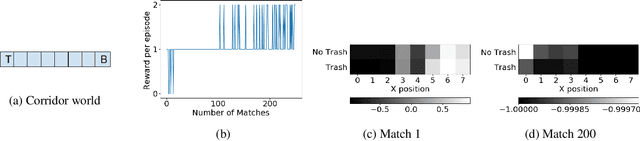
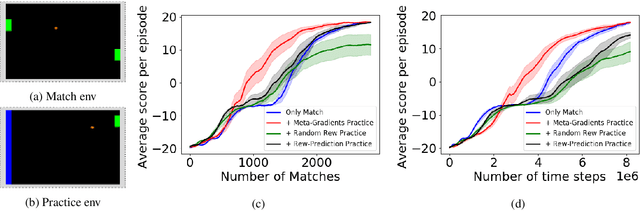
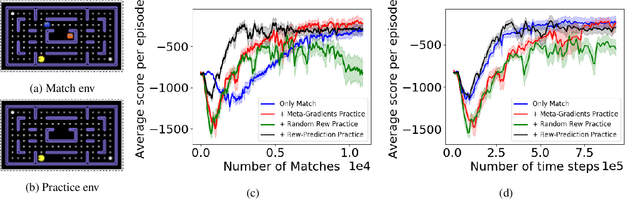
We present a method for learning intrinsic reward functions to drive the learning of an agent during periods of practice in which extrinsic task rewards are not available. During practice, the environment may differ from the one available for training and evaluation with extrinsic rewards. We refer to this setup of alternating periods of practice and objective evaluation as practice-match, drawing an analogy to regimes of skill acquisition common for humans in sports and games. The agent must effectively use periods in the practice environment so that performance improves during matches. In the proposed method the intrinsic practice reward is learned through a meta-gradient approach that adapts the practice reward parameters to reduce the extrinsic match reward loss computed from matches. We illustrate the method on a simple grid world, and evaluate it in two games in which the practice environment differs from match: Pong with practice against a wall without an opponent, and PacMan with practice in a maze without ghosts. The results show gains from learning in practice in addition to match periods over learning in matches only.
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
Nov 05, 2019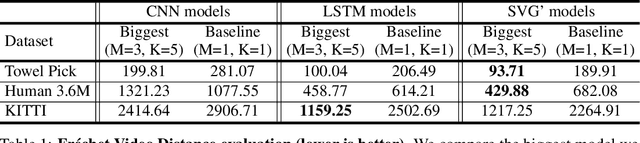
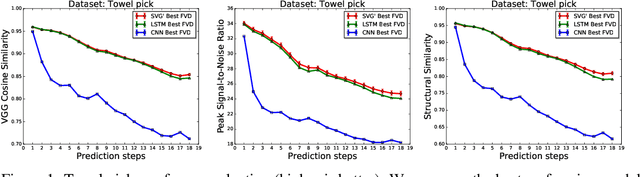
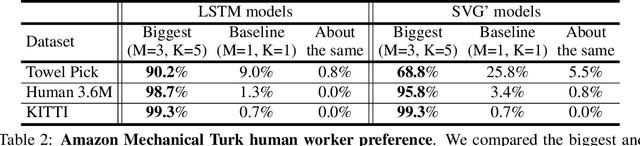

Predicting future video frames is extremely challenging, as there are many factors of variation that make up the dynamics of how frames change through time. Previously proposed solutions require complex inductive biases inside network architectures with highly specialized computation, including segmentation masks, optical flow, and foreground and background separation. In this work, we question if such handcrafted architectures are necessary and instead propose a different approach: finding minimal inductive bias for video prediction while maximizing network capacity. We investigate this question by performing the first large-scale empirical study and demonstrate state-of-the-art performance by learning large models on three different datasets: one for modeling object interactions, one for modeling human motion, and one for modeling car driving.