 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity Guided Multimodal Fusion Transformer for Semantic Location Prediction in Social Media
May 09, 2024



The purpose of semantic location prediction is to extract relevant semantic location information from multimodal social media posts, offering a more contextual understanding of daily activities compared to GPS coordinates. However, this task becomes challenging due to the presence of noise and irrelevant information in "text-image" pairs. Existing methods suffer from insufficient feature representations and fail to consider the comprehensive integration of similarity at different granularities, making it difficult to filter out noise and irrelevant information. To address these challenges, we propose a Similarity-Guided Multimodal Fusion Transformer (SG-MFT) for predicting social users' semantic locations. First, we utilize a pre-trained large-scale vision-language model to extract high-quality feature representations from social media posts. Then, we introduce a Similarity-Guided Interaction Module (SIM) to alleviate modality heterogeneity and noise interference by incorporating coarse-grained and fine-grained similarity guidance for modality interactions. Specifically, we propose a novel similarity-aware feature interpolation attention mechanism at the coarse level, leveraging modality-wise similarity to mitigate heterogeneity and reduce noise within each modality. Meanwhile, we employ a similarity-aware feed-forward block at the fine level, utilizing element-wise similarity to further mitigate the impact of modality heterogeneity. Building upon pre-processed features with minimal noise and modal interference, we propose a Similarity-aware Feature Fusion Module (SFM) to fuse two modalities with cross-attention mechanism. Comprehensive experimental results demonstrate the superior performance of our proposed method in handling modality imbalance while maintaining efficient fusion effectiveness.
Mimic: Speaking Style Disentanglement for Speech-Driven 3D Facial Animation
Dec 18, 2023Speech-driven 3D facial animation aims to synthesize vivid facial animations that accurately synchronize with speech and match the unique speaking style. However, existing works primarily focus on achieving precise lip synchronization while neglecting to model the subject-specific speaking style, often resulting in unrealistic facial animations. To the best of our knowledge, this work makes the first attempt to explore the coupled information between the speaking style and the semantic content in facial motions. Specifically, we introduce an innovative speaking style disentanglement method, which enables arbitrary-subject speaking style encoding and leads to a more realistic synthesis of speech-driven facial animations. Subsequently, we propose a novel framework called \textbf{Mimic} to learn disentangled representations of the speaking style and content from facial motions by building two latent spaces for style and content, respectively. Moreover, to facilitate disentangled representation learning, we introduce four well-designed constraints: an auxiliary style classifier, an auxiliary inverse classifier, a content contrastive loss, and a pair of latent cycle losses, which can effectively contribute to the construction of the identity-related style space and semantic-related content space. Extensive qualitative and quantitative experiments conducted on three publicly available datasets demonstrate that our approach outperforms state-of-the-art methods and is capable of capturing diverse speaking styles for speech-driven 3D facial animation. The source code and supplementary video are publicly available at: https://zeqing-wang.github.io/Mimic/
Towards Fair and Comprehensive Comparisons for Image-Based 3D Object Detection
Oct 11, 2023



In this work, we build a modular-designed codebase, formulate strong training recipes, design an error diagnosis toolbox, and discuss current methods for image-based 3D object detection. In particular, different from other highly mature tasks, e.g., 2D object detection, the community of image-based 3D object detection is still evolving, where methods often adopt different training recipes and tricks resulting in unfair evaluations and comparisons. What is worse, these tricks may overwhelm their proposed designs in performance, even leading to wrong conclusions. To address this issue, we build a module-designed codebase and formulate unified training standards for the community. Furthermore, we also design an error diagnosis toolbox to measure the detailed characterization of detection models. Using these tools, we analyze current methods in-depth under varying settings and provide discussions for some open questions, e.g., discrepancies in conclusions on KITTI-3D and nuScenes datasets, which have led to different dominant methods for these datasets. We hope that this work will facilitate future research in image-based 3D object detection. Our codes will be released at \url{https://github.com/OpenGVLab/3dodi}
Visual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Hyperuniform disordered parametric loudspeaker array
Jan 03, 2023



A steerable parametric loudspeaker array is known for its directivity and narrow beam width. However, it often suffers from the grating lobes due to periodic array distributions. Here we propose the array configuration of hyperuniform disorder, which is short-range random while correlated at large scales, as a promising alternative distribution of acoustic antennas in phased arrays. Angle-resolved measurements reveal that the proposed array suppresses grating lobes and maintains a minimal radiation region in the vicinity of the main lobe for the primary frequency waves. These distinctive emission features benefit the secondary frequency wave in canceling the grating lobes regardless of the frequencies of the primary waves. Besides that, the hyperuniform disordered array is duplicatable, which facilitates extra-large array design without any additional computational efforts.
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
Aug 31, 2022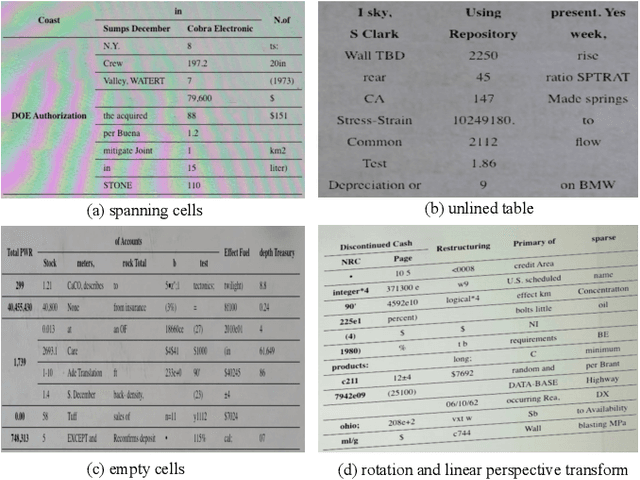
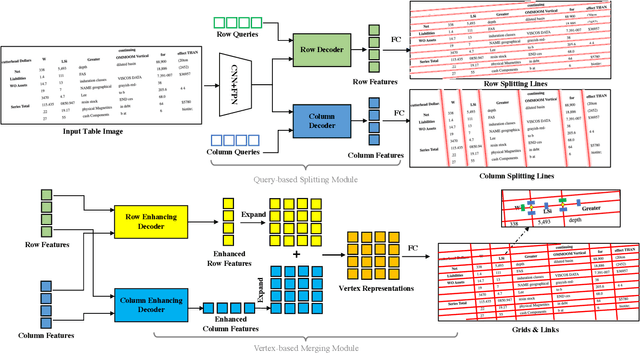
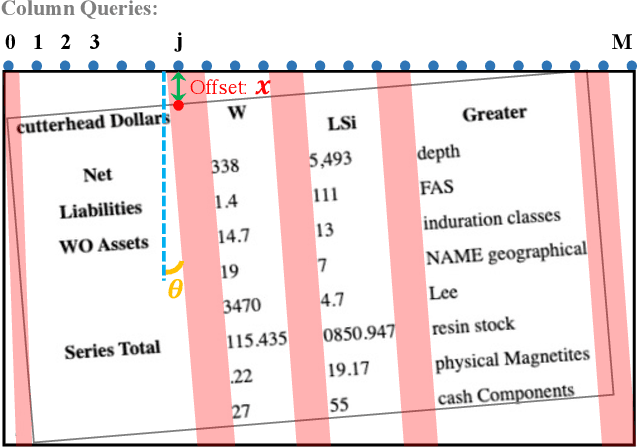
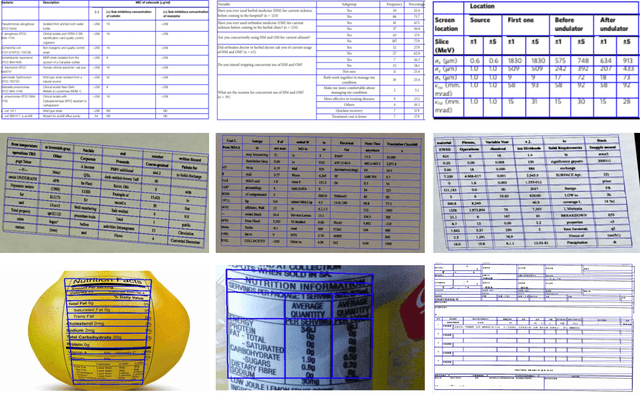
Table structure recognition is a crucial part of document image analysis domain. Its difficulty lies in the need to parse the physical coordinates and logical indices of each cell at the same time. However, the existing methods are difficult to achieve both these goals, especially when the table splitting lines are blurred or tilted. In this paper, we propose an accurate and end-to-end transformer-based table structure recognition method, referred to as TRUST. Transformers are suitable for table structure recognition because of their global computations, perfect memory, and parallel computation. By introducing novel Transformer-based Query-based Splitting Module and Vertex-based Merging Module, the table structure recognition problem is decoupled into two joint optimization sub-tasks: multi-oriented table row/column splitting and table grid merging. The Query-based Splitting Module learns strong context information from long dependencies via Transformer networks, accurately predicts the multi-oriented table row/column separators, and obtains the basic grids of the table accordingly. The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately. We conduct experiments on several popular benchmarks including PubTabNet and SynthTable, our method achieves new state-of-the-art results. In particular, TRUST runs at 10 FPS on PubTabNet, surpassing the previous methods by a large margin.
Semantic decomposition Network with Contrastive and Structural Constraints for Dental Plaque Segmentation
Aug 12, 2022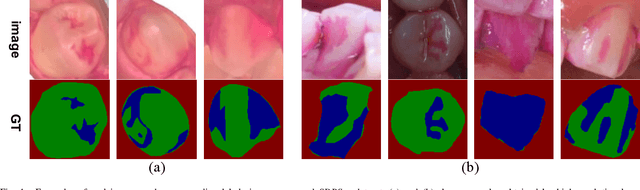
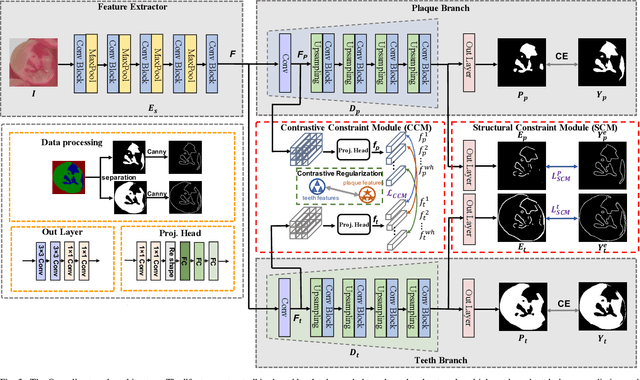

Segmenting dental plaque from images of medical reagent staining provides valuable information for diagnosis and the determination of follow-up treatment plan. However, accurate dental plaque segmentation is a challenging task that requires identifying teeth and dental plaque subjected to semantic-blur regions (i.e., confused boundaries in border regions between teeth and dental plaque) and complex variations of instance shapes, which are not fully addressed by existing methods. Therefore, we propose a semantic decomposition network (SDNet) that introduces two single-task branches to separately address the segmentation of teeth and dental plaque and designs additional constraints to learn category-specific features for each branch, thus facilitating the semantic decomposition and improving the performance of dental plaque segmentation. Specifically, SDNet learns two separate segmentation branches for teeth and dental plaque in a divide-and-conquer manner to decouple the entangled relation between them. Each branch that specifies a category tends to yield accurate segmentation. To help these two branches better focus on category-specific features, two constraint modules are further proposed: 1) contrastive constraint module (CCM) to learn discriminative feature representations by maximizing the distance between different category representations, so as to reduce the negative impact of semantic-blur regions on feature extraction; 2) structural constraint module (SCM) to provide complete structural information for dental plaque of various shapes by the supervision of an boundary-aware geometric constraint. Besides, we construct a large-scale open-source Stained Dental Plaque Segmentation dataset (SDPSeg), which provides high-quality annotations for teeth and dental plaque. Experimental results on SDPSeg datasets show SDNet achieves state-of-the-art performance.
Fine-grained Retrieval Prompt Tuning
Jul 29, 2022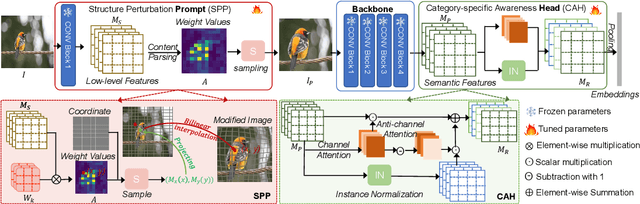
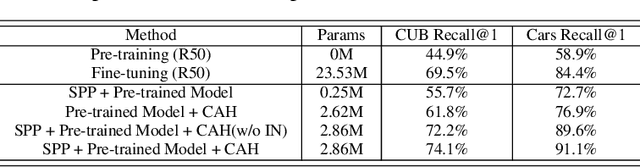
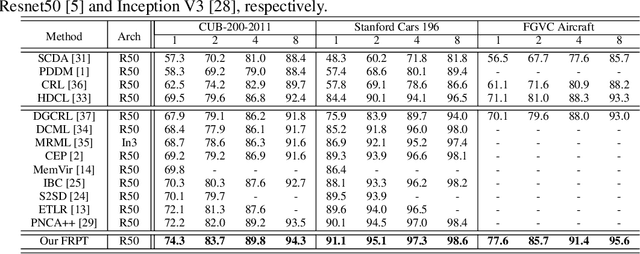

Fine-grained object retrieval aims to learn discriminative representation to retrieve visually similar objects. However, existing top-performing works usually impose pairwise similarities on the semantic embedding spaces to continually fine-tune the entire model in limited-data regimes, thus resulting in easily converging to suboptimal solutions. In this paper, we develop Fine-grained Retrieval Prompt Tuning (FRPT), which steers a frozen pre-trained model to perform the fine-grained retrieval task from the perspectives of sample prompt and feature adaptation. Specifically, FRPT only needs to learn fewer parameters in the prompt and adaptation instead of fine-tuning the entire model, thus solving the convergence to suboptimal solutions caused by fine-tuning the entire model. Technically, as sample prompts, a structure perturbation prompt (SPP) is introduced to zoom and even exaggerate some pixels contributing to category prediction via a content-aware inhomogeneous sampling operation. In this way, SPP can make the fine-grained retrieval task aided by the perturbation prompts close to the solved task during the original pre-training. Besides, a category-specific awareness head is proposed and regarded as feature adaptation, which removes the species discrepancies in the features extracted by the pre-trained model using instance normalization, and thus makes the optimized features only include the discrepancies among subcategories. Extensive experiments demonstrate that our FRPT with fewer learnable parameters achieves the state-of-the-art performance on three widely-used fine-grained datasets.
Cascading Residual Graph Convolutional Network for Multi-Behavior Recommendation
May 26, 2022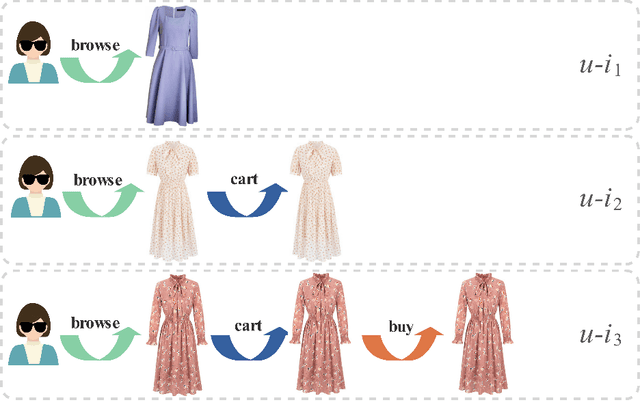

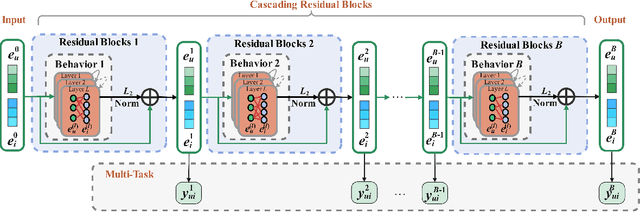
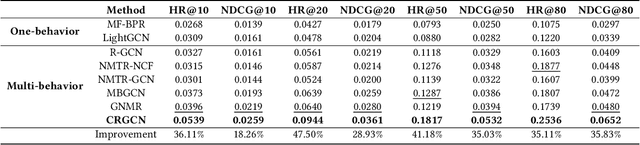
Multi-behavior recommendation exploits multiple types of user-item interactions to alleviate the data sparsity problem faced by the traditional models that often utilize only one type of interaction for recommendation. In real scenarios, users often take a sequence of actions to interact with an item, in order to get more information about the item and thus accurately evaluate whether an item fits personal preference. Those interaction behaviors often obey a certain order, and different behaviors reveal different information or aspects of user preferences towards the target item. Most existing multi-behavior recommendation methods take the strategy to first extract information from different behaviors separately and then fuse them for final prediction. However, they have not exploited the connections between different behaviors to learn user preferences. Besides, they often introduce complex model structures and more parameters to model multiple behaviors, largely increasing the space and time complexity. In this work, we propose a lightweight multi-behavior recommendation model named Cascading Residual Graph Convolutional Network (CRGCN for short), which can explicitly exploit the connections between different behaviors into the embedding learning process without introducing any additional parameters. In particular, we design a cascading residual graph convolutional network structure, which enables our model to learn user preferences by continuously refining user embeddings across different types of behaviors. The multi-task learning method is adopted to jointly optimize our model based on different behaviors. Extensive experimental results on two real-world benchmark datasets show that CRGCN can substantially outperform state-of-the-art methods. Further studies also analyze the effects of leveraging multi-behaviors in different numbers and orders on the final performance.
MonoDistill: Learning Spatial Features for Monocular 3D Object Detection
Jan 26, 2022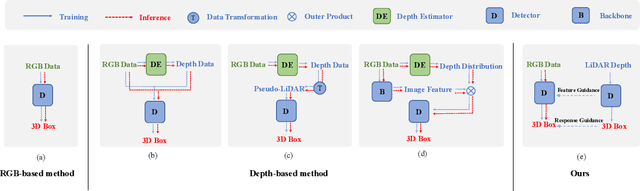
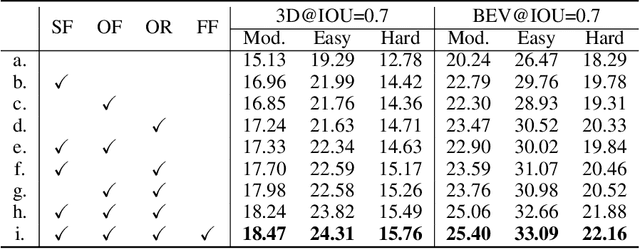

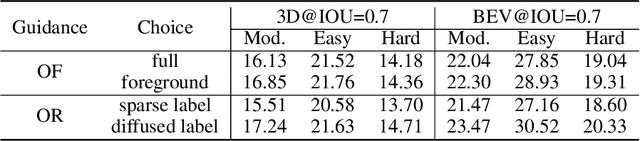
3D object detection is a fundamental and challenging task for 3D scene understanding, and the monocular-based methods can serve as an economical alternative to the stereo-based or LiDAR-based methods. However, accurately detecting objects in the 3D space from a single image is extremely difficult due to the lack of spatial cues. To mitigate this issue, we propose a simple and effective scheme to introduce the spatial information from LiDAR signals to the monocular 3D detectors, without introducing any extra cost in the inference phase. In particular, we first project the LiDAR signals into the image plane and align them with the RGB images. After that, we use the resulting data to train a 3D detector (LiDAR Net) with the same architecture as the baseline model. Finally, this LiDAR Net can serve as the teacher to transfer the learned knowledge to the baseline model. Experimental results show that the proposed method can significantly boost the performance of the baseline model and ranks the $1^{st}$ place among all monocular-based methods on the KITTI benchmark. Besides, extensive ablation studies are conducted, which further prove the effectiveness of each part of our designs and illustrate what the baseline model has learned from the LiDAR Net. Our code will be released at \url{https://github.com/monster-ghost/MonoDistill}.