 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-NeRF: Explicit Neural Radiance Field for Multi-Scene 360$^{\circ} $ Insufficient RGB-D Views
Oct 11, 2022
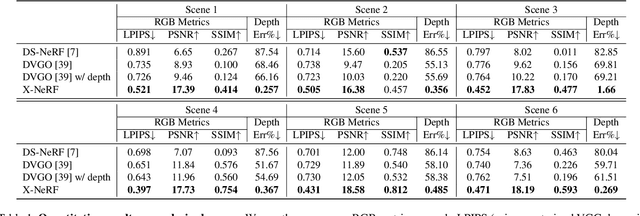

Neural Radiance Fields (NeRFs), despite their outstanding performance on novel view synthesis, often need dense input views. Many papers train one model for each scene respectively and few of them explore incorporating multi-modal data into this problem. In this paper, we focus on a rarely discussed but important setting: can we train one model that can represent multiple scenes, with 360$^\circ $ insufficient views and RGB-D images? We refer insufficient views to few extremely sparse and almost non-overlapping views. To deal with it, X-NeRF, a fully explicit approach which learns a general scene completion process instead of a coordinate-based mapping, is proposed. Given a few insufficient RGB-D input views, X-NeRF first transforms them to a sparse point cloud tensor and then applies a 3D sparse generative Convolutional Neural Network (CNN) to complete it to an explicit radiance field whose volumetric rendering can be conducted fast without running networks during inference. To avoid overfitting, besides common rendering loss, we apply perceptual loss as well as view augmentation through random rotation on point clouds. The proposed methodology significantly out-performs previous implicit methods in our setting, indicating the great potential of proposed problem and approach. Codes and data are available at https://github.com/HaoyiZhu/XNeRF.
Unseen Object 6D Pose Estimation: A Benchmark and Baselines
Jun 23, 2022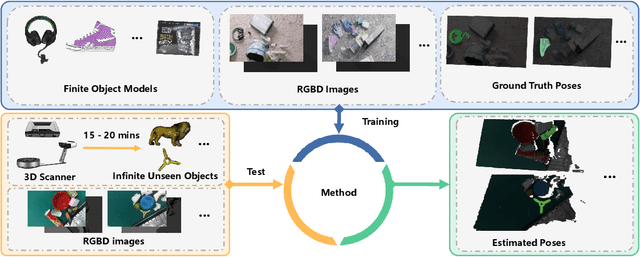
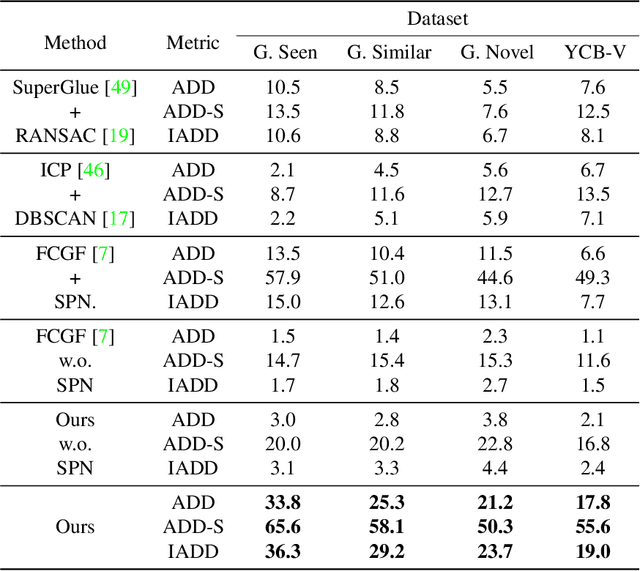

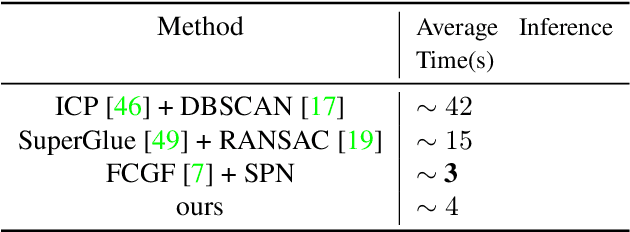
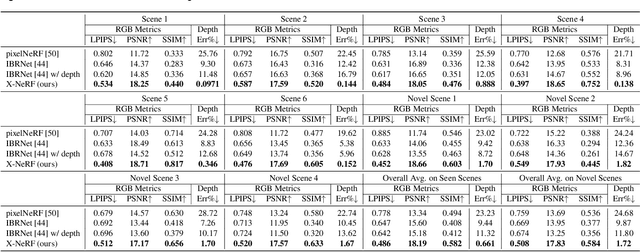
Estimating the 6D pose for unseen objects is in great demand for many real-world applications. However, current state-of-the-art pose estimation methods can only handle objects that are previously trained. In this paper, we propose a new task that enables and facilitates algorithms to estimate the 6D pose estimation of novel objects during testing. We collect a dataset with both real and synthetic images and up to 48 unseen objects in the test set. In the mean while, we propose a new metric named Infimum ADD (IADD) which is an invariant measurement for objects with different types of pose ambiguity. A two-stage baseline solution for this task is also provided. By training an end-to-end 3D correspondences network, our method finds corresponding points between an unseen object and a partial view RGBD image accurately and efficiently. It then calculates the 6D pose from the correspondences using an algorithm robust to object symmetry. Extensive experiments show that our method outperforms several intuitive baselines and thus verify its effectiveness. All the data, code and models will be made publicly available. Project page: www.graspnet.net/unseen6d
TransCG: A Large-Scale Real-World Dataset for Transparent Object Depth Completion and Grasping
Feb 17, 2022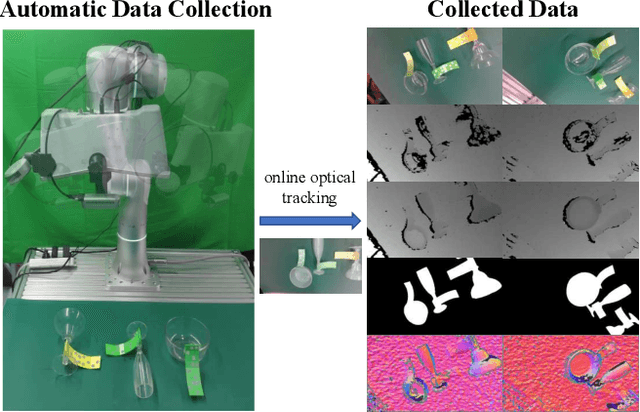

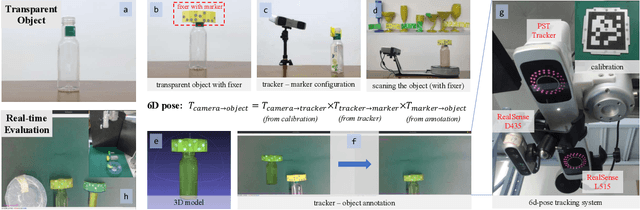
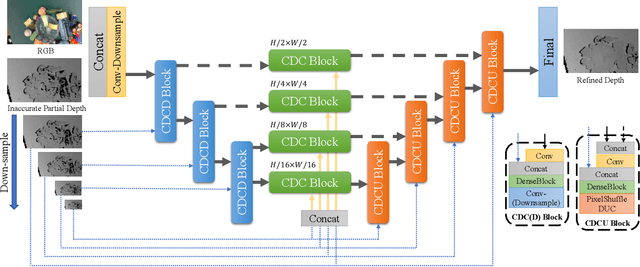
Transparent objects are common in our daily life and frequently handled in the automated production line. Robust vision-based robotic grasping and manipulation for these objects would be beneficial for automation. However, the majority of current grasping algorithms would fail in this case since they heavily rely on the depth image, while ordinary depth sensors usually fail to produce accurate depth information for transparent objects owing to the reflection and refraction of light. In this work, we address this issue by contributing a large-scale real-world dataset for transparent object depth completion, which contains 57,715 RGB-D images from 130 different scenes. Our dataset is the first large-scale real-world dataset and provides the most comprehensive annotation. Cross-domain experiments show that our dataset has a great generalization ability. Moreover, we propose an end-to-end depth completion network, which takes the RGB image and the inaccurate depth map as inputs and outputs a refined depth map. Experiments demonstrate superior efficacy, efficiency and robustness of our method over previous works, and it is able to process images of high resolutions under limited hardware resources. Real robot experiment shows that our method can also be applied to novel object grasping robustly. The full dataset and our method are publicly available at www.graspnet.net/transcg.
HAKE: A Knowledge Engine Foundation for Human Activity Understanding
Feb 14, 2022



Human activity understanding is of widespread interest in artificial intelligence and spans diverse applications like health care and behavior analysis. Although there have been advances with deep learning, it remains challenging. The object recognition-like solutions usually try to map pixels to semantics directly, but activity patterns are much different from object patterns, thus hindering another success. In this work, we propose a novel paradigm to reformulate this task in two-stage: first mapping pixels to an intermediate space spanned by atomic activity primitives, then programming detected primitives with interpretable logic rules to infer semantics. To afford a representative primitive space, we build a knowledge base including 26+ M primitive labels and logic rules from human priors or automatic discovering. Our framework, Human Activity Knowledge Engine (HAKE), exhibits superior generalization ability and performance upon canonical methods on challenging benchmarks. Code and data are available at http://hake-mvig.cn/.
SuctionNet-1Billion: A Large-Scale Benchmark for Suction Grasping
Mar 23, 2021



Suction is an important solution for the longstanding robotic grasping problem. Compared with other kinds of grasping, suction grasping is easier to represent and often more reliable in practice. Though preferred in many scenarios, it is not fully investigated and lacks sufficient training data and evaluation benchmarks. To address that, firstly, we propose a new physical model to analytically evaluate seal formation and wrench resistance of a suction grasping, which are two key aspects of grasp success. Secondly, a two-step methodology is adopted to generate annotations on a large-scale dataset collected in real-world cluttered scenarios. Thirdly, a standard online evaluation system is proposed to evaluate suction poses in continuous operation space, which can benchmark different algorithms fairly without the need of exhaustive labeling. Real-robot experiments are conducted to show that our annotations align well with real world. Meanwhile, we propose a method to predict numerous suction poses from an RGB-D image of a cluttered scene and demonstrate our superiority against several previous methods. Result analyses are further provided to help readers better understand the challenges in this area. Data and source code are publicly available at www.graspnet.net.
Three Steps to Multimodal Trajectory Prediction: Modality Clustering, Classification and Synthesis
Mar 22, 2021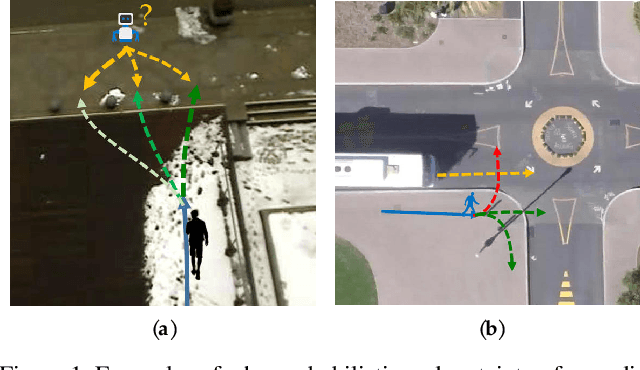
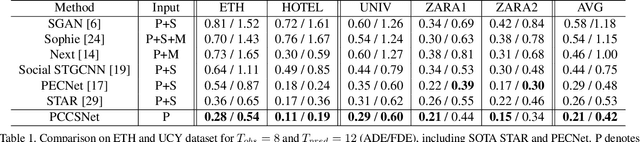
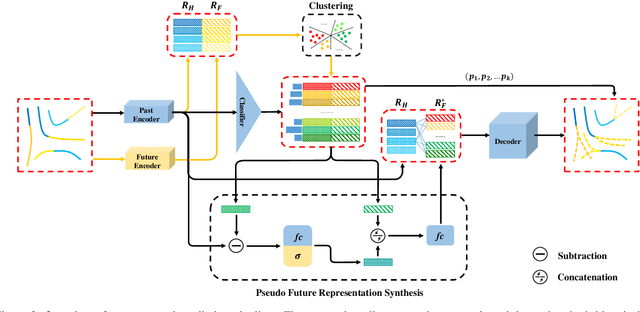
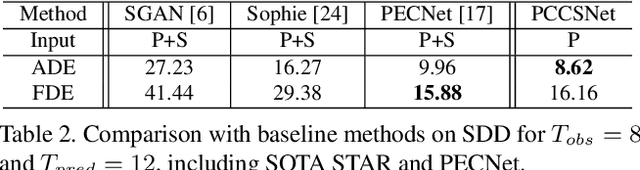
Multimodal prediction results are essential for trajectory prediction task as there is no single correct answer for the future. Previous frameworks can be divided into three categories: regression, generation and classification frameworks. However, these frameworks have weaknesses in different aspects so that they cannot model the multimodal prediction task comprehensively. In this paper, we present a novel insight along with a brand-new prediction framework by formulating multimodal prediction into three steps: modality clustering, classification and synthesis, and address the shortcomings of earlier frameworks. Exhaustive experiments on popular benchmarks have demonstrated that our proposed method surpasses state-of-the-art works even without introducing social and map information. Specifically, we achieve 19.2% and 20.8% improvement on ADE and FDE respectively on ETH/UCY dataset. Our code will be made publicly availabe.
RGB Matters: Learning 7-DoF Grasp Poses on Monocular RGBD Images
Mar 03, 2021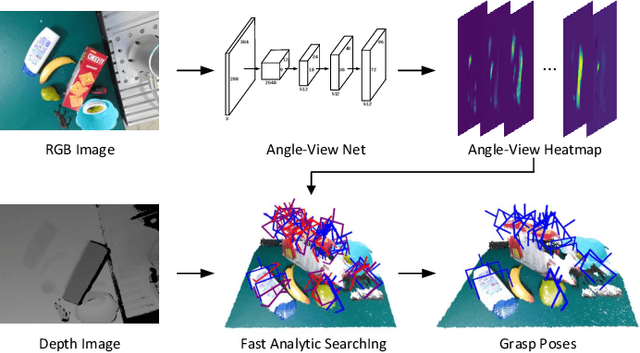
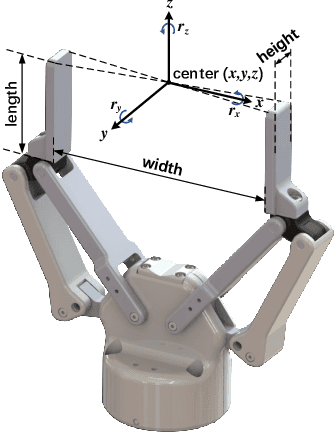
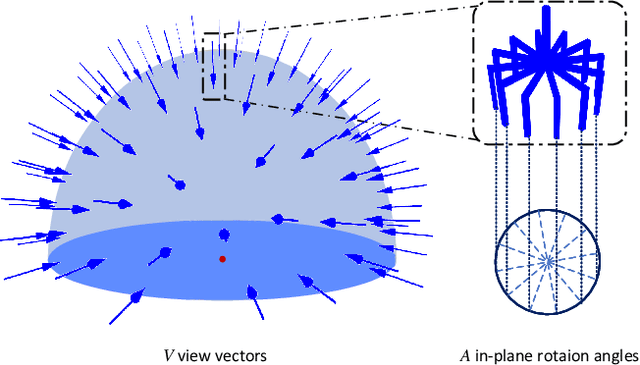
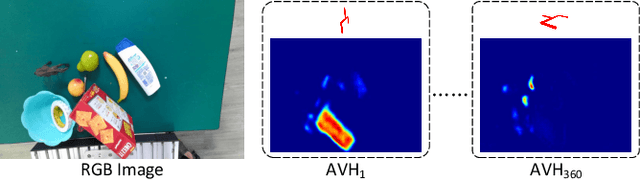
General object grasping is an important yet unsolved problem in the field of robotics. Most of the current methods either generate grasp poses with few DoF that fail to cover most of the success grasps, or only take the unstable depth image or point cloud as input which may lead to poor results in some cases. In this paper, we propose RGBD-Grasp, a pipeline that solves this problem by decoupling 7-DoF grasp detection into two sub-tasks where RGB and depth information are processed separately. In the first stage, an encoder-decoder like convolutional neural network Angle-View Net(AVN) is proposed to predict the SO(3) orientation of the gripper at every location of the image. Consequently, a Fast Analytic Searching(FAS) module calculates the opening width and the distance of the gripper to the grasp point. By decoupling the grasp detection problem and introducing the stable RGB modality, our pipeline alleviates the requirement for the high-quality depth image and is robust to depth sensor noise. We achieve state-of-the-art results on GraspNet-1Billion dataset compared with several baselines. Real robot experiments on a UR5 robot with an Intel Realsense camera and a Robotiq two-finger gripper show high success rates for both single object scenes and cluttered scenes. Our code and trained model will be made publicly available.
DecAug: Augmenting HOI Detection via Decomposition
Oct 02, 2020


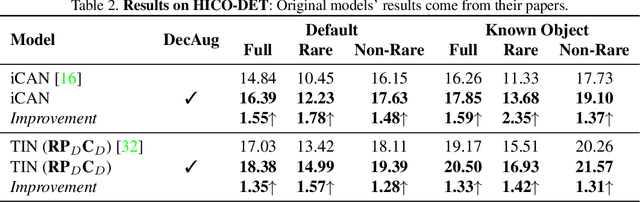
Human-object interaction (HOI) detection requires a large amount of annotated data. Current algorithms suffer from insufficient training samples and category imbalance within datasets. To increase data efficiency, in this paper, we propose an efficient and effective data augmentation method called DecAug for HOI detection. Based on our proposed object state similarity metric, object patterns across different HOIs are shared to augment local object appearance features without changing their state. Further, we shift spatial correlation between humans and objects to other feasible configurations with the aid of a pose-guided Gaussian Mixture Model while preserving their interactions. Experiments show that our method brings up to 3.3 mAP and 1.6 mAP improvements on V-COCO and HICODET dataset for two advanced models. Specifically, interactions with fewer samples enjoy more notable improvement. Our method can be easily integrated into various HOI detection models with negligible extra computational consumption. Our code will be made publicly available.
DIRV: Dense Interaction Region Voting for End-to-End Human-Object Interaction Detection
Oct 02, 2020
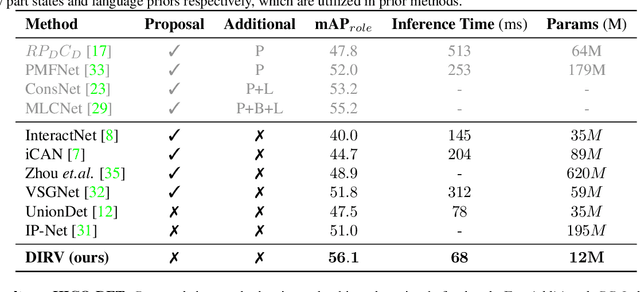

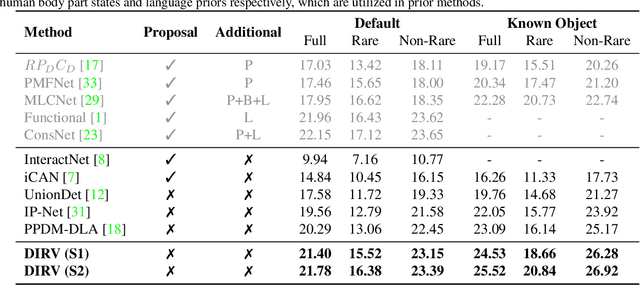
Recent years, human-object interaction (HOI) detection has achieved impressive advances. However, conventional two-stage methods are usually slow in inference. On the other hand, existing one-stage methods mainly focus on the union regions of interactions, which introduce unnecessary visual information as disturbances to HOI detection. To tackle the problems above, we propose a novel one-stage HOI detection approach DIRV in this paper, based on a new concept called interaction region for the HOI problem. Unlike previous methods, our approach concentrates on the densely sampled interaction regions across different scales for each human-object pair, so as to capture the subtle visual features that is most essential to the interaction. Moreover, in order to compensate for the detection flaws of a single interaction region, we introduce a novel voting strategy that makes full use of those overlapped interaction regions in place of conventional Non-Maximal Suppression (NMS). Extensive experiments on two popular benchmarks: V-COCO and HICO-DET show that our approach outperforms existing state-of-the-arts by a large margin with the highest inference speed and lightest network architecture. We achieved 56.1 mAP on V-COCO without addtional input. Our code will be made publicly available.
PaStaNet: Toward Human Activity Knowledge Engine
Apr 21, 2020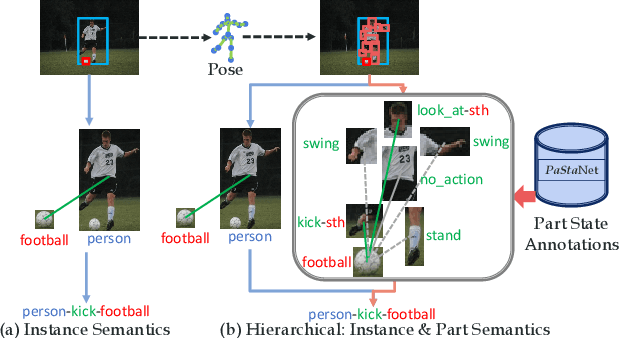
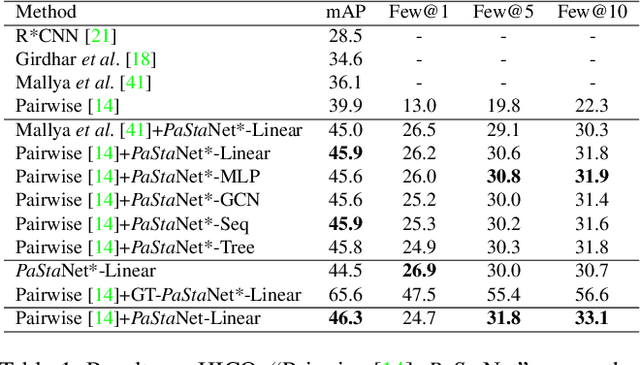
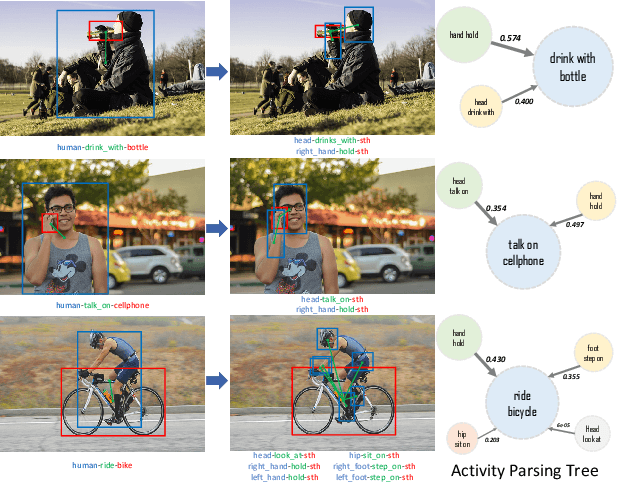
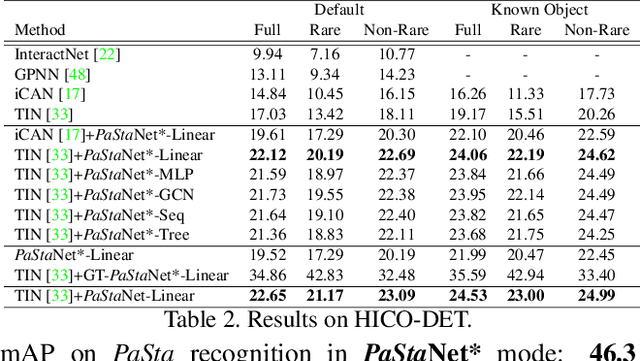
Existing image-based activity understanding methods mainly adopt direct mapping, i.e. from image to activity concepts, which may encounter performance bottleneck since the huge gap. In light of this, we propose a new path: infer human part states first and then reason out the activities based on part-level semantics. Human Body Part States (PaSta) are fine-grained action semantic tokens, e.g. <hand, hold, something>, which can compose the activities and help us step toward human activity knowledge engine. To fully utilize the power of PaSta, we build a large-scale knowledge base PaStaNet, which contains 7M+ PaSta annotations. And two corresponding models are proposed: first, we design a model named Activity2Vec to extract PaSta features, which aim to be general representations for various activities. Second, we use a PaSta-based Reasoning method to infer activities. Promoted by PaStaNet, our method achieves significant improvements, e.g. 6.4 and 13.9 mAP on full and one-shot sets of HICO in supervised learning, and 3.2 and 4.2 mAP on V-COCO and images-based AVA in transfer learning. Code and data are available at http://hake-mvig.cn/.