 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Dreamer: Automating Robotic Simulation and Trajectory Synthesis via Video Generation Priors
Mar 19, 2026Training generalist robots demands large-scale, diverse manipulation data, yet real-world collection is prohibitively expensive, and existing simulators are often constrained by fixed asset libraries and manual heuristics. To bridge this gap, we present V-Dreamer, a fully automated framework that generates open-vocabulary, simulation-ready manipulation environments and executable expert trajectories directly from natural language instructions. V-Dreamer employs a novel generative pipeline that constructs physically grounded 3D scenes using large language models and 3D generative models, validated by geometric constraints to ensure stable, collision-free layouts. Crucially, for behavior synthesis, we leverage video generation models as rich motion priors. These visual predictions are then mapped into executable robot trajectories via a robust Sim-to-Gen visual-kinematic alignment module utilizing CoTracker3 and VGGT. This pipeline supports high visual diversity and physical fidelity without manual intervention. To evaluate the generated data, we train imitation learning policies on synthesized trajectories encompassing diverse object and environment variations. Extensive evaluations on tabletop manipulation tasks using the Piper robotic arm demonstrate that our policies robustly generalize to unseen objects in simulation and achieve effective sim-to-real transfer, successfully manipulating novel real-world objects.
FineTec: Fine-Grained Action Recognition Under Temporal Corruption via Skeleton Decomposition and Sequence Completion
Dec 31, 2025Recognizing fine-grained actions from temporally corrupted skeleton sequences remains a significant challenge, particularly in real-world scenarios where online pose estimation often yields substantial missing data. Existing methods often struggle to accurately recover temporal dynamics and fine-grained spatial structures, resulting in the loss of subtle motion cues crucial for distinguishing similar actions. To address this, we propose FineTec, a unified framework for Fine-grained action recognition under Temporal Corruption. FineTec first restores a base skeleton sequence from corrupted input using context-aware completion with diverse temporal masking. Next, a skeleton-based spatial decomposition module partitions the skeleton into five semantic regions, further divides them into dynamic and static subgroups based on motion variance, and generates two augmented skeleton sequences via targeted perturbation. These, along with the base sequence, are then processed by a physics-driven estimation module, which utilizes Lagrangian dynamics to estimate joint accelerations. Finally, both the fused skeleton position sequence and the fused acceleration sequence are jointly fed into a GCN-based action recognition head. Extensive experiments on both coarse-grained (NTU-60, NTU-120) and fine-grained (Gym99, Gym288) benchmarks show that FineTec significantly outperforms previous methods under various levels of temporal corruption. Specifically, FineTec achieves top-1 accuracies of 89.1% and 78.1% on the challenging Gym99-severe and Gym288-severe settings, respectively, demonstrating its robustness and generalizability. Code and datasets could be found at https://smartdianlab.github.io/projects-FineTec/.
FinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
May 19, 2025Despite significant advances in video generation, synthesizing physically plausible human actions remains a persistent challenge, particularly in modeling fine-grained semantics and complex temporal dynamics. For instance, generating gymnastics routines such as "switch leap with 0.5 turn" poses substantial difficulties for current methods, often yielding unsatisfactory results. To bridge this gap, we propose FinePhys, a Fine-grained human action generation framework that incorporates Physics to obtain effective skeletal guidance. Specifically, FinePhys first estimates 2D poses in an online manner and then performs 2D-to-3D dimension lifting via in-context learning. To mitigate the instability and limited interpretability of purely data-driven 3D poses, we further introduce a physics-based motion re-estimation module governed by Euler-Lagrange equations, calculating joint accelerations via bidirectional temporal updating. The physically predicted 3D poses are then fused with data-driven ones, offering multi-scale 2D heatmap guidance for the diffusion process. Evaluated on three fine-grained action subsets from FineGym (FX-JUMP, FX-TURN, and FX-SALTO), FinePhys significantly outperforms competitive baselines. Comprehensive qualitative results further demonstrate FinePhys's ability to generate more natural and plausible fine-grained human actions.
PraNet-V2: Dual-Supervised Reverse Attention for Medical Image Segmentation
Apr 15, 2025


Accurate medical image segmentation is essential for effective diagnosis and treatment. Previously, PraNet-V1 was proposed to enhance polyp segmentation by introducing a reverse attention (RA) module that utilizes background information. However, PraNet-V1 struggles with multi-class segmentation tasks. To address this limitation, we propose PraNet-V2, which, compared to PraNet-V1, effectively performs a broader range of tasks including multi-class segmentation. At the core of PraNet-V2 is the Dual-Supervised Reverse Attention (DSRA) module, which incorporates explicit background supervision, independent background modeling, and semantically enriched attention fusion. Our PraNet-V2 framework demonstrates strong performance on four polyp segmentation datasets. Additionally, by integrating DSRA to iteratively enhance foreground segmentation results in three state-of-the-art semantic segmentation models, we achieve up to a 1.36% improvement in mean Dice score. Code is available at: https://github.com/ai4colonoscopy/PraNet-V2/tree/main/binary_seg/jittor.
SeFAR: Semi-supervised Fine-grained Action Recognition with Temporal Perturbation and Learning Stabilization
Jan 02, 2025



Human action understanding is crucial for the advancement of multimodal systems. While recent developments, driven by powerful large language models (LLMs), aim to be general enough to cover a wide range of categories, they often overlook the need for more specific capabilities. In this work, we address the more challenging task of Fine-grained Action Recognition (FAR), which focuses on detailed semantic labels within shorter temporal duration (e.g., "salto backward tucked with 1 turn"). Given the high costs of annotating fine-grained labels and the substantial data needed for fine-tuning LLMs, we propose to adopt semi-supervised learning (SSL). Our framework, SeFAR, incorporates several innovative designs to tackle these challenges. Specifically, to capture sufficient visual details, we construct Dual-level temporal elements as more effective representations, based on which we design a new strong augmentation strategy for the Teacher-Student learning paradigm through involving moderate temporal perturbation. Furthermore, to handle the high uncertainty within the teacher model's predictions for FAR, we propose the Adaptive Regulation to stabilize the learning process. Experiments show that SeFAR achieves state-of-the-art performance on two FAR datasets, FineGym and FineDiving, across various data scopes. It also outperforms other semi-supervised methods on two classical coarse-grained datasets, UCF101 and HMDB51. Further analysis and ablation studies validate the effectiveness of our designs. Additionally, we show that the features extracted by our SeFAR could largely promote the ability of multimodal foundation models to understand fine-grained and domain-specific semantics.
Just a Hint: Point-Supervised Camouflaged Object Detection
Aug 20, 2024



Camouflaged Object Detection (COD) demands models to expeditiously and accurately distinguish objects which conceal themselves seamlessly in the environment. Owing to the subtle differences and ambiguous boundaries, COD is not only a remarkably challenging task for models but also for human annotators, requiring huge efforts to provide pixel-wise annotations. To alleviate the heavy annotation burden, we propose to fulfill this task with the help of only one point supervision. Specifically, by swiftly clicking on each object, we first adaptively expand the original point-based annotation to a reasonable hint area. Then, to avoid partial localization around discriminative parts, we propose an attention regulator to scatter model attention to the whole object through partially masking labeled regions. Moreover, to solve the unstable feature representation of camouflaged objects under only point-based annotation, we perform unsupervised contrastive learning based on differently augmented image pairs (e.g. changing color or doing translation). On three mainstream COD benchmarks, experimental results show that our model outperforms several weakly-supervised methods by a large margin across various metrics.
FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs
Jul 02, 2024



Dynamic Facial Expression Recognition (DFER) is crucial for understanding human behavior. However, current methods exhibit limited performance mainly due to the scarcity of high-quality data, the insufficient utilization of facial dynamics, and the ambiguity of expression semantics, etc. To this end, we propose a novel framework, named Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs (FineCLIPER), incorporating the following novel designs: 1) To better distinguish between similar facial expressions, we extend the class labels to textual descriptions from both positive and negative aspects, and obtain supervision by calculating the cross-modal similarity based on the CLIP model; 2) Our FineCLIPER adopts a hierarchical manner to effectively mine useful cues from DFE videos. Specifically, besides directly embedding video frames as input (low semantic level), we propose to extract the face segmentation masks and landmarks based on each frame (middle semantic level) and utilize the Multi-modal Large Language Model (MLLM) to further generate detailed descriptions of facial changes across frames with designed prompts (high semantic level). Additionally, we also adopt Parameter-Efficient Fine-Tuning (PEFT) to enable efficient adaptation of large pre-trained models (i.e., CLIP) for this task. Our FineCLIPER achieves SOTA performance on the DFEW, FERV39k, and MAFW datasets in both supervised and zero-shot settings with few tunable parameters. Analysis and ablation studies further validate its effectiveness.
GaussianVTON: 3D Human Virtual Try-ON via Multi-Stage Gaussian Splatting Editing with Image Prompting
May 13, 2024



The increasing prominence of e-commerce has underscored the importance of Virtual Try-On (VTON). However, previous studies predominantly focus on the 2D realm and rely heavily on extensive data for training. Research on 3D VTON primarily centers on garment-body shape compatibility, a topic extensively covered in 2D VTON. Thanks to advances in 3D scene editing, a 2D diffusion model has now been adapted for 3D editing via multi-viewpoint editing. In this work, we propose GaussianVTON, an innovative 3D VTON pipeline integrating Gaussian Splatting (GS) editing with 2D VTON. To facilitate a seamless transition from 2D to 3D VTON, we propose, for the first time, the use of only images as editing prompts for 3D editing. To further address issues, e.g., face blurring, garment inaccuracy, and degraded viewpoint quality during editing, we devise a three-stage refinement strategy to gradually mitigate potential issues. Furthermore, we introduce a new editing strategy termed Edit Recall Reconstruction (ERR) to tackle the limitations of previous editing strategies in leading to complex geometric changes. Our comprehensive experiments demonstrate the superiority of GaussianVTON, offering a novel perspective on 3D VTON while also establishing a novel starting point for image-prompting 3D scene editing.
Tracking without Label: Unsupervised Multiple Object Tracking via Contrastive Similarity Learning
Sep 02, 2023



Unsupervised learning is a challenging task due to the lack of labels. Multiple Object Tracking (MOT), which inevitably suffers from mutual object interference, occlusion, etc., is even more difficult without label supervision. In this paper, we explore the latent consistency of sample features across video frames and propose an Unsupervised Contrastive Similarity Learning method, named UCSL, including three contrast modules: self-contrast, cross-contrast, and ambiguity contrast. Specifically, i) self-contrast uses intra-frame direct and inter-frame indirect contrast to obtain discriminative representations by maximizing self-similarity. ii) Cross-contrast aligns cross- and continuous-frame matching results, mitigating the persistent negative effect caused by object occlusion. And iii) ambiguity contrast matches ambiguous objects with each other to further increase the certainty of subsequent object association through an implicit manner. On existing benchmarks, our method outperforms the existing unsupervised methods using only limited help from ReID head, and even provides higher accuracy than lots of fully supervised methods.
Revisiting Skeleton-based Action Recognition
Apr 28, 2021
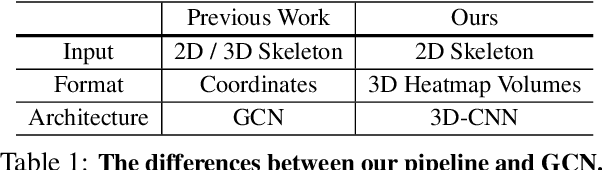

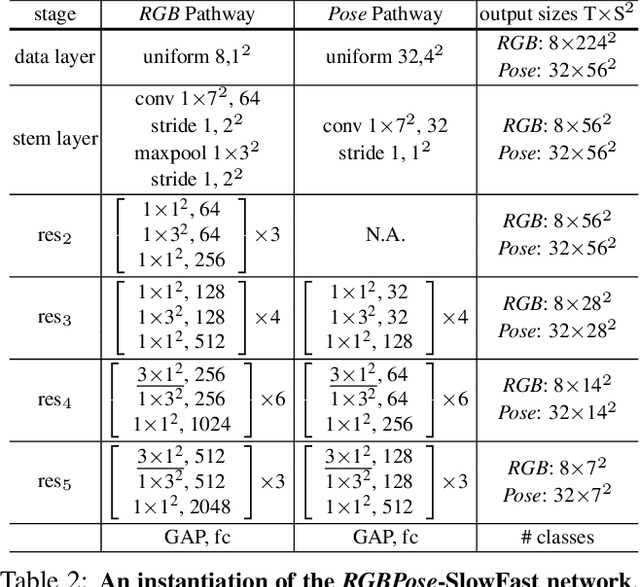
Human skeleton, as a compact representation of human action, has received increasing attention in recent years. Many skeleton-based action recognition methods adopt graph convolutional networks (GCN) to extract features on top of human skeletons. Despite the positive results shown in previous works, GCN-based methods are subject to limitations in robustness, interoperability, and scalability. In this work, we propose PoseC3D, a new approach to skeleton-based action recognition, which relies on a 3D heatmap stack instead of a graph sequence as the base representation of human skeletons. Compared to GCN-based methods, PoseC3D is more effective in learning spatiotemporal features, more robust against pose estimation noises, and generalizes better in cross-dataset settings. Also, PoseC3D can handle multiple-person scenarios without additional computation cost, and its features can be easily integrated with other modalities at early fusion stages, which provides a great design space to further boost the performance. On four challenging datasets, PoseC3D consistently obtains superior performance, when used alone on skeletons and in combination with the RGB modality.