 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Step Diffusion for Perceptual Image Compression
Feb 02, 2026Diffusion-based image compression methods have achieved notable progress, delivering high perceptual quality at low bitrates. However, their practical deployment is hindered by significant inference latency and heavy computational overhead, primarily due to the large number of denoising steps required during decoding. To address this problem, we propose a diffusion-based image compression method that requires only a single-step diffusion process, significantly improving inference speed. To enhance the perceptual quality of reconstructed images, we introduce a discriminator that operates on compact feature representations instead of raw pixels, leveraging the fact that features better capture high-level texture and structural details. Experimental results show that our method delivers comparable compression performance while offering a 46$\times$ faster inference speed compared to recent diffusion-based approaches. The source code and models are available at https://github.com/cheesejiang/OSDiff.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
FAR-AVIO: Fast and Robust Schur-Complement Based Acoustic-Visual-Inertial Fusion Odometry with Sensor Calibration
Dec 23, 2025
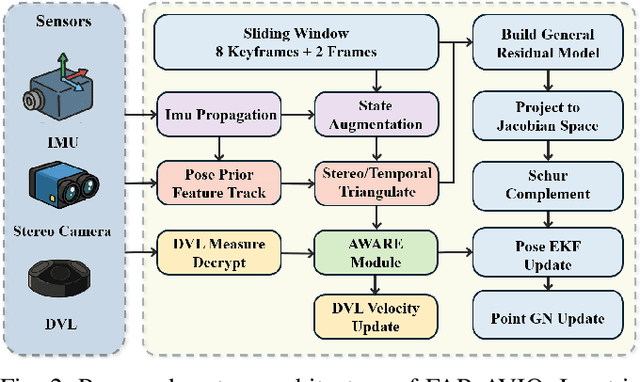
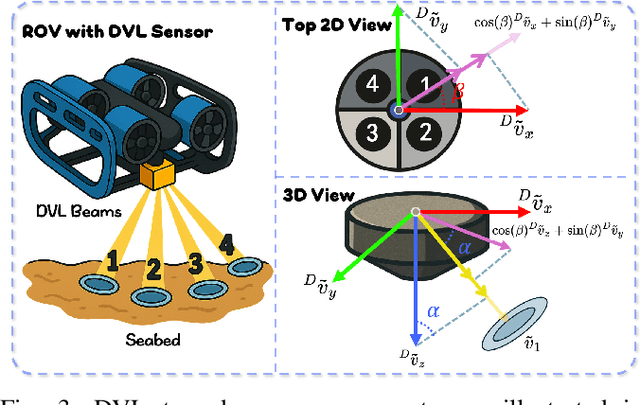
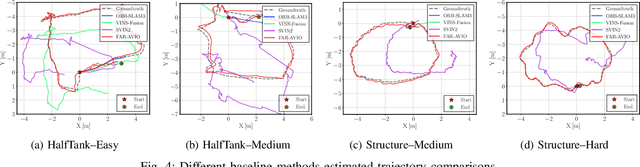
Underwater environments impose severe challenges to visual-inertial odometry systems, as strong light attenuation, marine snow and turbidity, together with weakly exciting motions, degrade inertial observability and cause frequent tracking failures over long-term operation. While tightly coupled acoustic-visual-inertial fusion, typically implemented through an acoustic Doppler Velocity Log (DVL) integrated with visual-inertial measurements, can provide accurate state estimation, the associated graph-based optimization is often computationally prohibitive for real-time deployment on resource-constrained platforms. Here we present FAR-AVIO, a Schur-Complement based, tightly coupled acoustic-visual-inertial odometry framework tailored for underwater robots. FAR-AVIO embeds a Schur complement formulation into an Extended Kalman Filter(EKF), enabling joint pose-landmark optimization for accuracy while maintaining constant-time updates by efficiently marginalizing landmark states. On top of this backbone, we introduce Adaptive Weight Adjustment and Reliability Evaluation(AWARE), an online sensor health module that continuously assesses the reliability of visual, inertial and DVL measurements and adaptively regulates their sigma weights, and we develop an efficient online calibration scheme that jointly estimates DVL-IMU extrinsics, without dedicated calibration manoeuvres. Numerical simulations and real-world underwater experiments consistently show that FAR-AVIO outperforms state-of-the-art underwater SLAM baselines in both localization accuracy and computational efficiency, enabling robust operation on low-power embedded platforms. Our implementation has been released as open source software at https://far-vido.gitbook.io/far-vido-docs.
INC: An Indirect Neural Corrector for Auto-Regressive Hybrid PDE Solvers
Nov 18, 2025



When simulating partial differential equations, hybrid solvers combine coarse numerical solvers with learned correctors. They promise accelerated simulations while adhering to physical constraints. However, as shown in our theoretical framework, directly applying learned corrections to solver outputs leads to significant autoregressive errors, which originate from amplified perturbations that accumulate during long-term rollouts, especially in chaotic regimes. To overcome this, we propose the Indirect Neural Corrector ($\mathrm{INC}$), which integrates learned corrections into the governing equations rather than applying direct state updates. Our key insight is that $\mathrm{INC}$ reduces the error amplification on the order of $Δt^{-1} + L$, where $Δt$ is the timestep and $L$ the Lipschitz constant. At the same time, our framework poses no architectural requirements and integrates seamlessly with arbitrary neural networks and solvers. We test $\mathrm{INC}$ in extensive benchmarks, covering numerous differentiable solvers, neural backbones, and test cases ranging from a 1D chaotic system to 3D turbulence. $\mathrm{INC}$ improves the long-term trajectory performance ($R^2$) by up to 158.7%, stabilizes blowups under aggressive coarsening, and for complex 3D turbulence cases yields speed-ups of several orders of magnitude. $\mathrm{INC}$ thus enables stable, efficient PDE emulation with formal error reduction, paving the way for faster scientific and engineering simulations with reliable physics guarantees. Our source code is available at https://github.com/tum-pbs/INC
Sparse3DPR: Training-Free 3D Hierarchical Scene Parsing and Task-Adaptive Subgraph Reasoning from Sparse RGB Views
Nov 11, 2025Recently, large language models (LLMs) have been explored widely for 3D scene understanding. Among them, training-free approaches are gaining attention for their flexibility and generalization over training-based methods. However, they typically struggle with accuracy and efficiency in practical deployment. To address the problems, we propose Sparse3DPR, a novel training-free framework for open-ended scene understanding, which leverages the reasoning capabilities of pre-trained LLMs and requires only sparse-view RGB inputs. Specifically, we introduce a hierarchical plane-enhanced scene graph that supports open vocabulary and adopts dominant planar structures as spatial anchors, which enables clearer reasoning chains and more reliable high-level inferences. Furthermore, we design a task-adaptive subgraph extraction method to filter query-irrelevant information dynamically, reducing contextual noise and improving 3D scene reasoning efficiency and accuracy. Experimental results demonstrate the superiority of Sparse3DPR, which achieves a 28.7% EM@1 improvement and a 78.2% speedup compared with ConceptGraphs on the Space3D-Bench. Moreover, Sparse3DPR obtains comparable performance to training-based methods on ScanQA, with additional real-world experiments confirming its robustness and generalization capability.
Token Communication in the Era of Large Models: An Information Bottleneck-Based Approach
Jul 02, 2025This letter proposes UniToCom, a unified token communication paradigm that treats tokens as the fundamental units for both processing and wireless transmission. Specifically, to enable efficient token representations, we propose a generative information bottleneck (GenIB) principle, which facilitates the learning of tokens that preserve essential information while supporting reliable generation across multiple modalities. By doing this, GenIB-based tokenization is conducive to improving the communication efficiency and reducing computational complexity. Additionally, we develop $\sigma$-GenIB to address the challenges of variance collapse in autoregressive modeling, maintaining representational diversity and stability. Moreover, we employ a causal Transformer-based multimodal large language model (MLLM) at the receiver to unify the processing of both discrete and continuous tokens under the next-token prediction paradigm. Simulation results validate the effectiveness and superiority of the proposed UniToCom compared to baselines under dynamic channel conditions. By integrating token processing with MLLMs, UniToCom enables scalable and generalizable communication in favor of multimodal understanding and generation, providing a potential solution for next-generation intelligent communications.
PICT -- A Differentiable, GPU-Accelerated Multi-Block PISO Solver for Simulation-Coupled Learning Tasks in Fluid Dynamics
May 22, 2025



Despite decades of advancements, the simulation of fluids remains one of the most challenging areas of in scientific computing. Supported by the necessity of gradient information in deep learning, differentiable simulators have emerged as an effective tool for optimization and learning in physics simulations. In this work, we present our fluid simulator PICT, a differentiable pressure-implicit solver coded in PyTorch with Graphics-processing-unit (GPU) support. We first verify the accuracy of both the forward simulation and our derived gradients in various established benchmarks like lid-driven cavities and turbulent channel flows before we show that the gradients provided by our solver can be used to learn complicated turbulence models in 2D and 3D. We apply both supervised and unsupervised training regimes using physical priors to match flow statistics. In particular, we learn a stable sub-grid scale (SGS) model for a 3D turbulent channel flow purely based on reference statistics. The low-resolution corrector trained with our solver runs substantially faster than the highly resolved references, while keeping or even surpassing their accuracy. Finally, we give additional insights into the physical interpretation of different solver gradients, and motivate a physically informed regularization technique. To ensure that the full potential of PICT can be leveraged, it is published as open source: https://github.com/tum-pbs/PICT.
Task-Agnostic Semantic Communications Relying on Information Bottleneck and Federated Meta-Learning
Apr 30, 2025



As a paradigm shift towards pervasive intelligence, semantic communication (SemCom) has shown great potentials to improve communication efficiency and provide user-centric services by delivering task-oriented semantic meanings. However, the exponential growth in connected devices, data volumes, and communication demands presents significant challenges for practical SemCom design, particularly in resource-constrained wireless networks. In this work, we first propose a task-agnostic SemCom (TASC) framework that can handle diverse tasks with multiple modalities. Aiming to explore the interplay between communications and intelligent tasks from the information-theoretical perspective, we leverage information bottleneck (IB) theory and propose a distributed multimodal IB (DMIB) principle to learn minimal and sufficient unimodal and multimodal information effectively by discarding redundancy while preserving task-related information. To further reduce the communication overhead, we develop an adaptive semantic feature transmission method under dynamic channel conditions. Then, TASC is trained based on federated meta-learning (FML) for rapid adaptation and generalization in wireless networks. To gain deep insights, we rigorously conduct theoretical analysis and devise resource management to accelerate convergence while minimizing the training latency and energy consumption. Moreover, we develop a joint user selection and resource allocation algorithm to address the non-convex problem with theoretical guarantees. Extensive simulation results validate the effectiveness and superiority of the proposed TASC compared to baselines.
A Lightweight Model for Perceptual Image Compression via Implicit Priors
Feb 19, 2025Perceptual image compression has shown strong potential for producing visually appealing results at low bitrates, surpassing classical standards and pixel-wise distortion-oriented neural methods. However, existing methods typically improve compression performance by incorporating explicit semantic priors, such as segmentation maps and textual features, into the encoder or decoder, which increases model complexity by adding parameters and floating-point operations. This limits the model's practicality, as image compression often occurs on resource-limited mobile devices. To alleviate this problem, we propose a lightweight perceptual Image Compression method using Implicit Semantic Priors (ICISP). We first develop an enhanced visual state space block that exploits local and global spatial dependencies to reduce redundancy. Since different frequency information contributes unequally to compression, we develop a frequency decomposition modulation block to adaptively preserve or reduce the low-frequency and high-frequency information. We establish the above blocks as the main modules of the encoder-decoder, and to further improve the perceptual quality of the reconstructed images, we develop a semantic-informed discriminator that uses implicit semantic priors from a pretrained DINOv2 encoder. Experiments on popular benchmarks show that our method achieves competitive compression performance and has significantly fewer network parameters and floating point operations than the existing state-of-the-art.
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.