 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGMiRAG: Intuition-Guided Retrieval-Augmented Generation with Adaptive Mining of In-Depth Memory
Feb 07, 2026Retrieval-augmented generation (RAG) equips large language models (LLMs) with reliable knowledge memory. To strengthen cross-text associations, recent research integrates graphs and hypergraphs into RAG to capture pairwise and multi-entity relations as structured links. However, their misaligned memory organization necessitates costly, disjointed retrieval. To address these limitations, we propose IGMiRAG, a framework inspired by human intuition-guided reasoning. It constructs a hierarchical heterogeneous hypergraph to align multi-granular knowledge, incorporating deductive pathways to simulate realistic memory structures. During querying, IGMiRAG distills intuitive strategies via a question parser to control mining depth and memory window, and activates instantaneous memories as anchors using dual-focus retrieval. Mirroring human intuition, the framework guides retrieval resource allocation dynamically. Furthermore, we design a bidirectional diffusion algorithm that navigates deductive paths to mine in-depth memories, emulating human reasoning processes. Extensive evaluations indicate IGMiRAG outperforms the state-of-the-art baseline by 4.8% EM and 5.0% F1 overall, with token costs adapting to task complexity (average 6.3k+, minimum 3.0k+). This work presents a cost-effective RAG paradigm that improves both efficiency and effectiveness.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Enhancing Cloud Network Resilience via a Robust LLM-Empowered Multi-Agent Reinforcement Learning Framework
Jan 12, 2026While virtualization and resource pooling empower cloud networks with structural flexibility and elastic scalability, they inevitably expand the attack surface and challenge cyber resilience. Reinforcement Learning (RL)-based defense strategies have been developed to optimize resource deployment and isolation policies under adversarial conditions, aiming to enhance system resilience by maintaining and restoring network availability. However, existing approaches lack robustness as they require retraining to adapt to dynamic changes in network structure, node scale, attack strategies, and attack intensity. Furthermore, the lack of Human-in-the-Loop (HITL) support limits interpretability and flexibility. To address these limitations, we propose CyberOps-Bots, a hierarchical multi-agent reinforcement learning framework empowered by Large Language Models (LLMs). Inspired by MITRE ATT&CK's Tactics-Techniques model, CyberOps-Bots features a two-layer architecture: (1) An upper-level LLM agent with four modules--ReAct planning, IPDRR-based perception, long-short term memory, and action/tool integration--performs global awareness, human intent recognition, and tactical planning; (2) Lower-level RL agents, developed via heterogeneous separated pre-training, execute atomic defense actions within localized network regions. This synergy preserves LLM adaptability and interpretability while ensuring reliable RL execution. Experiments on real cloud datasets show that, compared to state-of-the-art algorithms, CyberOps-Bots maintains network availability 68.5% higher and achieves a 34.7% jumpstart performance gain when shifting the scenarios without retraining. To our knowledge, this is the first study to establish a robust LLM-RL framework with HITL support for cloud defense. We will release our framework to the community, facilitating the advancement of robust and autonomous defense in cloud networks.
ORPR: An OR-Guided Pretrain-then-Reinforce Learning Model for Inventory Management
Dec 22, 2025



As the pursuit of synergy between Artificial Intelligence (AI) and Operations Research (OR) gains momentum in handling complex inventory systems, a critical challenge persists: how to effectively reconcile AI's adaptive perception with OR's structural rigor. To bridge this gap, we propose a novel OR-Guided "Pretrain-then-Reinforce" framework. To provide structured guidance, we propose a simulation-augmented OR model that generates high-quality reference decisions, implicitly capturing complex business constraints and managerial preferences. Leveraging these OR-derived decisions as foundational training labels, we design a domain-informed deep learning foundation model to establish foundational decision-making capabilities, followed by a reinforcement learning (RL) fine-tuning stage. Uniquely, we position RL as a deep alignment mechanism that enables the AI agent to internalize the optimality principles of OR, while simultaneously leveraging exploration for general policy refinement and allowing expert guidance for scenario-specific adaptation (e.g., promotional events). Validated through extensive numerical experiments and a field deployment at JD.com augmented by a Difference-in-Differences (DiD) analysis, our model significantly outperforms incumbent industrial practices, delivering real-world gains of a 5.27-day reduction in turnover and a 2.29% increase in in-stock rates, alongside a 29.95% decrease in holding costs. Contrary to the prevailing trend of brute-force model scaling, our study demonstrates that a lightweight, domain-informed model can deliver state-of-the-art performance and robust transferability when guided by structured OR logic. This approach offers a scalable and cost-effective paradigm for intelligent supply chain management, highlighting the value of deeply aligning AI with OR.
Cog-RAG: Cognitive-Inspired Dual-Hypergraph with Theme Alignment Retrieval-Augmented Generation
Nov 17, 2025Retrieval-Augmented Generation (RAG) enhances the response quality and domain-specific performance of large language models (LLMs) by incorporating external knowledge to combat hallucinations. In recent research, graph structures have been integrated into RAG to enhance the capture of semantic relations between entities. However, it primarily focuses on low-order pairwise entity relations, limiting the high-order associations among multiple entities. Hypergraph-enhanced approaches address this limitation by modeling multi-entity interactions via hyperedges, but they are typically constrained to inter-chunk entity-level representations, overlooking the global thematic organization and alignment across chunks. Drawing inspiration from the top-down cognitive process of human reasoning, we propose a theme-aligned dual-hypergraph RAG framework (Cog-RAG) that uses a theme hypergraph to capture inter-chunk thematic structure and an entity hypergraph to model high-order semantic relations. Furthermore, we design a cognitive-inspired two-stage retrieval strategy that first activates query-relevant thematic content from the theme hypergraph, and then guides fine-grained recall and diffusion in the entity hypergraph, achieving semantic alignment and consistent generation from global themes to local details. Our extensive experiments demonstrate that Cog-RAG significantly outperforms existing state-of-the-art baseline approaches.
* Accepted by AAAI 2026 main conference
Leveraging LLM-Based Agents for Intelligent Supply Chain Planning
Sep 04, 2025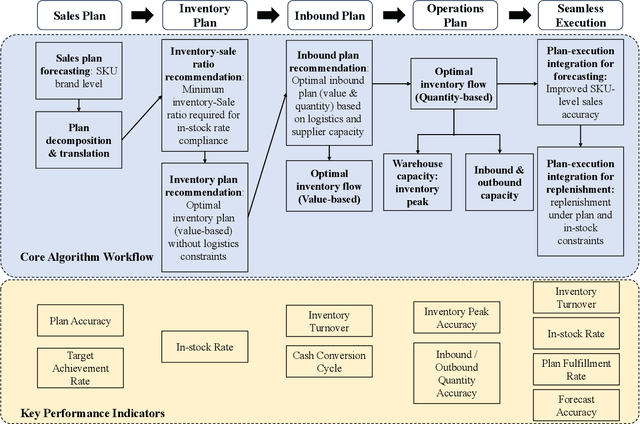
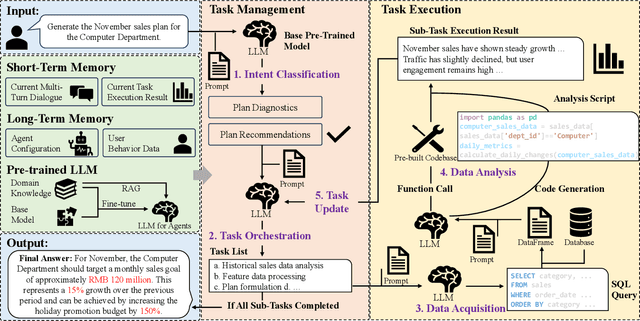
In supply chain management, planning is a critical concept. The movement of physical products across different categories, from suppliers to warehouse management, to sales, and logistics transporting them to customers, entails the involvement of many entities. It covers various aspects such as demand forecasting, inventory management, sales operations, and replenishment. How to collect relevant data from an e-commerce platform's perspective, formulate long-term plans, and dynamically adjust them based on environmental changes, while ensuring interpretability, efficiency, and reliability, is a practical and challenging problem. In recent years, the development of AI technologies, especially the rapid progress of large language models, has provided new tools to address real-world issues. In this work, we construct a Supply Chain Planning Agent (SCPA) framework that can understand domain knowledge, comprehend the operator's needs, decompose tasks, leverage or create new tools, and return evidence-based planning reports. We deploy this framework in JD.com's real-world scenario, demonstrating the feasibility of LLM-agent applications in the supply chain. It effectively reduced labor and improved accuracy, stock availability, and other key metrics.
Solving the Min-Max Multiple Traveling Salesmen Problem via Learning-Based Path Generation and Optimal Splitting
Aug 23, 2025This study addresses the Min-Max Multiple Traveling Salesmen Problem ($m^3$-TSP), which aims to coordinate tours for multiple salesmen such that the length of the longest tour is minimized. Due to its NP-hard nature, exact solvers become impractical under the assumption that $P \ne NP$. As a result, learning-based approaches have gained traction for their ability to rapidly generate high-quality approximate solutions. Among these, two-stage methods combine learning-based components with classical solvers, simplifying the learning objective. However, this decoupling often disrupts consistent optimization, potentially degrading solution quality. To address this issue, we propose a novel two-stage framework named \textbf{Generate-and-Split} (GaS), which integrates reinforcement learning (RL) with an optimal splitting algorithm in a joint training process. The splitting algorithm offers near-linear scalability with respect to the number of cities and guarantees optimal splitting in Euclidean space for any given path. To facilitate the joint optimization of the RL component with the algorithm, we adopt an LSTM-enhanced model architecture to address partial observability. Extensive experiments show that the proposed GaS framework significantly outperforms existing learning-based approaches in both solution quality and transferability.
In vivo 3D ultrasound computed tomography of musculoskeletal tissues with generative neural physics
Aug 17, 2025Ultrasound computed tomography (USCT) is a radiation-free, high-resolution modality but remains limited for musculoskeletal imaging due to conventional ray-based reconstructions that neglect strong scattering. We propose a generative neural physics framework that couples generative networks with physics-informed neural simulation for fast, high-fidelity 3D USCT. By learning a compact surrogate of ultrasonic wave propagation from only dozens of cross-modality images, our method merges the accuracy of wave modeling with the efficiency and stability of deep learning. This enables accurate quantitative imaging of in vivo musculoskeletal tissues, producing spatial maps of acoustic properties beyond reflection-mode images. On synthetic and in vivo data (breast, arm, leg), we reconstruct 3D maps of tissue parameters in under ten minutes, with sensitivity to biomechanical properties in muscle and bone and resolution comparable to MRI. By overcoming computational bottlenecks in strongly scattering regimes, this approach advances USCT toward routine clinical assessment of musculoskeletal disease.
SC2Arena and StarEvolve: Benchmark and Self-Improvement Framework for LLMs in Complex Decision-Making Tasks
Aug 14, 2025Evaluating large language models (LLMs) in complex decision-making is essential for advancing AI's ability for strategic planning and real-time adaptation. However, existing benchmarks for tasks like StarCraft II fail to capture the game's full complexity, such as its complete game context, diverse action spaces, and all playable races. To address this gap, we present SC2Arena, a benchmark that fully supports all playable races, low-level action spaces, and optimizes text-based observations to tackle spatial reasoning challenges. Complementing this, we introduce StarEvolve, a hierarchical framework that integrates strategic planning with tactical execution, featuring iterative self-correction and continuous improvement via fine-tuning on high-quality gameplay data. Its key components include a Planner-Executor-Verifier structure to break down gameplay, and a scoring system for selecting high-quality training samples. Comprehensive analysis using SC2Arena provides valuable insights into developing generalist agents that were not possible with previous benchmarks. Experimental results also demonstrate that our proposed StarEvolve achieves superior performance in strategic planning. Our code, environment, and algorithms are publicly available.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.