 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROMER: Expert Replacement and Router Calibration for Robust MoE LLMs on Analog Compute-in-Memory Systems
May 12, 2026Large language models (LLMs) with mixture-of-experts (MoE) architectures achieve remarkable scalability by sparsely activating a subset of experts per token, yet their frequent expert switching creates memory bandwidth bottlenecks that compute-in-memory (CIM) architectures are well-suited to mitigate. However, analog CIM systems suffer from inherent hardware imperfections that perturb stored weights, and its negative impact on MoE-based LLMs in noisy CIM environments remains unexplored. In this work, we present the first systematic investigation of MoE-based LLMs under noise model calibrated with real chip measurements, revealing that hardware noise critically disrupts expert load balance and renders clean-trained routing decisions consistently suboptimal. Based on these findings, we propose ROMER, a post-training calibration framework that (1) replaces underactivated experts with high-frequency ones to restore load balance, and (2) recalibrates router logits via percentile-based normalization to stabilize routing under noise. Extensive experiments across multiple benchmarks demonstrate that ROMER achieves up to 58.6\%, 58.8\%, and 59.8\% reduction in perplexity under real-chip noise conditions for DeepSeek-MoE, Qwen-MoE, and OLMoE, respectively, establishing its effectiveness and generalizability across diverse MoE architectures.
AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
May 19, 2025



Machine learning-based interatomic potentials and force fields depend critically on accurate atomic structures, yet such data are scarce due to the limited availability of experimentally resolved crystals. Although atomic-resolution electron microscopy offers a potential source of structural data, converting these images into simulation-ready formats remains labor-intensive and error-prone, creating a bottleneck for model training and validation. We introduce AutoMat, an end-to-end, agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts their physical properties. AutoMat combines pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation and property prediction via MatterSim, and coordinated orchestration across all stages. We propose the first dedicated STEM2Mat-Bench for this task and evaluate performance using lattice RMSD, formation energy MAE, and structure-matching success rate. By orchestrating external tool calls, AutoMat enables a text-only LLM to outperform vision-language models in this domain, achieving closed-loop reasoning throughout the pipeline. In large-scale experiments over 450 structure samples, AutoMat substantially outperforms existing multimodal large language models and tools. These results validate both AutoMat and STEM2Mat-Bench, marking a key step toward bridging microscopy and atomistic simulation in materials science.The code and dataset are publicly available at https://github.com/yyt-2378/AutoMat and https://huggingface.co/datasets/yaotianvector/STEM2Mat.
MatWheel: Addressing Data Scarcity in Materials Science Through Synthetic Data
Apr 12, 2025


Data scarcity and the high cost of annotation have long been persistent challenges in the field of materials science. Inspired by its potential in other fields like computer vision, we propose the MatWheel framework, which train the material property prediction model using the synthetic data generated by the conditional generative model. We explore two scenarios: fully-supervised and semi-supervised learning. Using CGCNN for property prediction and Con-CDVAE as the conditional generative model, experiments on two data-scarce material property datasets from Matminer database are conducted. Results show that synthetic data has potential in extreme data-scarce scenarios, achieving performance close to or exceeding that of real samples in all two tasks. We also find that pseudo-labels have little impact on generated data quality. Future work will integrate advanced models and optimize generation conditions to boost the effectiveness of the materials data flywheel.
Efficient Human Pose Estimation by Maximizing Fusion and High-Level Spatial Attention
Jul 29, 2021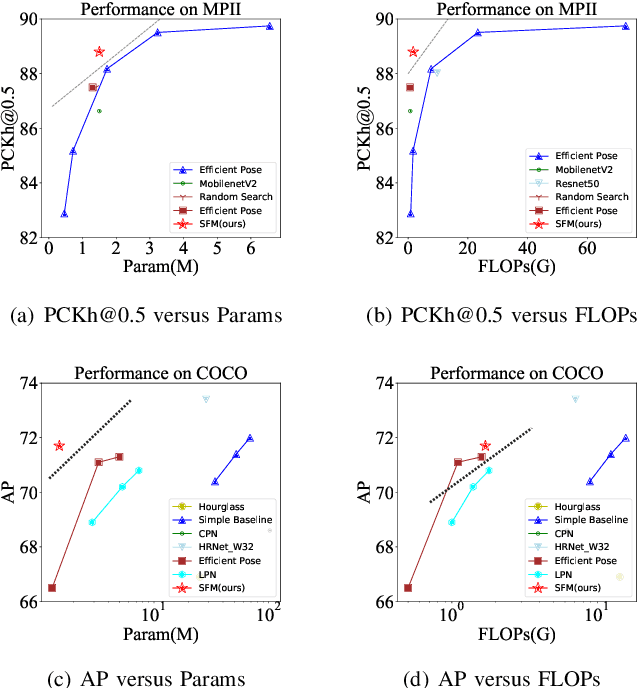
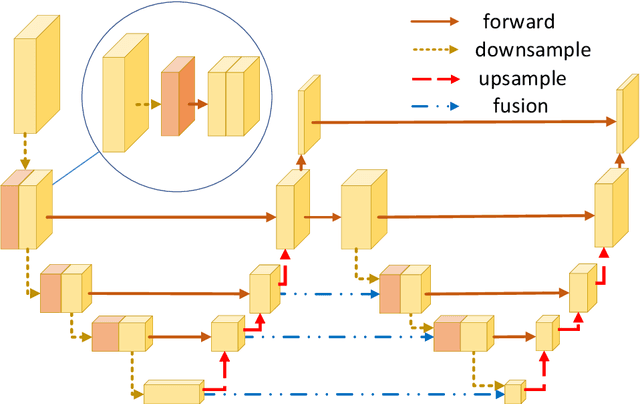
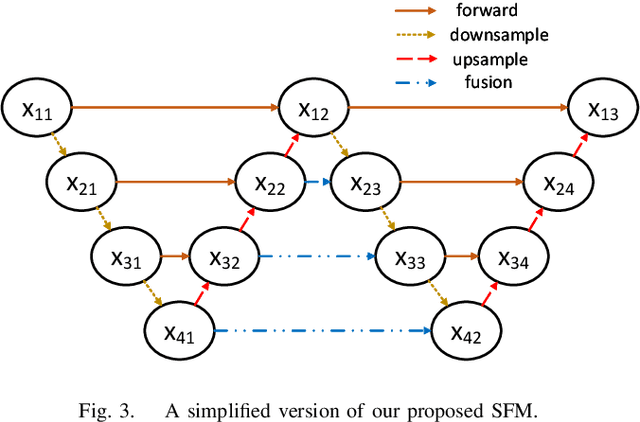
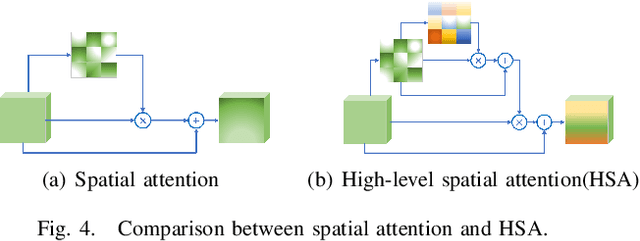
In this paper, we propose an efficient human pose estimation network -- SFM (slender fusion model) by fusing multi-level features and adding lightweight attention blocks -- HSA (High-Level Spatial Attention). Many existing methods on efficient network have already taken feature fusion into consideration, which largely boosts the performance. However, its performance is far inferior to large network such as ResNet and HRNet due to its limited fusion operation in the network. Specifically, we expand the number of fusion operation by building bridges between two pyramid frameworks without adding layers. Meanwhile, to capture long-range dependency, we propose a lightweight attention block -- HSA, which computes second-order attention map. In summary, SFM maximizes the number of feature fusion in a limited number of layers. HSA learns high precise spatial information by computing the attention of spatial attention map. With the help of SFM and HSA, our network is able to generate multi-level feature and extract precise global spatial information with little computing resource. Thus, our method achieve comparable or even better accuracy with less parameters and computational cost. Our SFM achieve 89.0 in PCKh@0.5, 42.0 in PCKh@0.1 on MPII validation set and 71.7 in AP, 90.7 in AP@0.5 on COCO validation with only 1.7G FLOPs and 1.5M parameters. The source code will be public soon.