 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIS-CoT: Breaking the Long-form Generation Collapse via Interleaved Structural Thinking
Jun 08, 2026Generating coherent and controllable long-form content remains a persistent challenge for Large Language Models (LLMs). While reasoning-enhanced models have demonstrated success in logic-intensive domains, our evaluation reveals that they suffer from a severe length collapse in open-ended writing, where performance degrades sharply as target lengths exceed 2,000 words. We attribute this failure to the limitation of static hierarchical planning, which struggles to provide dynamic guidance over extended contexts. To bridge this gap, we introduce the Interleaved Structural Chain-of-Thought (IS-CoT) framework. Unlike external agentic workflows, IS-CoT embeds a dynamic Plan-Write-Reflect cycle into the generation process, enabling continuous strategy adaptation and global alignment without additional assistance. Based on this framework, we construct a high-quality dataset of interleaved reasoning traces via a multi-teacher pipeline and train IS-Writer-8B. Experiments demonstrate that IS-Writer-8B achieves state-of-the-art performance on challenging long-form benchmarks (e.g., +3.08 vs. DeepSeek-V3.2 on LongBench-Write), exhibiting robust length compliance and coherence competitive with significantly larger proprietary models.
OneEval: Benchmarking LLM Knowledge-intensive Reasoning over Diverse Knowledge Bases
Jun 14, 2025



Large Language Models (LLMs) have demonstrated substantial progress on reasoning tasks involving unstructured text, yet their capabilities significantly deteriorate when reasoning requires integrating structured external knowledge such as knowledge graphs, code snippets, or formal logic. This limitation is partly due to the absence of benchmarks capable of systematically evaluating LLM performance across diverse structured knowledge modalities. To address this gap, we introduce \textbf{\textsc{OneEval}}, a comprehensive benchmark explicitly designed to assess the knowledge-intensive reasoning capabilities of LLMs across four structured knowledge modalities, unstructured text, knowledge graphs, code, and formal logic, and five critical domains (general knowledge, government, science, law, and programming). \textsc{OneEval} comprises 4,019 carefully curated instances and includes a challenging subset, \textsc{OneEval}\textsubscript{Hard}, consisting of 1,285 particularly difficult cases. Through extensive evaluation of 18 state-of-the-art open-source and proprietary LLMs, we establish three core findings: a) \emph{persistent limitations in structured reasoning}, with even the strongest model achieving only 32.2\% accuracy on \textsc{OneEval}\textsubscript{Hard}; b) \emph{performance consistently declines as the structural complexity of the knowledge base increases}, with accuracy dropping sharply from 53\% (textual reasoning) to 25\% (formal logic); and c) \emph{diminishing returns from extended reasoning chains}, highlighting the critical need for models to adapt reasoning depth appropriately to task complexity. We release the \textsc{OneEval} datasets, evaluation scripts, and baseline results publicly, accompanied by a leaderboard to facilitate ongoing advancements in structured knowledge reasoning.
CheMatAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 12, 2025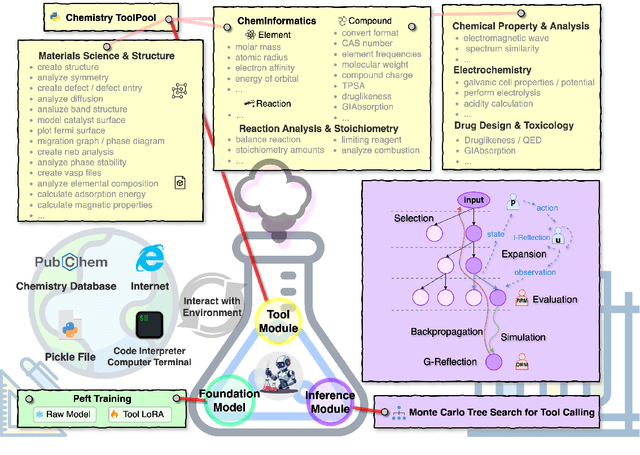
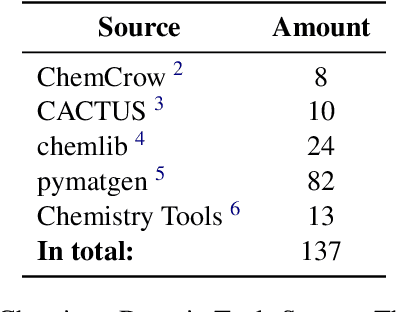
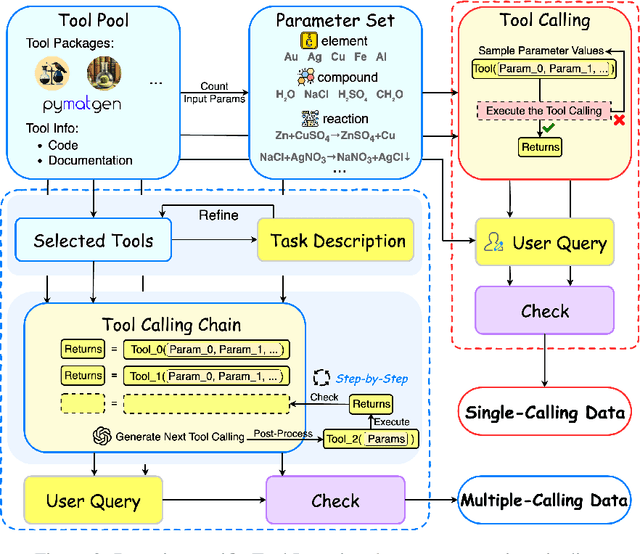

Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
Is Fine-Tuning an Effective Solution? Reassessing Knowledge Editing for Unstructured Data
Jun 11, 2025



Unstructured Knowledge Editing (UKE) is crucial for updating the relevant knowledge of large language models (LLMs). It focuses on unstructured inputs, such as long or free-form texts, which are common forms of real-world knowledge. Although previous studies have proposed effective methods and tested them, some issues exist: (1) Lack of Locality evaluation for UKE, and (2) Abnormal failure of fine-tuning (FT) based methods for UKE. To address these issues, we first construct two datasets, UnKEBench-Loc and AKEW-Loc (CF), by extending two existing UKE datasets with locality test data from the unstructured and structured views. This enables a systematic evaluation of the Locality of post-edited models. Furthermore, we identify four factors that may affect the performance of FT-based methods. Based on these factors, we conduct experiments to determine how the well-performing FT-based methods should be trained for the UKE task, providing a training recipe for future research. Our experimental results indicate that the FT-based method with the optimal setting (FT-UKE) is surprisingly strong, outperforming the existing state-of-the-art (SOTA). In batch editing scenarios, FT-UKE shows strong performance as well, with its advantage over SOTA methods increasing as the batch size grows, expanding the average metric lead from +6.78% to +10.80%
ChemAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 09, 2025Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
SELT: Self-Evaluation Tree Search for LLMs with Task Decomposition
Jun 09, 2025While Large Language Models (LLMs) have achieved remarkable success in a wide range of applications, their performance often degrades in complex reasoning tasks. In this work, we introduce SELT (Self-Evaluation LLM Tree Search), a novel framework that leverages a modified Monte Carlo Tree Search (MCTS) to enhance LLM reasoning without relying on external reward models. By redefining the Upper Confidence Bound scoring to align with intrinsic self-evaluation capabilities of LLMs and decomposing the inference process into atomic subtasks augmented with semantic clustering at each node, SELT effectively balances exploration and exploitation, reduces redundant reasoning paths, and mitigates hallucination. We validate our approach on challenging benchmarks, including the knowledge-based MMLU and the Tool Learning dataset Seal-Tools, where SELT achieves significant improvements in answer accuracy and reasoning robustness compared to baseline methods. Notably, our framework operates without task-specific fine-tuning, demonstrating strong generalizability across diverse reasoning tasks. Relevant results and code are available at https://github.com/fairyshine/SELT .
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025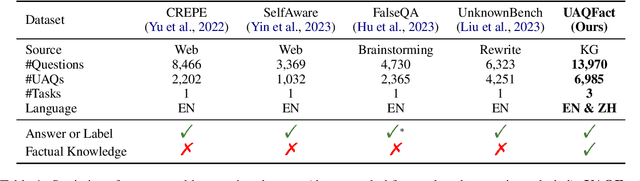



Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models
Mar 21, 2025Tool learning can further broaden the usage scenarios of large language models (LLMs). However most of the existing methods either need to finetune that the model can only use tools seen in the training data, or add tool demonstrations into the prompt with lower efficiency. In this paper, we present a new Tool Learning method Chain-of-Tools. It makes full use of the powerful semantic representation capability of frozen LLMs to finish tool calling in CoT reasoning with a huge and flexible tool pool which may contain unseen tools. Especially, to validate the effectiveness of our approach in the massive unseen tool scenario, we construct a new dataset SimpleToolQuestions. We conduct experiments on two numerical reasoning benchmarks (GSM8K-XL and FuncQA) and two knowledge-based question answering benchmarks (KAMEL and SimpleToolQuestions). Experimental results show that our approach performs better than the baseline. We also identify dimensions of the model output that are critical in tool selection, enhancing the model interpretability. Our code and data are available at: https://github.com/fairyshine/Chain-of-Tools .
Iterative Value Function Optimization for Guided Decoding
Mar 05, 2025While Reinforcement Learning from Human Feedback (RLHF) has become the predominant method for controlling language model outputs, it suffers from high computational costs and training instability. Guided decoding, especially value-guided methods, offers a cost-effective alternative by controlling outputs without re-training models. However, the accuracy of the value function is crucial for value-guided decoding, as inaccuracies can lead to suboptimal decision-making and degraded performance. Existing methods struggle with accurately estimating the optimal value function, leading to less effective control. We propose Iterative Value Function Optimization, a novel framework that addresses these limitations through two key components: Monte Carlo Value Estimation, which reduces estimation variance by exploring diverse trajectories, and Iterative On-Policy Optimization, which progressively improves value estimation through collecting trajectories from value-guided policies. Extensive experiments on text summarization, multi-turn dialogue, and instruction following demonstrate the effectiveness of value-guided decoding approaches in aligning language models. These approaches not only achieve alignment but also significantly reduce computational costs by leveraging principled value function optimization for efficient and effective control.
NesTools: A Dataset for Evaluating Nested Tool Learning Abilities of Large Language Models
Oct 15, 2024Large language models (LLMs) combined with tool learning have gained impressive results in real-world applications. During tool learning, LLMs may call multiple tools in nested orders, where the latter tool call may take the former response as its input parameters. However, current research on the nested tool learning capabilities is still under-explored, since the existing benchmarks lack of relevant data instances. To address this problem, we introduce NesTools to bridge the current gap in comprehensive nested tool learning evaluations. NesTools comprises a novel automatic data generation method to construct large-scale nested tool calls with different nesting structures. With manual review and refinement, the dataset is in high quality and closely aligned with real-world scenarios. Therefore, NesTools can serve as a new benchmark to evaluate the nested tool learning abilities of LLMs. We conduct extensive experiments on 22 LLMs, and provide in-depth analyses with NesTools, which shows that current LLMs still suffer from the complex nested tool learning task.