 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025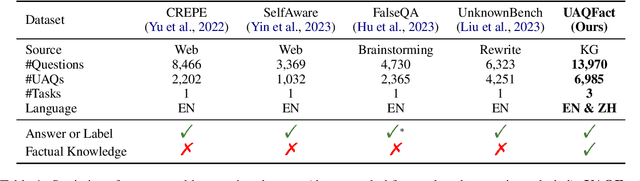



Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models
Mar 21, 2025Tool learning can further broaden the usage scenarios of large language models (LLMs). However most of the existing methods either need to finetune that the model can only use tools seen in the training data, or add tool demonstrations into the prompt with lower efficiency. In this paper, we present a new Tool Learning method Chain-of-Tools. It makes full use of the powerful semantic representation capability of frozen LLMs to finish tool calling in CoT reasoning with a huge and flexible tool pool which may contain unseen tools. Especially, to validate the effectiveness of our approach in the massive unseen tool scenario, we construct a new dataset SimpleToolQuestions. We conduct experiments on two numerical reasoning benchmarks (GSM8K-XL and FuncQA) and two knowledge-based question answering benchmarks (KAMEL and SimpleToolQuestions). Experimental results show that our approach performs better than the baseline. We also identify dimensions of the model output that are critical in tool selection, enhancing the model interpretability. Our code and data are available at: https://github.com/fairyshine/Chain-of-Tools .
Make a Choice! Knowledge Base Question Answering with In-Context Learning
May 23, 2023



Question answering over knowledge bases (KBQA) aims to answer factoid questions with a given knowledge base (KB). Due to the large scale of KB, annotated data is impossible to cover all fact schemas in KB, which poses a challenge to the generalization ability of methods that require a sufficient amount of annotated data. Recently, LLMs have shown strong few-shot performance in many NLP tasks. We expect LLM can help existing methods improve their generalization ability, especially in low-resource situations. In this paper, we present McL-KBQA, a framework that incorporates the few-shot ability of LLM into the KBQA method via ICL-based multiple choice and then improves the effectiveness of the QA tasks. Experimental results on two KBQA datasets demonstrate the competitive performance of McL-KBQA with strong improvements in generalization. We expect to explore a new way to QA tasks from KBQA in conjunction with LLM, how to generate answers normatively and correctly with strong generalization.