 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-step Noisy Label Mitigation
Oct 02, 2024



Mitigating the detrimental effects of noisy labels on the training process has become increasingly critical, as obtaining entirely clean or human-annotated samples for large-scale pre-training tasks is often impractical. Nonetheless, existing noise mitigation methods often encounter limitations in practical applications due to their task-specific design, model dependency, and significant computational overhead. In this work, we exploit the properties of high-dimensional orthogonality to identify a robust and effective boundary in cone space for separating clean and noisy samples. Building on this, we propose One-step Anti-Noise (OSA), a model-agnostic noisy label mitigation paradigm that employs an estimator model and a scoring function to assess the noise level of input pairs through just one-step inference, a cost-efficient process. We empirically demonstrate the superiority of OSA, highlighting its enhanced training robustness, improved task transferability, ease of deployment, and reduced computational costs across various benchmarks, models, and tasks. Our code is released at https://github.com/leolee99/OSA.
Multimodal LLM Enhanced Cross-lingual Cross-modal Retrieval
Sep 30, 2024



Cross-lingual cross-modal retrieval (CCR) aims to retrieve visually relevant content based on non-English queries, without relying on human-labeled cross-modal data pairs during training. One popular approach involves utilizing machine translation (MT) to create pseudo-parallel data pairs, establishing correspondence between visual and non-English textual data. However, aligning their representations poses challenges due to the significant semantic gap between vision and text, as well as the lower quality of non-English representations caused by pre-trained encoders and data noise. To overcome these challenges, we propose LECCR, a novel solution that incorporates the multi-modal large language model (MLLM) to improve the alignment between visual and non-English representations. Specifically, we first employ MLLM to generate detailed visual content descriptions and aggregate them into multi-view semantic slots that encapsulate different semantics. Then, we take these semantic slots as internal features and leverage them to interact with the visual features. By doing so, we enhance the semantic information within the visual features, narrowing the semantic gap between modalities and generating local visual semantics for subsequent multi-level matching. Additionally, to further enhance the alignment between visual and non-English features, we introduce softened matching under English guidance. This approach provides more comprehensive and reliable inter-modal correspondences between visual and non-English features. Extensive experiments on four CCR benchmarks, \ie Multi30K, MSCOCO, VATEX, and MSR-VTT-CN, demonstrate the effectiveness of our proposed method. Code: \url{https://github.com/LiJiaBei-7/leccr}.
HealthQ: Unveiling Questioning Capabilities of LLM Chains in Healthcare Conversations
Sep 28, 2024



In digital healthcare, large language models (LLMs) have primarily been utilized to enhance question-answering capabilities and improve patient interactions. However, effective patient care necessitates LLM chains that can actively gather information by posing relevant questions. This paper presents HealthQ, a novel framework designed to evaluate the questioning capabilities of LLM healthcare chains. We implemented several LLM chains, including Retrieval-Augmented Generation (RAG), Chain of Thought (CoT), and reflective chains, and introduced an LLM judge to assess the relevance and informativeness of the generated questions. To validate HealthQ, we employed traditional Natural Language Processing (NLP) metrics such as Recall-Oriented Understudy for Gisting Evaluation (ROUGE) and Named Entity Recognition (NER)-based set comparison, and constructed two custom datasets from public medical note datasets, ChatDoctor and MTS-Dialog. Our contributions are threefold: we provide the first comprehensive study on the questioning capabilities of LLMs in healthcare conversations, develop a novel dataset generation pipeline, and propose a detailed evaluation methodology.
Triple Point Masking
Sep 26, 2024Existing 3D mask learning methods encounter performance bottlenecks under limited data, and our objective is to overcome this limitation. In this paper, we introduce a triple point masking scheme, named TPM, which serves as a scalable framework for pre-training of masked autoencoders to achieve multi-mask learning for 3D point clouds. Specifically, we augment the baselines with two additional mask choices (i.e., medium mask and low mask) as our core insight is that the recovery process of an object can manifest in diverse ways. Previous high-masking schemes focus on capturing the global representation but lack the fine-grained recovery capability, so that the generated pre-trained weights tend to play a limited role in the fine-tuning process. With the support of the proposed TPM, available methods can exhibit more flexible and accurate completion capabilities, enabling the potential autoencoder in the pre-training stage to consider multiple representations of a single 3D object. In addition, an SVM-guided weight selection module is proposed to fill the encoder parameters for downstream networks with the optimal weight during the fine-tuning stage, maximizing linear accuracy and facilitating the acquisition of intricate representations for new objects. Extensive experiments show that the four baselines equipped with the proposed TPM achieve comprehensive performance improvements on various downstream tasks.
Extract-and-Abstract: Unifying Extractive and Abstractive Summarization within Single Encoder-Decoder Framework
Sep 18, 2024



Extract-then-Abstract is a naturally coherent paradigm to conduct abstractive summarization with the help of salient information identified by the extractive model. Previous works that adopt this paradigm train the extractor and abstractor separately and introduce extra parameters to highlight the extracted salients to the abstractor, which results in error accumulation and additional training costs. In this paper, we first introduce a parameter-free highlight method into the encoder-decoder framework: replacing the encoder attention mask with a saliency mask in the cross-attention module to force the decoder to focus only on salient parts of the input. A preliminary analysis compares different highlight methods, demonstrating the effectiveness of our saliency mask. We further propose the novel extract-and-abstract paradigm, ExtAbs, which jointly and seamlessly performs Extractive and Abstractive summarization tasks within single encoder-decoder model to reduce error accumulation. In ExtAbs, the vanilla encoder is augmented to extract salients, and the vanilla decoder is modified with the proposed saliency mask to generate summaries. Built upon BART and PEGASUS, experiments on three datasets show that ExtAbs can achieve superior performance than baselines on the extractive task and performs comparable, or even better than the vanilla models on the abstractive task.
FuXi-2.0: Advancing machine learning weather forecasting model for practical applications
Sep 11, 2024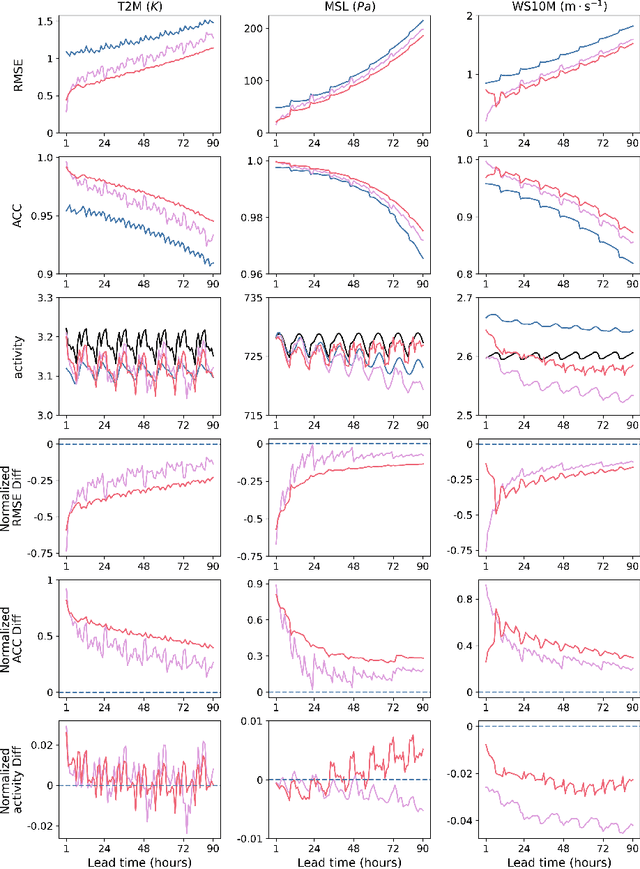
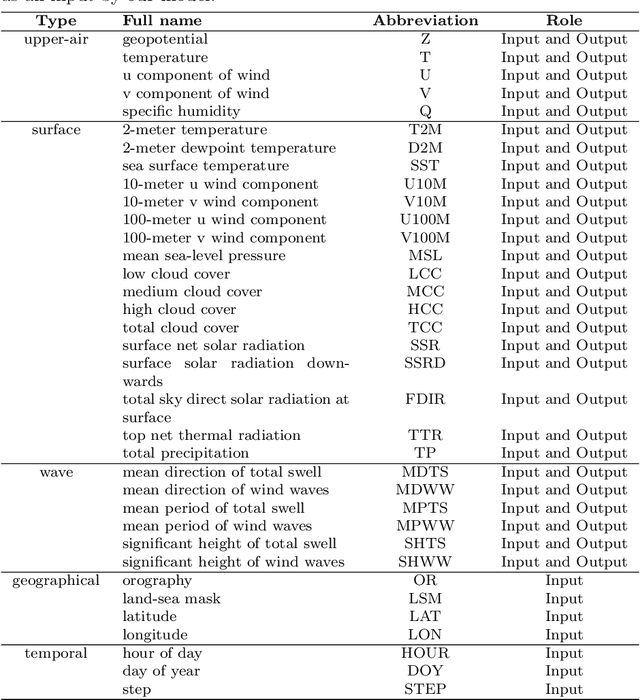
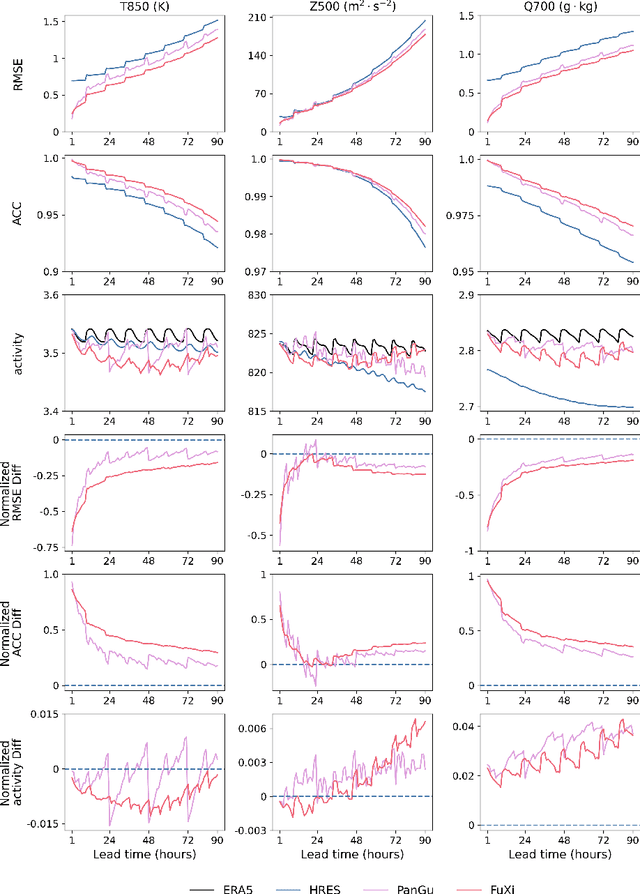
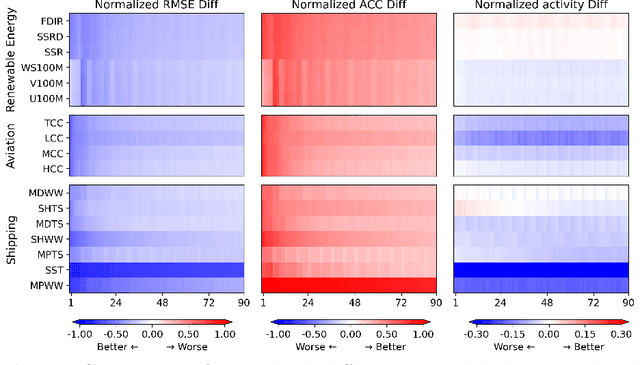
Machine learning (ML) models have become increasingly valuable in weather forecasting, providing forecasts that not only lower computational costs but often match or exceed the accuracy of traditional numerical weather prediction (NWP) models. Despite their potential, ML models typically suffer from limitations such as coarse temporal resolution, typically 6 hours, and a limited set of meteorological variables, limiting their practical applicability. To overcome these challenges, we introduce FuXi-2.0, an advanced ML model that delivers 1-hourly global weather forecasts and includes a comprehensive set of essential meteorological variables, thereby expanding its utility across various sectors like wind and solar energy, aviation, and marine shipping. Our study conducts comparative analyses between ML-based 1-hourly forecasts and those from the high-resolution forecast (HRES) of the European Centre for Medium-Range Weather Forecasts (ECMWF) for various practical scenarios. The results demonstrate that FuXi-2.0 consistently outperforms ECMWF HRES in forecasting key meteorological variables relevant to these sectors. In particular, FuXi-2.0 shows superior performance in wind power forecasting compared to ECMWF HRES, further validating its efficacy as a reliable tool for scenarios demanding precise weather forecasts. Additionally, FuXi-2.0 also integrates both atmospheric and oceanic components, representing a significant step forward in the development of coupled atmospheric-ocean models. Further comparative analyses reveal that FuXi-2.0 provides more accurate forecasts of tropical cyclone intensity than its predecessor, FuXi-1.0, suggesting that there are benefits of an atmosphere-ocean coupled model over atmosphere-only models.
Modified Meta-Thompson Sampling for Linear Bandits and Its Bayes Regret Analysis
Sep 11, 2024


Meta-learning is characterized by its ability to learn how to learn, enabling the adaptation of learning strategies across different tasks. Recent research introduced the Meta-Thompson Sampling (Meta-TS), which meta-learns an unknown prior distribution sampled from a meta-prior by interacting with bandit instances drawn from it. However, its analysis was limited to Gaussian bandit. The contextual multi-armed bandit framework is an extension of the Gaussian Bandit, which challenges agent to utilize context vectors to predict the most valuable arms, optimally balancing exploration and exploitation to minimize regret over time. This paper introduces Meta-TSLB algorithm, a modified Meta-TS for linear contextual bandits. We theoretically analyze Meta-TSLB and derive an $ O((m+\log(m))\sqrt{n\log(n)})$ bound on its Bayes regret, in which $m$ represents the number of bandit instances, and $n$ the number of rounds of Thompson Sampling. Additionally, our work complements the analysis of Meta-TS for linear contextual bandits. The performance of Meta-TSLB is evaluated experimentally under different settings, and we experimente and analyze the generalization capability of Meta-TSLB, showcasing its potential to adapt to unseen instances.
Attention-Based Beamformer For Multi-Channel Speech Enhancement
Sep 10, 2024



Minimum Variance Distortionless Response (MVDR) is a classical adaptive beamformer that theoretically ensures the distortionless transmission of signals in the target direction. Its performance in noise reduction actually depends on the accuracy of the noise spatial covariance matrix (SCM) estimate. Although recent deep learning has shown remarkable performance in multi-channel speech enhancement, the property of distortionless response still makes MVDR highly popular in real applications. In this paper, we propose an attention-based mechanism to calculate the speech and noise SCM and then apply MVDR to obtain the enhanced speech. Moreover, a deep learning architecture using the inplace convolution operator and frequency-independent LSTM has proven effective in facilitating SCM estimation. The model is optimized in an end-to-end manner. Experimental results indicate that the proposed method is extremely effective in tracking moving or stationary speakers under non-causal and causal conditions, outperforming other baselines. It is worth mentioning that our model has only 0.35 million parameters, making it easy to be deployed on edge devices.
Solve paint color effect prediction problem in trajectory optimization of spray painting robot using artificial neural network inspired by the Kubelka Munk model
Sep 06, 2024



Currently, the spray-painting robot trajectory planning technology aiming at spray painting quality mainly applies to single-color spraying. Conventional methods of optimizing the spray gun trajectory based on simulated thickness can only qualitatively reflect the color distribution, and can not simulate the color effect of spray painting at the pixel level. Therefore, it is not possible to accurately control the area covered by the color and the gradation of the edges of the area, and it is also difficult to deal with the situation where multiple colors of paint are sprayed in combination. To solve the above problems, this paper is inspired by the Kubelka-Munk model and combines the 3D machine vision method and artificial neural network to propose a spray painting color effect prediction method. The method is enabled to predict the execution effect of the spray gun trajectory with pixel-level accuracy from the dimension of the surface color of the workpiece after spray painting. On this basis, the method can be used to replace the traditional thickness simulation method to establish the objective function of the spray gun trajectory optimization problem, and thus solve the difficult problem of spray gun trajectory optimization for multi-color paint combination spraying. In this paper, the mathematical model of the spray painting color effect prediction problem is first determined through the analysis of the Kubelka-Munk paint film color rendering model, and at the same time, the spray painting color effect dataset is established with the help of the depth camera and point cloud processing algorithm. After that, the multilayer perceptron model was improved with the help of gating and residual structure and was used for the color prediction task. To verify ...
NYK-MS: A Well-annotated Multi-modal Metaphor and Sarcasm Understanding Benchmark on Cartoon-Caption Dataset
Sep 02, 2024



Metaphor and sarcasm are common figurative expressions in people's communication, especially on the Internet or the memes popular among teenagers. We create a new benchmark named NYK-MS (NewYorKer for Metaphor and Sarcasm), which contains 1,583 samples for metaphor understanding tasks and 1,578 samples for sarcasm understanding tasks. These tasks include whether it contains metaphor/sarcasm, which word or object contains metaphor/sarcasm, what does it satirize and why does it contains metaphor/sarcasm, all of the 7 tasks are well-annotated by at least 3 annotators. We annotate the dataset for several rounds to improve the consistency and quality, and use GUI and GPT-4V to raise our efficiency. Based on the benchmark, we conduct plenty of experiments. In the zero-shot experiments, we show that Large Language Models (LLM) and Large Multi-modal Models (LMM) can't do classification task well, and as the scale increases, the performance on other 5 tasks improves. In the experiments on traditional pre-train models, we show the enhancement with augment and alignment methods, which prove our benchmark is consistent with previous dataset and requires the model to understand both of the two modalities.