 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Digital Health Modeling with Adaptive Support Users
May 03, 2026Personalized models are essential in digital health because individuals exhibit substantial physiological and behavioral heterogeneity. Yet personalization is limited by scarce and noisy user-specific data. Most existing methods rely on population pretraining or data from similar users only, which can lead to biased transfer and weak generalization. We propose a unified personalization framework that trains a personal model using adaptively weighted support users, including both similar and dissimilar individuals. The objective integrates personal loss, similarity-weighted transfer from similar users, and contrastive regularization from dissimilar users to suppress misleading correlations. An iterative optimization algorithm jointly updates model parameters and user similarity weights. Experiments on six tasks across four real-world digital health datasets show consistent improvements over population and personalized baselines. The method achieves up to 10% lower RMSE on large-scale datasets and approximately 25% lower RMSE in low-data settings. The learned adaptive weights improve data efficiency and provide interpretable guidance for targeted data selection.
Evaluating Causal Discovery Algorithms for Path-Specific Fairness and Utility in Healthcare
Mar 16, 2026Causal discovery in health data faces evaluation challenges when ground truth is unknown. We address this by collaborating with experts to construct proxy ground-truth graphs, establishing benchmarks for synthetic Alzheimer's disease and heart failure clinical records data. We evaluate the Peter-Clark, Greedy Equivalence Search, and Fast Causal Inference algorithms on structural recovery and path-specific fairness decomposition, going beyond composite fairness scores. On synthetic data, Peter-Clark achieved the best structural recovery. On heart failure data, Fast Causal Inference achieved the highest utility. For path-specific effects, ejection fraction contributed 3.37 percentage points to the indirect effect in the ground truth. These differences drove variations in the fairness-utility ratio across algorithms. Our results highlight the need for graph-aware fairness evaluation and fine-grained path-specific analysis when deploying causal discovery in clinical applications.
Personalized Counterfactual Framework: Generating Potential Outcomes from Wearable Data
Aug 20, 2025Wearable sensor data offer opportunities for personalized health monitoring, yet deriving actionable insights from their complex, longitudinal data streams is challenging. This paper introduces a framework to learn personalized counterfactual models from multivariate wearable data. This enables exploring what-if scenarios to understand potential individual-specific outcomes of lifestyle choices. Our approach first augments individual datasets with data from similar patients via multi-modal similarity analysis. We then use a temporal PC (Peter-Clark) algorithm adaptation to discover predictive relationships, modeling how variables at time t-1 influence physiological changes at time t. Gradient Boosting Machines are trained on these discovered relationships to quantify individual-specific effects. These models drive a counterfactual engine projecting physiological trajectories under hypothetical interventions (e.g., activity or sleep changes). We evaluate the framework via one-step-ahead predictive validation and by assessing the plausibility and impact of interventions. Evaluation showed reasonable predictive accuracy (e.g., mean heart rate MAE 4.71 bpm) and high counterfactual plausibility (median 0.9643). Crucially, these interventions highlighted significant inter-individual variability in response to hypothetical lifestyle changes, showing the framework's potential for personalized insights. This work provides a tool to explore personalized health dynamics and generate hypotheses on individual responses to lifestyle changes.
FairCauseSyn: Towards Causally Fair LLM-Augmented Synthetic Data Generation
Jun 23, 2025Synthetic data generation creates data based on real-world data using generative models. In health applications, generating high-quality data while maintaining fairness for sensitive attributes is essential for equitable outcomes. Existing GAN-based and LLM-based methods focus on counterfactual fairness and are primarily applied in finance and legal domains. Causal fairness provides a more comprehensive evaluation framework by preserving causal structure, but current synthetic data generation methods do not address it in health settings. To fill this gap, we develop the first LLM-augmented synthetic data generation method to enhance causal fairness using real-world tabular health data. Our generated data deviates by less than 10% from real data on causal fairness metrics. When trained on causally fair predictors, synthetic data reduces bias on the sensitive attribute by 70% compared to real data. This work improves access to fair synthetic data, supporting equitable health research and healthcare delivery.
CDF-RAG: Causal Dynamic Feedback for Adaptive Retrieval-Augmented Generation
Apr 17, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced large language models (LLMs) in knowledge-intensive tasks by incorporating external knowledge retrieval. However, existing RAG frameworks primarily rely on semantic similarity and correlation-driven retrieval, limiting their ability to distinguish true causal relationships from spurious associations. This results in responses that may be factually grounded but fail to establish cause-and-effect mechanisms, leading to incomplete or misleading insights. To address this issue, we introduce Causal Dynamic Feedback for Adaptive Retrieval-Augmented Generation (CDF-RAG), a framework designed to improve causal consistency, factual accuracy, and explainability in generative reasoning. CDF-RAG iteratively refines queries, retrieves structured causal graphs, and enables multi-hop causal reasoning across interconnected knowledge sources. Additionally, it validates responses against causal pathways, ensuring logically coherent and factually grounded outputs. We evaluate CDF-RAG on four diverse datasets, demonstrating its ability to improve response accuracy and causal correctness over existing RAG-based methods. Our code is publicly available at https://github.com/ elakhatibi/CDF-RAG.
An LLM-Powered Agent for Physiological Data Analysis: A Case Study on PPG-based Heart Rate Estimation
Feb 18, 2025Large language models (LLMs) are revolutionizing healthcare by improving diagnosis, patient care, and decision support through interactive communication. More recently, they have been applied to analyzing physiological time-series like wearable data for health insight extraction. Existing methods embed raw numerical sequences directly into prompts, which exceeds token limits and increases computational costs. Additionally, some studies integrated features extracted from time-series in textual prompts or applied multimodal approaches. However, these methods often produce generic and unreliable outputs due to LLMs' limited analytical rigor and inefficiency in interpreting continuous waveforms. In this paper, we develop an LLM-powered agent for physiological time-series analysis aimed to bridge the gap in integrating LLMs with well-established analytical tools. Built on the OpenCHA, an open-source LLM-powered framework, our agent features an orchestrator that integrates user interaction, data sources, and analytical tools to generate accurate health insights. To evaluate its effectiveness, we implement a case study on heart rate (HR) estimation from Photoplethysmogram (PPG) signals using a dataset of PPG and Electrocardiogram (ECG) recordings in a remote health monitoring study. The agent's performance is benchmarked against OpenAI GPT-4o-mini and GPT-4o, with ECG serving as the gold standard for HR estimation. Results demonstrate that our agent significantly outperforms benchmark models by achieving lower error rates and more reliable HR estimations. The agent implementation is publicly available on GitHub.
Multimodal Sleep Stage and Sleep Apnea Classification Using Vision Transformer: A Multitask Explainable Learning Approach
Feb 18, 2025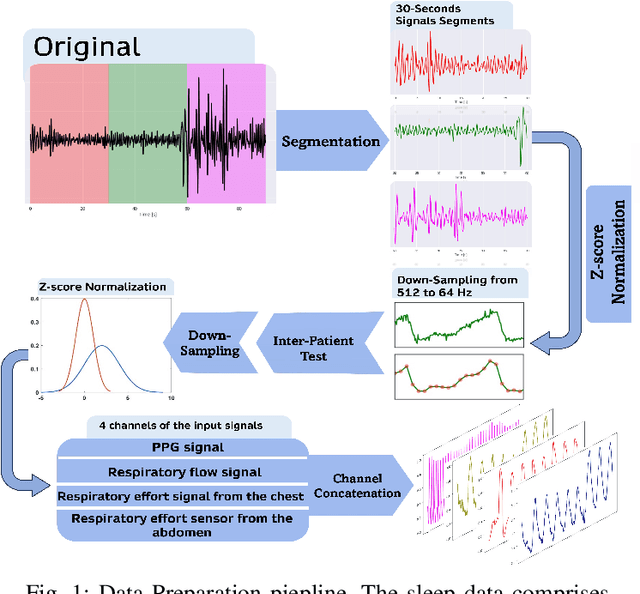
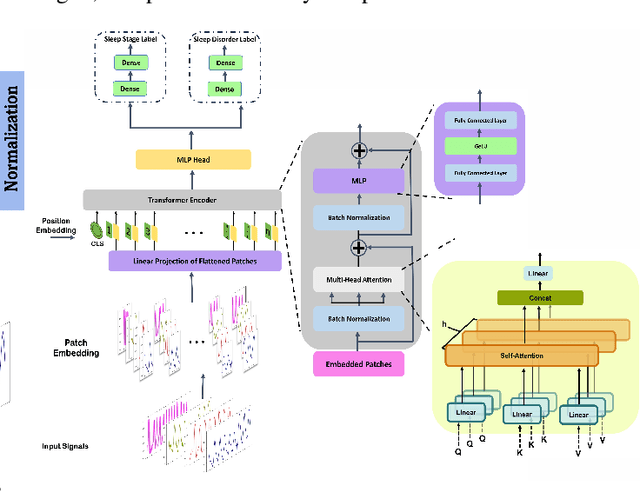

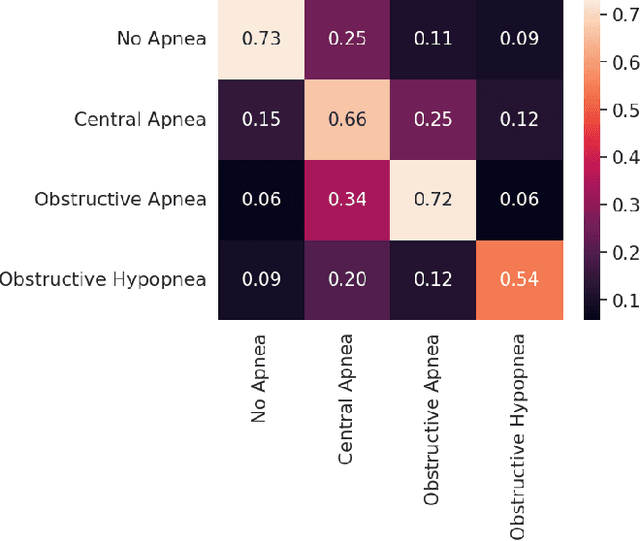
Sleep is an essential component of human physiology, contributing significantly to overall health and quality of life. Accurate sleep staging and disorder detection are crucial for assessing sleep quality. Studies in the literature have proposed PSG-based approaches and machine-learning methods utilizing single-modality signals. However, existing methods often lack multimodal, multilabel frameworks and address sleep stages and disorders classification separately. In this paper, we propose a 1D-Vision Transformer for simultaneous classification of sleep stages and sleep disorders. Our method exploits the sleep disorders' correlation with specific sleep stage patterns and performs a simultaneous identification of a sleep stage and sleep disorder. The model is trained and tested using multimodal-multilabel sensory data (including photoplethysmogram, respiratory flow, and respiratory effort signals). The proposed method shows an overall accuracy (cohen's Kappa) of 78% (0.66) for five-stage sleep classification and 74% (0.58) for sleep apnea classification. Moreover, we analyzed the encoder attention weights to clarify our models' predictions and investigate the influence different features have on the models' outputs. The result shows that identified patterns, such as respiratory troughs and peaks, make a higher contribution to the final classification process.
Skewed Memorization in Large Language Models: Quantification and Decomposition
Feb 03, 2025



Memorization in Large Language Models (LLMs) poses privacy and security risks, as models may unintentionally reproduce sensitive or copyrighted data. Existing analyses focus on average-case scenarios, often neglecting the highly skewed distribution of memorization. This paper examines memorization in LLM supervised fine-tuning (SFT), exploring its relationships with training duration, dataset size, and inter-sample similarity. By analyzing memorization probabilities over sequence lengths, we link this skewness to the token generation process, offering insights for estimating memorization and comparing it to established metrics. Through theoretical analysis and empirical evaluation, we provide a comprehensive understanding of memorization behaviors and propose strategies to detect and mitigate risks, contributing to more privacy-preserving LLMs.
HealthQ: Unveiling Questioning Capabilities of LLM Chains in Healthcare Conversations
Sep 28, 2024



In digital healthcare, large language models (LLMs) have primarily been utilized to enhance question-answering capabilities and improve patient interactions. However, effective patient care necessitates LLM chains that can actively gather information by posing relevant questions. This paper presents HealthQ, a novel framework designed to evaluate the questioning capabilities of LLM healthcare chains. We implemented several LLM chains, including Retrieval-Augmented Generation (RAG), Chain of Thought (CoT), and reflective chains, and introduced an LLM judge to assess the relevance and informativeness of the generated questions. To validate HealthQ, we employed traditional Natural Language Processing (NLP) metrics such as Recall-Oriented Understudy for Gisting Evaluation (ROUGE) and Named Entity Recognition (NER)-based set comparison, and constructed two custom datasets from public medical note datasets, ChatDoctor and MTS-Dialog. Our contributions are threefold: we provide the first comprehensive study on the questioning capabilities of LLMs in healthcare conversations, develop a novel dataset generation pipeline, and propose a detailed evaluation methodology.
Accuracy and Consistency of LLMs in the Registered Dietitian Exam: The Impact of Prompt Engineering and Knowledge Retrieval
Aug 06, 2024



Large language models (LLMs) are fundamentally transforming human-facing applications in the health and well-being domains: boosting patient engagement, accelerating clinical decision-making, and facilitating medical education. Although state-of-the-art LLMs have shown superior performance in several conversational applications, evaluations within nutrition and diet applications are still insufficient. In this paper, we propose to employ the Registered Dietitian (RD) exam to conduct a standard and comprehensive evaluation of state-of-the-art LLMs, GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro, assessing both accuracy and consistency in nutrition queries. Our evaluation includes 1050 RD exam questions encompassing several nutrition topics and proficiency levels. In addition, for the first time, we examine the impact of Zero-Shot (ZS), Chain of Thought (CoT), Chain of Thought with Self Consistency (CoT-SC), and Retrieval Augmented Prompting (RAP) on both accuracy and consistency of the responses. Our findings revealed that while these LLMs obtained acceptable overall performance, their results varied considerably with different prompts and question domains. GPT-4o with CoT-SC prompting outperformed the other approaches, whereas Gemini 1.5 Pro with ZS recorded the highest consistency. For GPT-4o and Claude 3.5, CoT improved the accuracy, and CoT-SC improved both accuracy and consistency. RAP was particularly effective for GPT-4o to answer Expert level questions. Consequently, choosing the appropriate LLM and prompting technique, tailored to the proficiency level and specific domain, can mitigate errors and potential risks in diet and nutrition chatbots.