 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025



This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025



Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
EAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025



Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
DSPO: Direct Semantic Preference Optimization for Real-World Image Super-Resolution
Apr 21, 2025
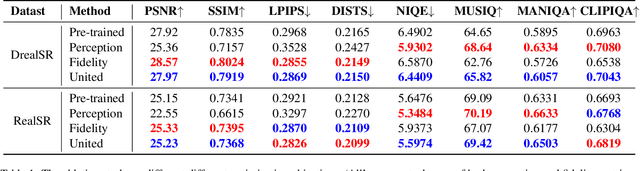
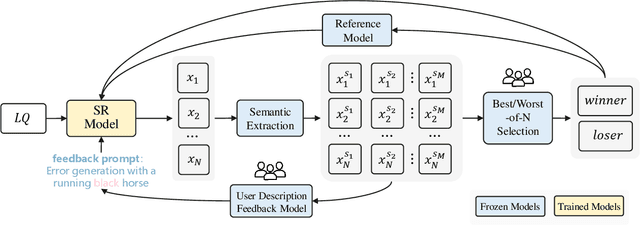

Recent advances in diffusion models have improved Real-World Image Super-Resolution (Real-ISR), but existing methods lack human feedback integration, risking misalignment with human preference and may leading to artifacts, hallucinations and harmful content generation. To this end, we are the first to introduce human preference alignment into Real-ISR, a technique that has been successfully applied in Large Language Models and Text-to-Image tasks to effectively enhance the alignment of generated outputs with human preferences. Specifically, we introduce Direct Preference Optimization (DPO) into Real-ISR to achieve alignment, where DPO serves as a general alignment technique that directly learns from the human preference dataset. Nevertheless, unlike high-level tasks, the pixel-level reconstruction objectives of Real-ISR are difficult to reconcile with the image-level preferences of DPO, which can lead to the DPO being overly sensitive to local anomalies, leading to reduced generation quality. To resolve this dichotomy, we propose Direct Semantic Preference Optimization (DSPO) to align instance-level human preferences by incorporating semantic guidance, which is through two strategies: (a) semantic instance alignment strategy, implementing instance-level alignment to ensure fine-grained perceptual consistency, and (b) user description feedback strategy, mitigating hallucinations through semantic textual feedback on instance-level images. As a plug-and-play solution, DSPO proves highly effective in both one-step and multi-step SR frameworks.
A Physics-guided Multimodal Transformer Path to Weather and Climate Sciences
Apr 19, 2025With the rapid development of machine learning in recent years, many problems in meteorology can now be addressed using AI models. In particular, data-driven algorithms have significantly improved accuracy compared to traditional methods. Meteorological data is often transformed into 2D images or 3D videos, which are then fed into AI models for learning. Additionally, these models often incorporate physical signals, such as temperature, pressure, and wind speed, to further enhance accuracy and interpretability. In this paper, we review several representative AI + Weather/Climate algorithms and propose a new paradigm where observational data from different perspectives, each with distinct physical meanings, are treated as multimodal data and integrated via transformers. Furthermore, key weather and climate knowledge can be incorporated through regularization techniques to further strengthen the model's capabilities. This new paradigm is versatile and can address a variety of tasks, offering strong generalizability. We also discuss future directions for improving model accuracy and interpretability.
Transferable text data distillation by trajectory matching
Apr 14, 2025



In the realm of large language model (LLM), as the size of large models increases, it also brings higher training costs. There is a urgent need to minimize the data size in LLM training. Compared with data selection method, the data distillation method aims to synthesize a small number of data samples to achieve the training effect of the full data set and has better flexibility. Despite its successes in computer vision, the discreteness of text data has hitherto stymied its exploration in natural language processing (NLP). In this work, we proposed a method that involves learning pseudo prompt data based on trajectory matching and finding its nearest neighbor ID to achieve cross-architecture transfer. During the distillation process, we introduce a regularization loss to improve the robustness of our distilled data. To our best knowledge, this is the first data distillation work suitable for text generation tasks such as instruction tuning. Evaluations on two benchmarks, including ARC-Easy and MMLU instruction tuning datasets, established the superiority of our distillation approach over the SOTA data selection method LESS. Furthermore, our method demonstrates a good transferability over LLM structures (i.e., OPT to Llama).
Autoregressive Image Generation Guided by Chains of Thought
Feb 26, 2025In the field of autoregressive (AR) image generation, models based on the 'next-token prediction' paradigm of LLMs have shown comparable performance to diffusion models by reducing inductive biases. However, directly applying LLMs to complex image generation can struggle with reconstructing the structure and details of the image, impacting the accuracy and stability of generation. Additionally, the 'next-token prediction' paradigm in the AR model does not align with the contextual scanning and logical reasoning processes involved in human visual perception, limiting effective image generation. Chain-of-Thought (CoT), as a key reasoning capability of LLMs, utilizes reasoning prompts to guide the model, improving reasoning performance on complex natural language process (NLP) tasks, enhancing accuracy and stability of generation, and helping the model maintain contextual coherence and logical consistency, similar to human reasoning. Inspired by CoT from the field of NLP, we propose autoregressive Image Generation with Thoughtful Reasoning (IGTR) to enhance autoregressive image generation. IGTR adds reasoning prompts without modifying the model structure or raster generation order. Specifically, we design specialized image-related reasoning prompts for AR image generation to simulate the human reasoning process, which enhances contextual reasoning by allowing the model to first perceive overall distribution information before generating the image, and improve generation stability by increasing the inference steps. Compared to the AR method without prompts, our method shows outstanding performance and achieves an approximate improvement of 20%.
Unshackling Context Length: An Efficient Selective Attention Approach through Query-Key Compression
Feb 20, 2025



Handling long-context sequences efficiently remains a significant challenge in large language models (LLMs). Existing methods for token selection in sequence extrapolation either employ a permanent eviction strategy or select tokens by chunk, which may lead to the loss of critical information. We propose Efficient Selective Attention (ESA), a novel approach that extends context length by efficiently selecting the most critical tokens at the token level to compute attention. ESA reduces the computational complexity of token selection by compressing query and key vectors into lower-dimensional representations. We evaluate ESA on long sequence benchmarks with maximum lengths up to 256k using open-source LLMs with context lengths of 8k and 32k. ESA outperforms other selective attention methods, especially in tasks requiring the retrieval of multiple pieces of information, achieving comparable performance to full-attention extrapolation methods across various tasks, with superior results in certain tasks.
Dynamic Frequency-Adaptive Knowledge Distillation for Speech Enhancement
Feb 07, 2025Deep learning-based speech enhancement (SE) models have recently outperformed traditional techniques, yet their deployment on resource-constrained devices remains challenging due to high computational and memory demands. This paper introduces a novel dynamic frequency-adaptive knowledge distillation (DFKD) approach to effectively compress SE models. Our method dynamically assesses the model's output, distinguishing between high and low-frequency components, and adapts the learning objectives to meet the unique requirements of different frequency bands, capitalizing on the SE task's inherent characteristics. To evaluate the DFKD's efficacy, we conducted experiments on three state-of-the-art models: DCCRN, ConTasNet, and DPTNet. The results demonstrate that our method not only significantly enhances the performance of the compressed model (student model) but also surpasses other logit-based knowledge distillation methods specifically for SE tasks.