 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayful DoggyBot: Learning Agile and Precise Quadrupedal Locomotion
Sep 30, 2024Quadrupedal animals have the ability to perform agile while accurate tasks: a trained dog can chase and catch a flying frisbee before it touches the ground; a cat alone at home can jump and grab the door handle accurately. However, agility and precision are usually a trade-off in robotics problems. Recent works in quadruped robots either focus on agile but not-so-accurate tasks, such as locomotion in challenging terrain, or accurate but not-so-fast tasks, such as using an additional manipulator to interact with objects. In this work, we aim at an accurate and agile task, catching a small object hanging above the robot. We mount a passive gripper in front of the robot chassis, so that the robot has to jump and catch the object with extreme precision. Our experiment shows that our system is able to jump and successfully catch the ball at 1.05m high in simulation and 0.8m high in the real world, while the robot is 0.3m high when standing.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Robust Robot Walker: Learning Agile Locomotion over Tiny Traps
Sep 12, 2024



Quadruped robots must exhibit robust walking capabilities in practical applications. In this work, we propose a novel approach that enables quadruped robots to pass various small obstacles, or "tiny traps". Existing methods often rely on exteroceptive sensors, which can be unreliable for detecting such tiny traps. To overcome this limitation, our approach focuses solely on proprioceptive inputs. We introduce a two-stage training framework incorporating a contact encoder and a classification head to learn implicit representations of different traps. Additionally, we design a set of tailored reward functions to improve both the stability of training and the ease of deployment for goal-tracking tasks. To benefit further research, we design a new benchmark for tiny trap task. Extensive experiments in both simulation and real-world settings demonstrate the effectiveness and robustness of our method. Project Page: https://robust-robot-walker.github.io/
Cross Anything: General Quadruped Robot Navigation through Complex Terrains
Jul 23, 2024The application of vision-language models (VLMs) has achieved impressive success in various robotics tasks, but there are few explorations for foundation models used in quadruped robot navigation. We introduce Cross Anything System (CAS), an innovative system composed of a high-level reasoning module and a low-level control policy, enabling the robot to navigate across complex 3D terrains and reach the goal position. For high-level reasoning and motion planning, we propose a novel algorithmic system taking advantage of a VLM, with a design of task decomposition and a closed-loop sub-task execution mechanism. For low-level locomotion control, we utilize the Probability Annealing Selection (PAS) method to train a control policy by reinforcement learning. Numerous experiments show that our whole system can accurately and robustly navigate across complex 3D terrains, and its strong generalization ability ensures the applications in diverse indoor and outdoor scenarios and terrains. Project page: https://cross-anything.github.io/
Explore the Potential of CLIP for Training-Free Open Vocabulary Semantic Segmentation
Jul 11, 2024CLIP, as a vision-language model, has significantly advanced Open-Vocabulary Semantic Segmentation (OVSS) with its zero-shot capabilities. Despite its success, its application to OVSS faces challenges due to its initial image-level alignment training, which affects its performance in tasks requiring detailed local context. Our study delves into the impact of CLIP's [CLS] token on patch feature correlations, revealing a dominance of "global" patches that hinders local feature discrimination. To overcome this, we propose CLIPtrase, a novel training-free semantic segmentation strategy that enhances local feature awareness through recalibrated self-correlation among patches. This approach demonstrates notable improvements in segmentation accuracy and the ability to maintain semantic coherence across objects.Experiments show that we are 22.3% ahead of CLIP on average on 9 segmentation benchmarks, outperforming existing state-of-the-art training-free methods.The code are made publicly available at: https://github.com/leaves162/CLIPtrase.
DISCO: Efficient Diffusion Solver for Large-Scale Combinatorial Optimization Problems
Jun 28, 2024Combinatorial Optimization (CO) problems are fundamentally crucial in numerous practical applications across diverse industries, characterized by entailing enormous solution space and demanding time-sensitive response. Despite significant advancements made by recent neural solvers, their limited expressiveness does not conform well to the multi-modal nature of CO landscapes. While some research has pivoted towards diffusion models, they require simulating a Markov chain with many steps to produce a sample, which is time-consuming and does not meet the efficiency requirement of real applications, especially at scale. We propose DISCO, an efficient DIffusion Solver for Combinatorial Optimization problems that excels in both solution quality and inference speed. DISCO's efficacy is two-pronged: Firstly, it achieves rapid denoising of solutions through an analytically solvable form, allowing for direct sampling from the solution space with very few reverse-time steps, thereby drastically reducing inference time. Secondly, DISCO enhances solution quality by restricting the sampling space to a more constrained, meaningful domain guided by solution residues, while still preserving the inherent multi-modality of the output probabilistic distributions. DISCO achieves state-of-the-art results on very large Traveling Salesman Problems with 10000 nodes and challenging Maximal Independent Set benchmarks, with its per-instance denoising time up to 44.8 times faster. Through further combining a divide-and-conquer strategy, DISCO can be generalized to solve arbitrary-scale problem instances off the shelf, even outperforming models trained specifically on corresponding scales.
GW-MoE: Resolving Uncertainty in MoE Router with Global Workspace Theory
Jun 18, 2024



Mixture-of-Experts (MoE) has been demonstrated as an efficient method to scale up models. By dynamically and sparsely selecting activated experts, MoE can effectively reduce computational costs. Despite the success, we observe that many tokens in the MoE models have uncertain routing results. These tokens have nearly equal scores for choosing each expert, and we demonstrate that this uncertainty can lead to incorrect selections. Inspired by the Global Workspace Theory (GWT), we propose a new fine-tuning method, GW-MoE, to address this issue. The core idea is to broadcast the uncertain tokens across experts during fine-tuning. Therefore, these tokens can acquire the necessary knowledge from any expert during inference and become less sensitive to the choice. GW-MoE does not introduce additional inference overhead. We validate that GW can mitigate the uncertain problem and consistently improve in different tasks (text classification, question answering, summarization, code generation, and mathematical problem solving) and model sizes (650M and 8B parameters).
Humanoid Parkour Learning
Jun 15, 2024



Parkour is a grand challenge for legged locomotion, even for quadruped robots, requiring active perception and various maneuvers to overcome multiple challenging obstacles. Existing methods for humanoid locomotion either optimize a trajectory for a single parkour track or train a reinforcement learning policy only to walk with a significant amount of motion references. In this work, we propose a framework for learning an end-to-end vision-based whole-body-control parkour policy for humanoid robots that overcomes multiple parkour skills without any motion prior. Using the parkour policy, the humanoid robot can jump on a 0.42m platform, leap over hurdles, 0.8m gaps, and much more. It can also run at 1.8m/s in the wild and walk robustly on different terrains. We test our policy in indoor and outdoor environments to demonstrate that it can autonomously select parkour skills while following the rotation command of the joystick. We override the arm actions and show that this framework can easily transfer to humanoid mobile manipulation tasks. Videos can be found at https://humanoid4parkour.github.io
TimeSieve: Extracting Temporal Dynamics through Information Bottlenecks
Jun 07, 2024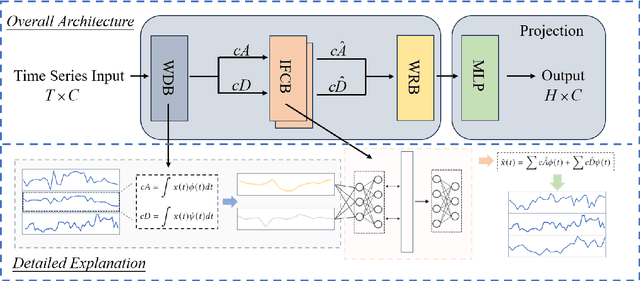
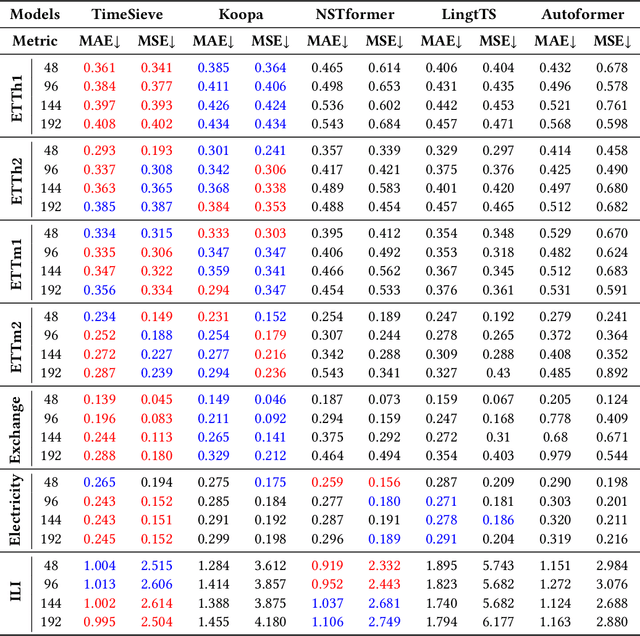
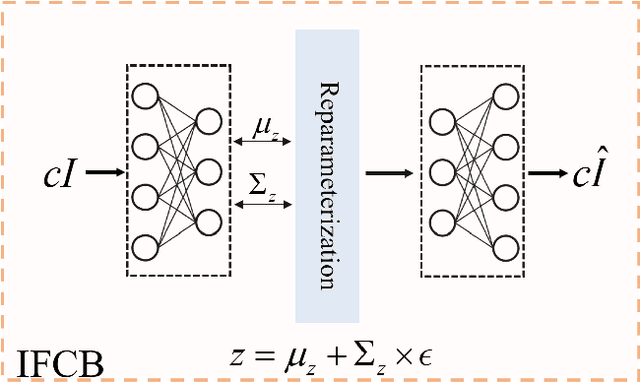
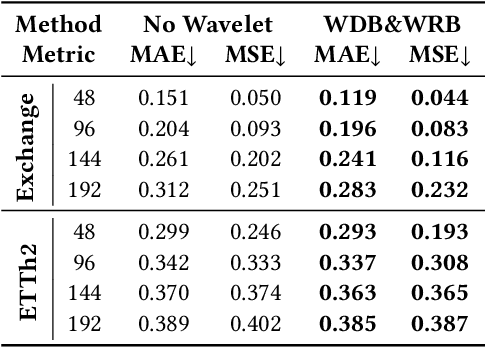
Time series forecasting has become an increasingly popular research area due to its critical applications in various real-world domains such as traffic management, weather prediction, and financial analysis. Despite significant advancements, existing models face notable challenges, including the necessity of manual hyperparameter tuning for different datasets, and difficulty in effectively distinguishing signal from redundant features in data characterized by strong seasonality. These issues hinder the generalization and practical application of time series forecasting models. To solve this issues, we propose an innovative time series forecasting model TimeSieve designed to address these challenges. Our approach employs wavelet transforms to preprocess time series data, effectively capturing multi-scale features without the need for additional parameters or manual hyperparameter tuning. Additionally, we introduce the information bottleneck theory that filters out redundant features from both detail and approximation coefficients, retaining only the most predictive information. This combination reduces significantly improves the model's accuracy. Extensive experiments demonstrate that our model outperforms existing state-of-the-art methods on 70\% of the datasets, achieving higher predictive accuracy and better generalization across diverse datasets. Our results validate the effectiveness of our approach in addressing the key challenges in time series forecasting, paving the way for more reliable and efficient predictive models in practical applications. The code for our model is available at https://github.com/xll0328/TimeSieve.
FTS: A Framework to Find a Faithful TimeSieve
May 30, 2024



The field of time series forecasting has garnered significant attention in recent years, prompting the development of advanced models like TimeSieve, which demonstrates impressive performance. However, an analysis reveals certain unfaithfulness issues, including high sensitivity to random seeds and minute input noise perturbations. Recognizing these challenges, we embark on a quest to define the concept of \textbf{\underline{F}aithful \underline{T}ime\underline{S}ieve \underline{(FTS)}}, a model that consistently delivers reliable and robust predictions. To address these issues, we propose a novel framework aimed at identifying and rectifying unfaithfulness in TimeSieve. Our framework is designed to enhance the model's stability and resilience, ensuring that its outputs are less susceptible to the aforementioned factors. Experimentation validates the effectiveness of our proposed framework, demonstrating improved faithfulness in the model's behavior. Looking forward, we plan to expand our experimental scope to further validate and optimize our algorithm, ensuring comprehensive faithfulness across a wide range of scenarios. Ultimately, we aspire to make this framework can be applied to enhance the faithfulness of not just TimeSieve but also other state-of-the-art temporal methods, thereby contributing to the reliability and robustness of temporal modeling as a whole.