 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
PyMIC: A deep learning toolkit for annotation-efficient medical image segmentation
Aug 19, 2022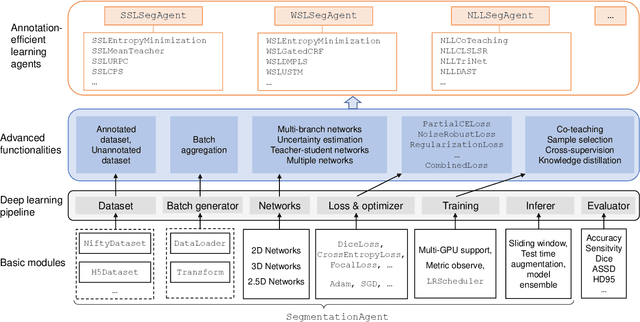
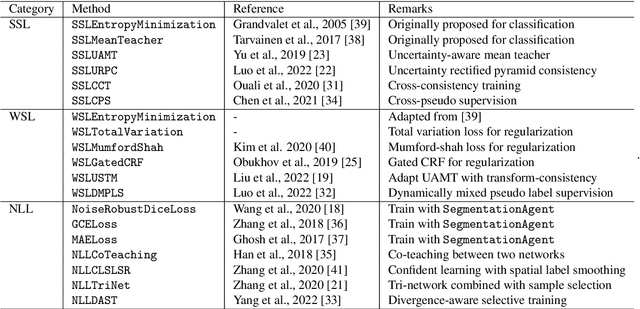
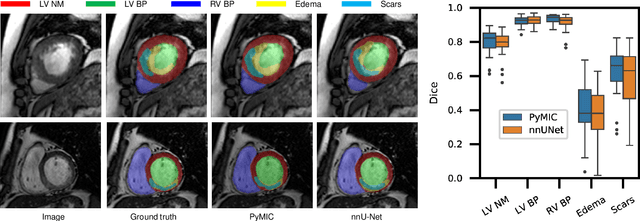
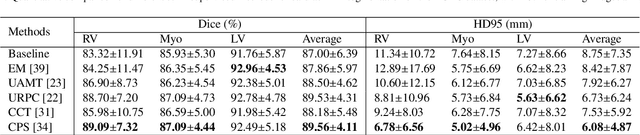
Background and Objective: Existing deep learning platforms for medical image segmentation mainly focus on fully supervised segmentation that assumes full and accurate pixel-level annotations are available. We aim to develop a new deep learning toolkit to support annotation-efficient learning for medical image segmentation, which can accelerate and simply the development of deep learning models with limited annotation budget, e.g., learning from partial, sparse or noisy annotations. Methods: Our proposed toolkit named PyMIC is a modular deep learning platform for medical image segmentation tasks. In addition to basic components that support development of high-performance models for fully supervised segmentation, it contains several advanced components that are tailored for learning from imperfect annotations, such as loading annotated and unannounced images, loss functions for unannotated, partially or inaccurately annotated images, and training procedures for co-learning between multiple networks, etc. PyMIC is built on the PyTorch framework and supports development of semi-supervised, weakly supervised and noise-robust learning methods for medical image segmentation. Results: We present four illustrative medical image segmentation tasks based on PyMIC: (1) Achieving competitive performance on fully supervised learning; (2) Semi-supervised cardiac structure segmentation with only 10% training images annotated; (3) Weakly supervised segmentation using scribble annotations; and (4) Learning from noisy labels for chest radiograph segmentation. Conclusions: The PyMIC toolkit is easy to use and facilitates efficient development of medical image segmentation models with imperfect annotations. It is modular and flexible, which enables researchers to develop high-performance models with low annotation cost. The source code is available at: https://github.com/HiLab-git/PyMIC.
Contrastive Semi-supervised Learning for Domain Adaptive Segmentation Across Similar Anatomical Structures
Aug 18, 2022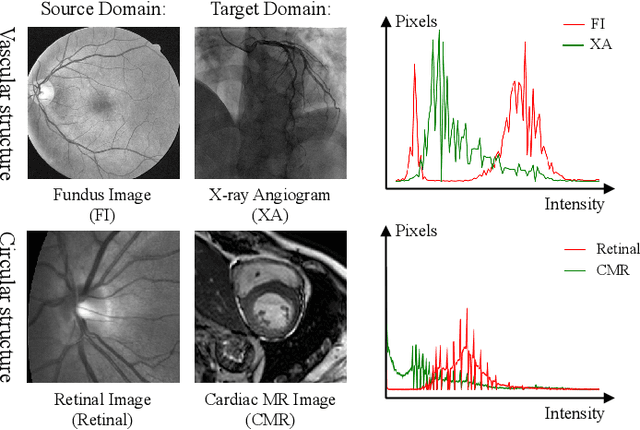
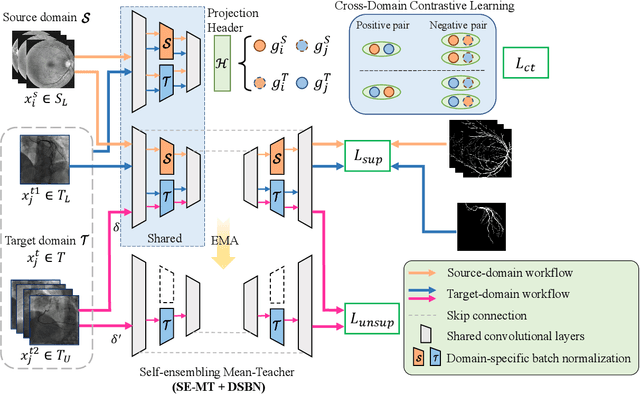
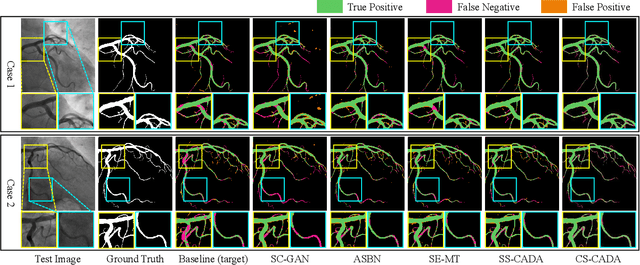
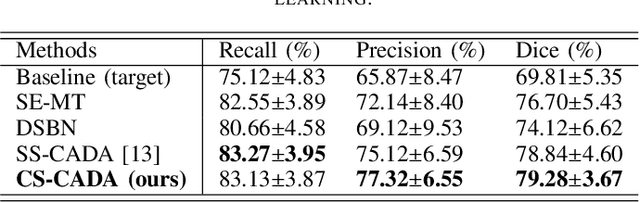
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance for medical image segmentation, yet need plenty of manual annotations for training. Semi-Supervised Learning (SSL) methods are promising to reduce the requirement of annotations, but their performance is still limited when the dataset size and the number of annotated images are small. Leveraging existing annotated datasets with similar anatomical structures to assist training has a potential for improving the model's performance. However, it is further challenged by the cross-anatomy domain shift due to the different appearance and even imaging modalities from the target structure. To solve this problem, we propose Contrastive Semi-supervised learning for Cross Anatomy Domain Adaptation (CS-CADA) that adapts a model to segment similar structures in a target domain, which requires only limited annotations in the target domain by leveraging a set of existing annotated images of similar structures in a source domain. We use Domain-Specific Batch Normalization (DSBN) to individually normalize feature maps for the two anatomical domains, and propose a cross-domain contrastive learning strategy to encourage extracting domain invariant features. They are integrated into a Self-Ensembling Mean-Teacher (SE-MT) framework to exploit unlabeled target domain images with a prediction consistency constraint. Extensive experiments show that our CS-CADA is able to solve the challenging cross-anatomy domain shift problem, achieving accurate segmentation of coronary arteries in X-ray images with the help of retinal vessel images and cardiac MR images with the help of fundus images, respectively, given only a small number of annotations in the target domain.
PA-Seg: Learning from Point Annotations for 3D Medical Image Segmentation using Contextual Regularization and Cross Knowledge Distillation
Aug 11, 2022
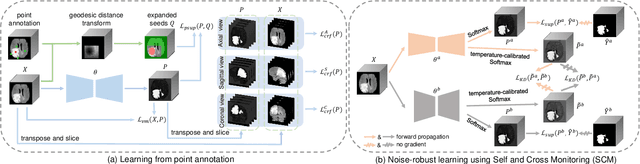
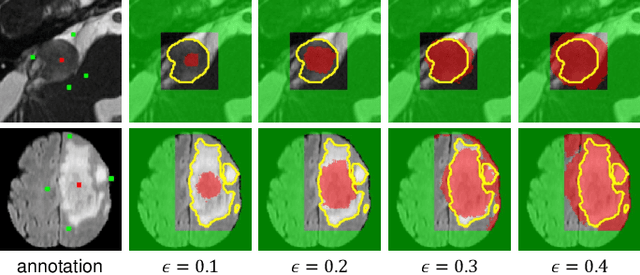
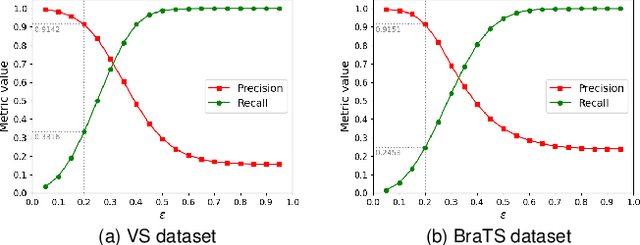
The success of Convolutional Neural Networks (CNNs) in 3D medical image segmentation relies on massive fully annotated 3D volumes for training that are time-consuming and labor-intensive to acquire. In this paper, we propose to annotate a segmentation target with only seven points in 3D medical images, and design a two-stage weakly supervised learning framework PA-Seg. In the first stage, we employ geodesic distance transform to expand the seed points to provide more supervision signal. To further deal with unannotated image regions during training, we propose two contextual regularization strategies, i.e., multi-view Conditional Random Field (mCRF) loss and Variance Minimization (VM) loss, where the first one encourages pixels with similar features to have consistent labels, and the second one minimizes the intensity variance for the segmented foreground and background, respectively. In the second stage, we use predictions obtained by the model pre-trained in the first stage as pseudo labels. To overcome noises in the pseudo labels, we introduce a Self and Cross Monitoring (SCM) strategy, which combines self-training with Cross Knowledge Distillation (CKD) between a primary model and an auxiliary model that learn from soft labels generated by each other. Experiments on public datasets for Vestibular Schwannoma (VS) segmentation and Brain Tumor Segmentation (BraTS) demonstrated that our model trained in the first stage outperforms existing state-of-the-art weakly supervised approaches by a large margin, and after using SCM for additional training, the model can achieve competitive performance compared with the fully supervised counterpart on the BraTS dataset.
HMRNet: High and Multi-Resolution Network with Bidirectional Feature Calibration for Brain Structure Segmentation in Radiotherapy
Jun 07, 2022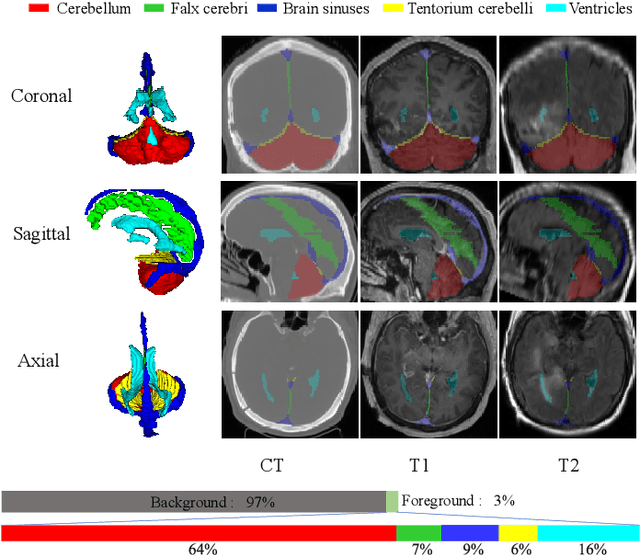
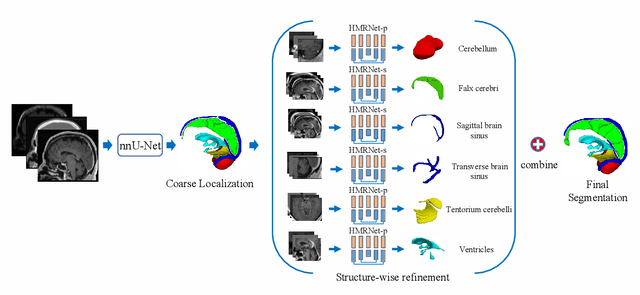

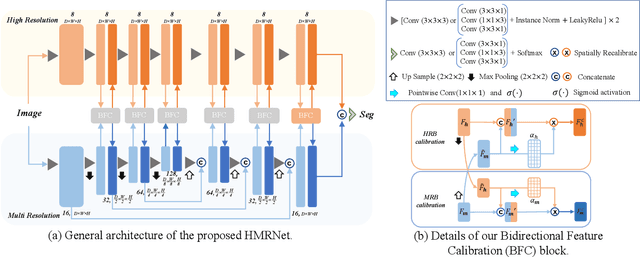
Accurate segmentation of Anatomical brain Barriers to Cancer spread (ABCs) plays an important role for automatic delineation of Clinical Target Volume (CTV) of brain tumors in radiotherapy. Despite that variants of U-Net are state-of-the-art segmentation models, they have limited performance when dealing with ABCs structures with various shapes and sizes, especially thin structures (e.g., the falx cerebri) that span only few slices. To deal with this problem, we propose a High and Multi-Resolution Network (HMRNet) that consists of a multi-scale feature learning branch and a high-resolution branch, which can maintain the high-resolution contextual information and extract more robust representations of anatomical structures with various scales. We further design a Bidirectional Feature Calibration (BFC) block to enable the two branches to generate spatial attention maps for mutual feature calibration. Considering the different sizes and positions of ABCs structures, our network was applied after a rough localization of each structure to obtain fine segmentation results. Experiments on the MICCAI 2020 ABCs challenge dataset showed that: 1) Our proposed two-stage segmentation strategy largely outperformed methods segmenting all the structures in just one stage; 2) The proposed HMRNet with two branches can maintain high-resolution representations and is effective to improve the performance on thin structures; 3) The proposed BFC block outperformed existing attention methods using monodirectional feature calibration. Our method won the second place of ABCs 2020 challenge and has a potential for more accurate and reasonable delineation of CTV of brain tumors.
Contrastive Domain Disentanglement for Generalizable Medical Image Segmentation
May 13, 2022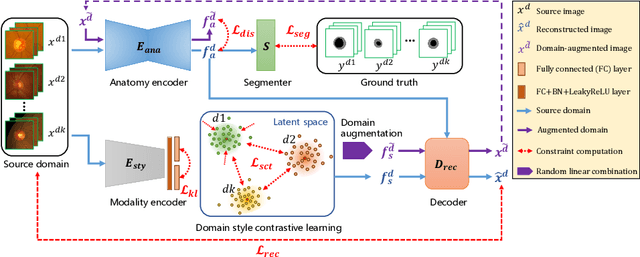
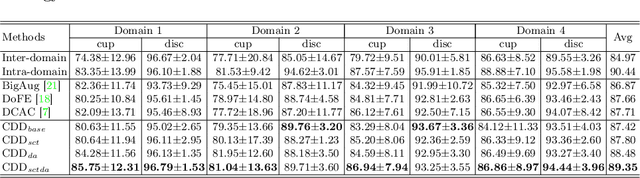
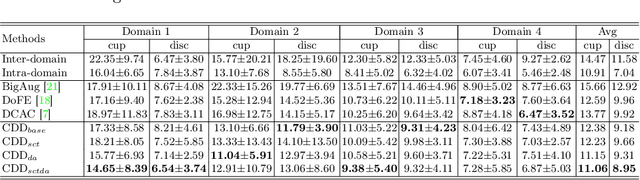
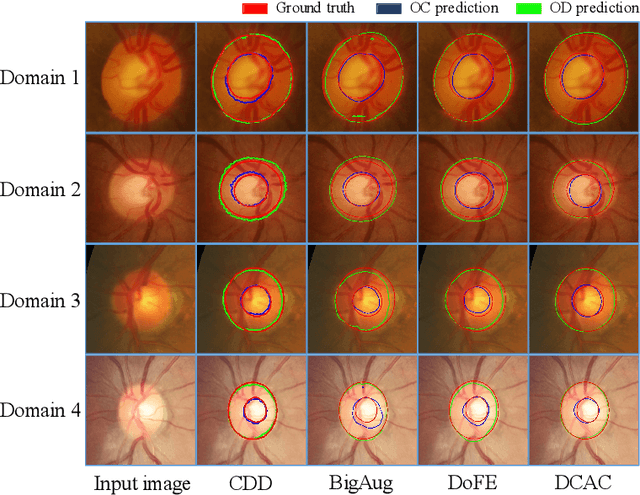
Efficiently utilizing discriminative features is crucial for convolutional neural networks to achieve remarkable performance in medical image segmentation and is also important for model generalization across multiple domains, where letting model recognize domain-specific and domain-invariant information among multi-site datasets is a reasonable strategy for domain generalization. Unfortunately, most of the recent disentangle networks are not directly adaptable to unseen-domain datasets because of the limitations of offered data distribution. To tackle this deficiency, we propose Contrastive Domain Disentangle (CDD) network for generalizable medical image segmentation. We first introduce a disentangle network to decompose medical images into an anatomical representation factor and a modality representation factor. Then, a style contrastive loss is proposed to encourage the modality representations from the same domain to distribute as close as possible while different domains are estranged from each other. Finally, we propose a domain augmentation strategy that can randomly generate new domains for model generalization training. Experimental results on multi-site fundus image datasets for optic cup and disc segmentation show that the CDD has good model generalization. Our proposed CDD outperforms several state-of-the-art methods in domain generalizable segmentation.
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022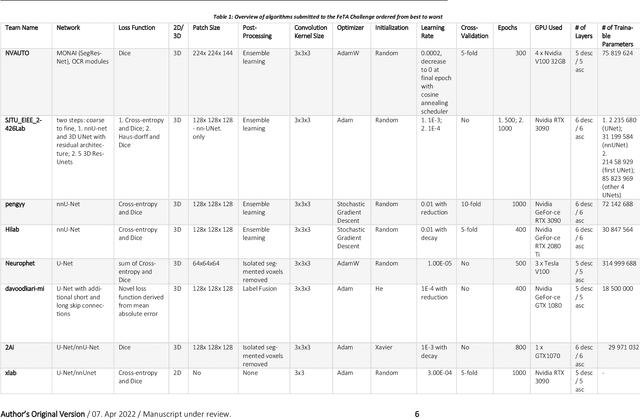
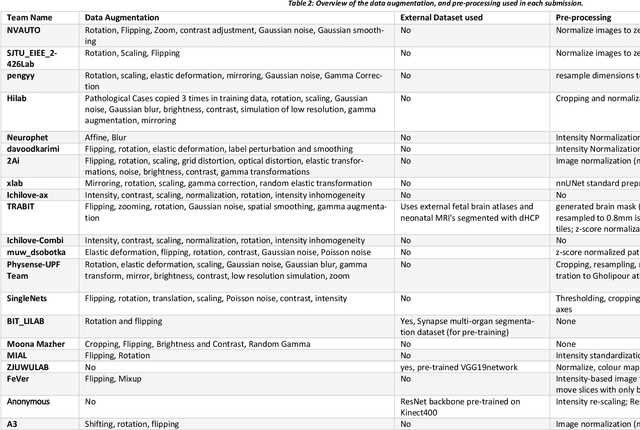
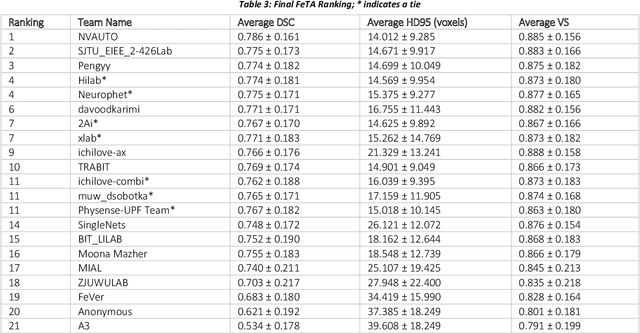
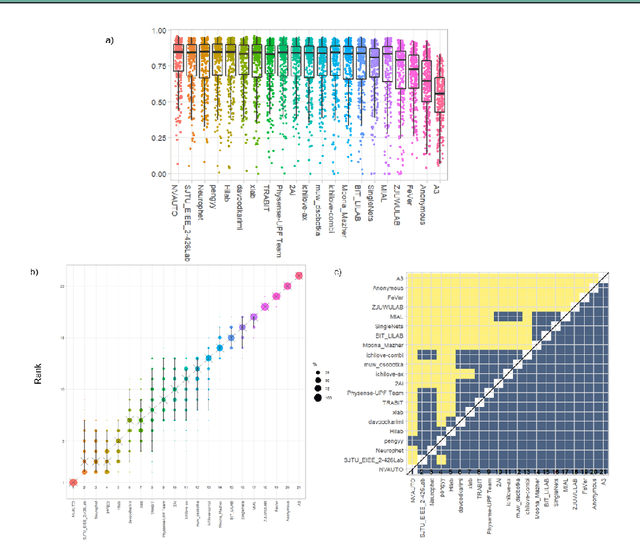
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
Scribble-Supervised Medical Image Segmentation via Dual-Branch Network and Dynamically Mixed Pseudo Labels Supervision
Mar 04, 2022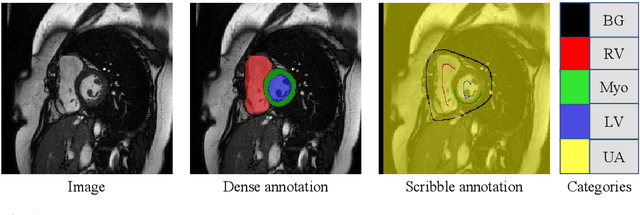
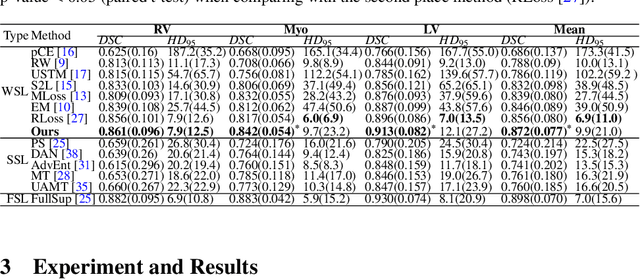
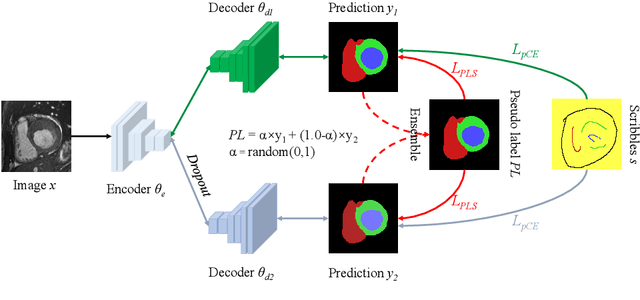

Medical image segmentation plays an irreplaceable role in computer-assisted diagnosis, treatment planning, and following-up. Collecting and annotating a large-scale dataset is crucial to training a powerful segmentation model, but producing high-quality segmentation masks is an expensive and time-consuming procedure. Recently, weakly-supervised learning that uses sparse annotations (points, scribbles, bounding boxes) for network training has achieved encouraging performance and shown the potential for annotation cost reduction. However, due to the limited supervision signal of sparse annotations, it is still challenging to employ them for networks training directly. In this work, we propose a simple yet efficient scribble-supervised image segmentation method and apply it to cardiac MRI segmentation. Specifically, we employ a dual-branch network with one encoder and two slightly different decoders for image segmentation and dynamically mix the two decoders' predictions to generate pseudo labels for auxiliary supervision. By combining the scribble supervision and auxiliary pseudo labels supervision, the dual-branch network can efficiently learn from scribble annotations end-to-end. Experiments on the public ACDC dataset show that our method performs better than current scribble-supervised segmentation methods and also outperforms several semi-supervised segmentation methods.
MyoPS: A Benchmark of Myocardial Pathology Segmentation Combining Three-Sequence Cardiac Magnetic Resonance Images
Jan 10, 2022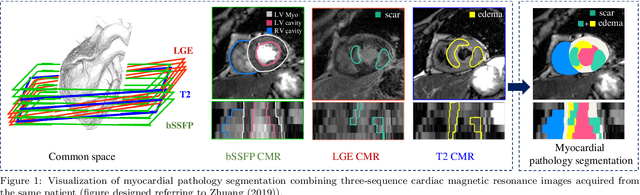
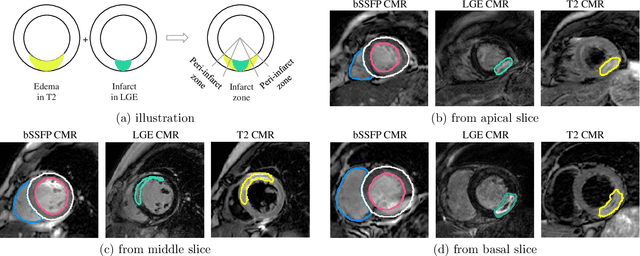
Assessment of myocardial viability is essential in diagnosis and treatment management of patients suffering from myocardial infarction, and classification of pathology on myocardium is the key to this assessment. This work defines a new task of medical image analysis, i.e., to perform myocardial pathology segmentation (MyoPS) combining three-sequence cardiac magnetic resonance (CMR) images, which was first proposed in the MyoPS challenge, in conjunction with MICCAI 2020. The challenge provided 45 paired and pre-aligned CMR images, allowing algorithms to combine the complementary information from the three CMR sequences for pathology segmentation. In this article, we provide details of the challenge, survey the works from fifteen participants and interpret their methods according to five aspects, i.e., preprocessing, data augmentation, learning strategy, model architecture and post-processing. In addition, we analyze the results with respect to different factors, in order to examine the key obstacles and explore potential of solutions, as well as to provide a benchmark for future research. We conclude that while promising results have been reported, the research is still in the early stage, and more in-depth exploration is needed before a successful application to the clinics. Note that MyoPS data and evaluation tool continue to be publicly available upon registration via its homepage (www.sdspeople.fudan.edu.cn/zhuangxiahai/0/myops20/).
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022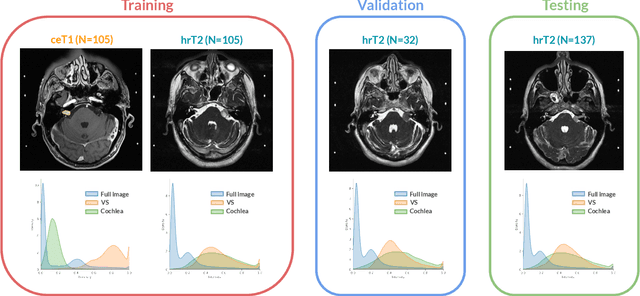
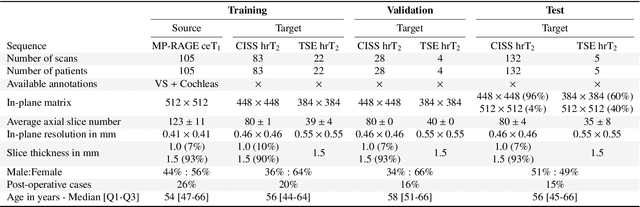
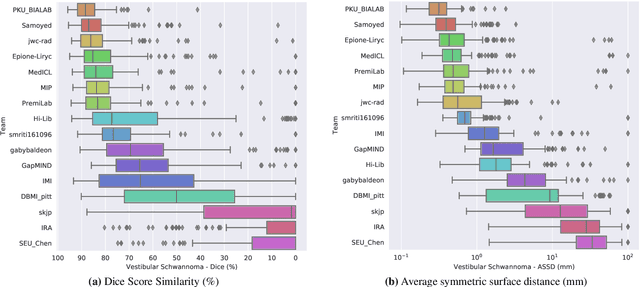
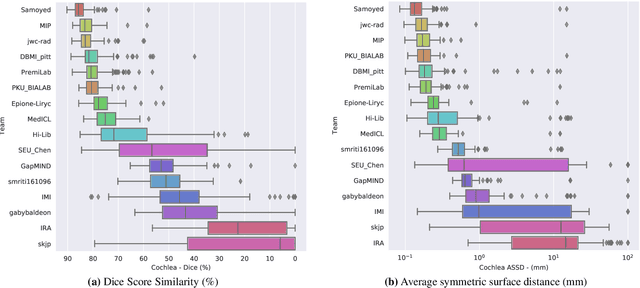
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.