 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogradient Descent for Bilinear Optimization
Jun 16, 2020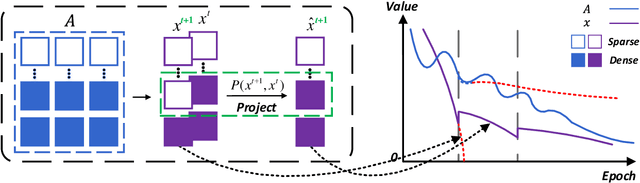
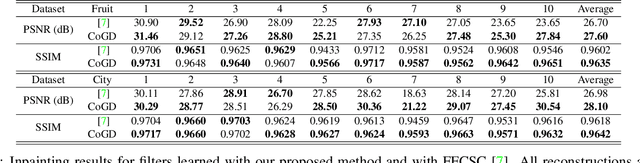
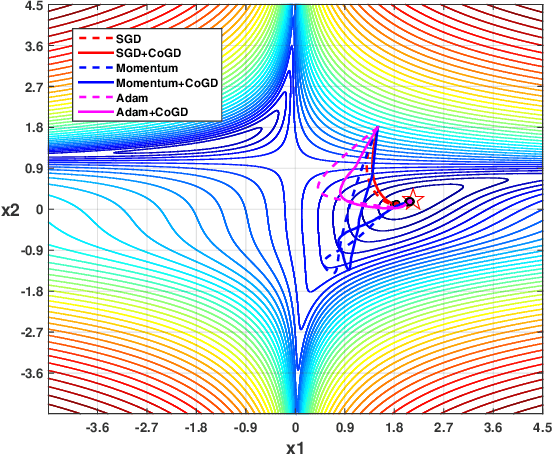
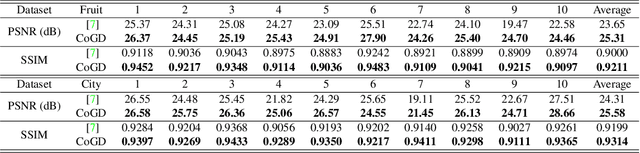
Conventional learning methods simplify the bilinear model by regarding two intrinsically coupled factors independently, which degrades the optimization procedure. One reason lies in the insufficient training due to the asynchronous gradient descent, which results in vanishing gradients for the coupled variables. In this paper, we introduce a Cogradient Descent algorithm (CoGD) to address the bilinear problem, based on a theoretical framework to coordinate the gradient of hidden variables via a projection function. We solve one variable by considering its coupling relationship with the other, leading to a synchronous gradient descent to facilitate the optimization procedure. Our algorithm is applied to solve problems with one variable under the sparsity constraint, which is widely used in the learning paradigm. We validate our CoGD considering an extensive set of applications including image reconstruction, inpainting, and network pruning. Experiments show that it improves the state-of-the-art by a significant margin.
3D Face Anti-spoofing with Factorized Bilinear Coding
May 12, 2020



We have witnessed rapid advances in both face presentation attack models and presentation attack detection (PAD) in recent years. When compared with widely studied 2D face presentation attacks, 3D face spoofing attacks are more challenging because face recognition systems (FRS) are more easily confused by the 3D characteristics of materials similar to real faces. In this work, we tackle the problem of detecting these realistic 3D face presentation attacks, and propose a novel anti-spoofing method from the perspective of fine-grained classification. Our method, based on factorized bilinear coding of multiple color channels (namely MC_FBC), targets at learning subtle visual differences between real and fake images. By extracting discriminative and fusing complementary information from RGB and YCbCr spaces, we have developed a principled solution to 3D face spoofing detection. A large-scale wax figure face database (WFFD) with both still and moving wax faces has also been collected as super-realistic attacks to facilitate the study of 3D face PAD. Extensive experimental results show that our proposed method achieves the state-of-the-art performance on both our own WFFD and other face spoofing databases under various intra-database and inter-database testing scenarios.
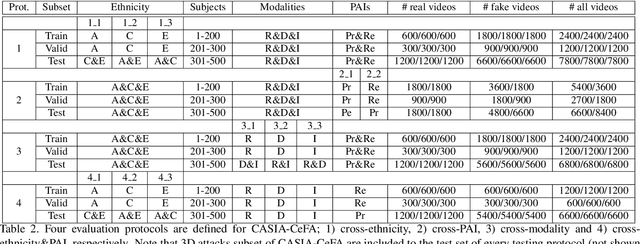
Cross-ethnicity Face Anti-spoofing Recognition Challenge: A Review
Apr 23, 2020
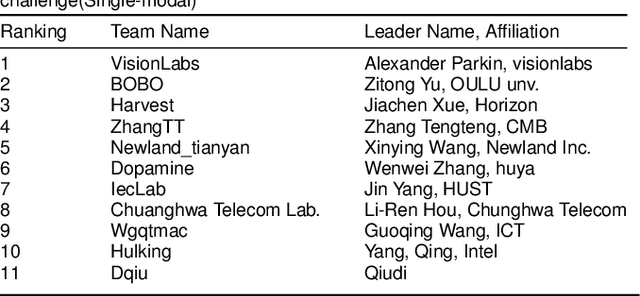
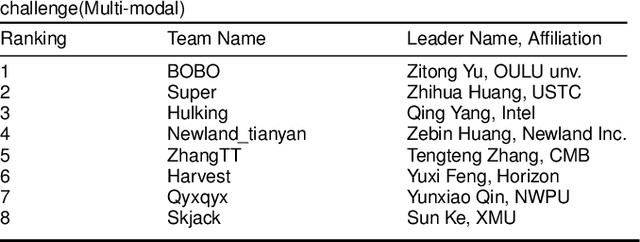
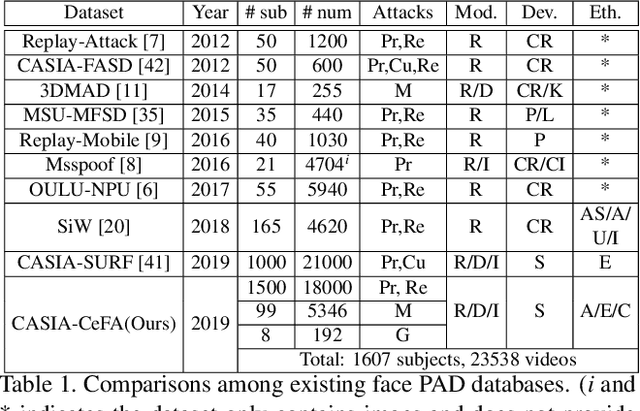
Face anti-spoofing is critical to prevent face recognition systems from a security breach. The biometrics community has %possessed achieved impressive progress recently due the excellent performance of deep neural networks and the availability of large datasets. Although ethnic bias has been verified to severely affect the performance of face recognition systems, it still remains an open research problem in face anti-spoofing. Recently, a multi-ethnic face anti-spoofing dataset, CASIA-SURF CeFA, has been released with the goal of measuring the ethnic bias. It is the largest up to date cross-ethnicity face anti-spoofing dataset covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, 2D plus 3D attack types, and the first dataset including explicit ethnic labels among the recently released datasets for face anti-spoofing. We organized the Chalearn Face Anti-spoofing Attack Detection Challenge which consists of single-modal (e.g., RGB) and multi-modal (e.g., RGB, Depth, Infrared (IR)) tracks around this novel resource to boost research aiming to alleviate the ethnic bias. Both tracks have attracted $340$ teams in the development stage, and finally 11 and 8 teams have submitted their codes in the single-modal and multi-modal face anti-spoofing recognition challenges, respectively. All the results were verified and re-ran by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including its design, evaluation protocol and a summary of results. We analyze the top ranked solutions and draw conclusions derived from the competition. In addition we outline future work directions.
CASIA-SURF CeFA: A Benchmark for Multi-modal Cross-ethnicity Face Anti-spoofing
Mar 11, 2020
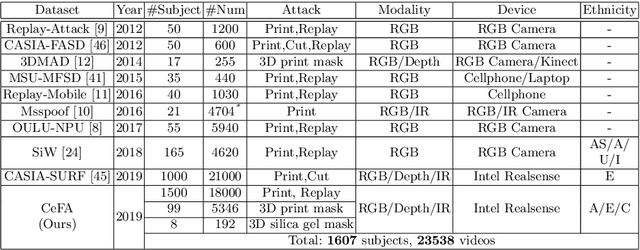
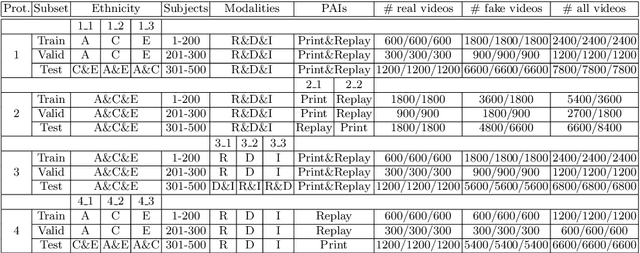
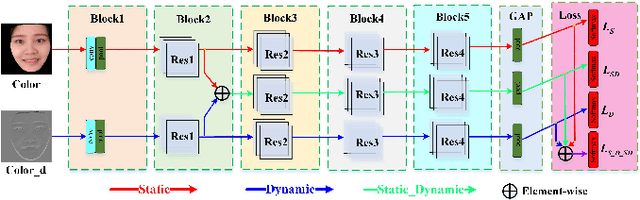
Ethnic bias has proven to negatively affect the performance of face recognition systems, and it remains an open research problem in face anti-spoofing. In order to study the ethnic bias for face anti-spoofing, we introduce the largest up to date CASIA-SURF Cross-ethnicity Face Anti-spoofing (CeFA) dataset (briefly named CeFA), covering $3$ ethnicities, $3$ modalities, $1,607$ subjects, and 2D plus 3D attack types. Four protocols are introduced to measure the affect under varied evaluation conditions, such as cross-ethnicity, unknown spoofs or both of them. To the best of our knowledge, CeFA is the first dataset including explicit ethnic labels in current published/released datasets for face anti-spoofing. Then, we propose a novel multi-modal fusion method as a strong baseline to alleviate these bias, namely, the static-dynamic fusion mechanism applied in each modality (i.e., RGB, Depth and infrared image). Later, a partially shared fusion strategy is proposed to learn complementary information from multiple modalities. Extensive experiments demonstrate that the proposed method achieves state-of-the-art results on the CASIA-SURF, OULU-NPU, SiW and the CeFA dataset.
Static and Dynamic Fusion for Multi-modal Cross-ethnicity Face Anti-spoofing
Dec 16, 2019
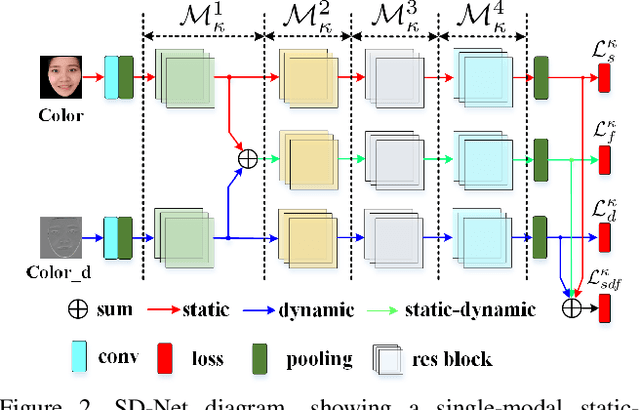
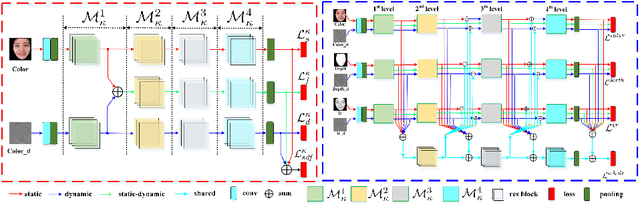
Regardless of the usage of deep learning and handcrafted methods, the dynamic information from videos and the effect of cross-ethnicity are rarely considered in face anti-spoofing. In this work, we propose a static-dynamic fusion mechanism for multi-modal face anti-spoofing. Inspired by motion divergences between real and fake faces, we incorporate the dynamic image calculated by rank pooling with static information into a conventional neural network (CNN) for each modality (i.e., RGB, Depth and infrared (IR)). Then, we develop a partially shared fusion method to learn complementary information from multiple modalities. Furthermore, in order to study the generalization capability of the proposal in terms of cross-ethnicity attacks and unknown spoofs, we introduce the largest public cross-ethnicity Face Anti-spoofing (CASIA-CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types. Experiments demonstrate that the proposed method achieves state-of-the-art results on CASIA-CeFA, CASIA-SURF, OULU-NPU and SiW.
Robust Invisible Hyperlinks in Physical Photographs Based on 3D Rendering Attacks
Dec 03, 2019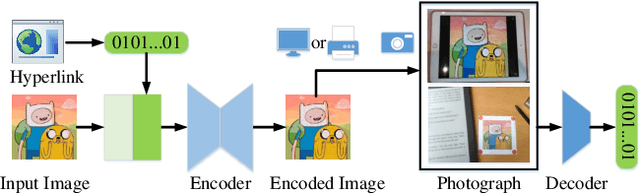
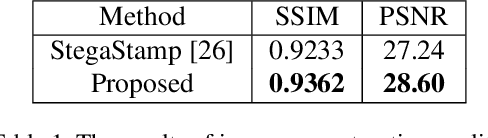
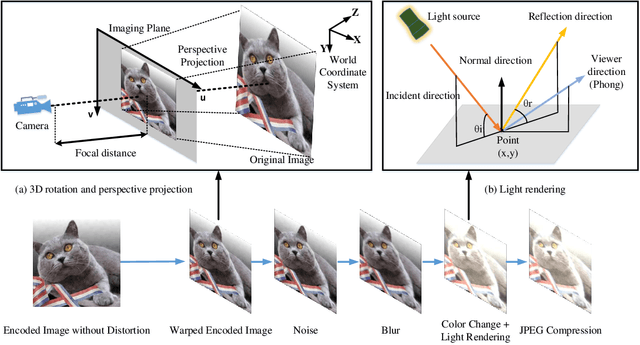
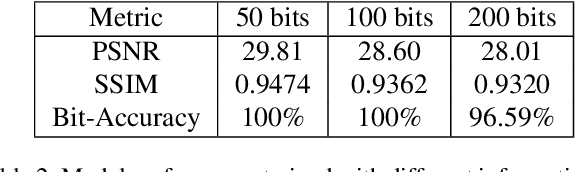
In the era of multimedia and Internet, people are eager to obtain information from offline to online. Quick Response (QR) codes and digital watermarks help us access information quickly. However, QR codes look ugly and invisible watermarks can be easily broken in physical photographs. Therefore, this paper proposes a novel method to embed hyperlinks into natural images, making the hyperlinks invisible for human eyes but detectable for mobile devices. Our method is an end-to-end neural network with an encoder to hide information and a decoder to recover information. From original images to physical photographs, camera imaging process will introduce a series of distortion such as noise, blur, and light. To train a robust decoder against the physical distortion from the real world, a distortion network based on 3D rendering is inserted between the encoder and the decoder to simulate the camera imaging process. Besides, in order to maintain the visual attraction of the image with hyperlinks, we propose a loss function based on just noticeable difference (JND) to supervise the training of encoder. Experimental results show that our approach outperforms the previous method in both simulated and real situations.
GBCNs: Genetic Binary Convolutional Networks for Enhancing the Performance of 1-bit DCNNs
Nov 25, 2019

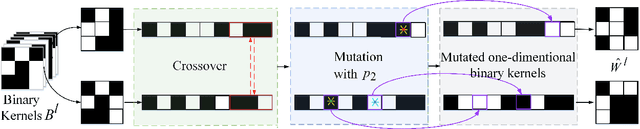
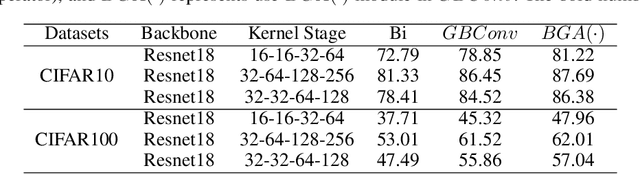
Training 1-bit deep convolutional neural networks (DCNNs) is one of the most challenging problems in computer vision, because it is much easier to get trapped into local minima than conventional DCNNs. The reason lies in that the binarized kernels and activations of 1-bit DCNNs cause a significant accuracy loss and training inefficiency. To address this problem, we propose Genetic Binary Convolutional Networks (GBCNs) to optimize 1-bit DCNNs, by introducing a new balanced Genetic Algorithm (BGA) to improve the representational ability in an end-to-end framework. The BGA method is proposed to modify the binary process of GBCNs to alleviate the local minima problem, which can significantly improve the performance of 1-bit DCNNs. We develop a new BGA module that is generic and flexible, and can be easily incorporated into existing DCNNs, such asWideResNets and ResNets. Extensive experiments on the object classification tasks (CIFAR, ImageNet) validate the effectiveness of the proposed method. To highlight, our method shows strong generalization on the object recognition task, i.e., face recognition, facial and person re-identification.
Aggregation Signature for Small Object Tracking
Oct 24, 2019
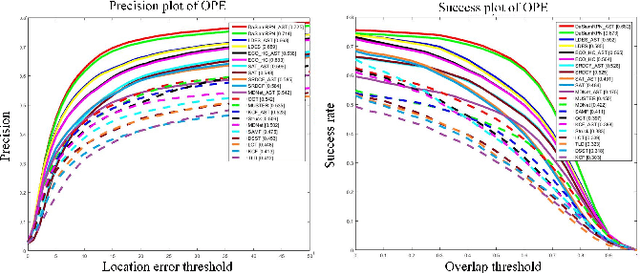
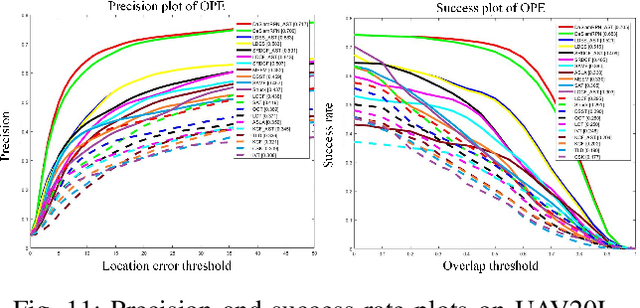
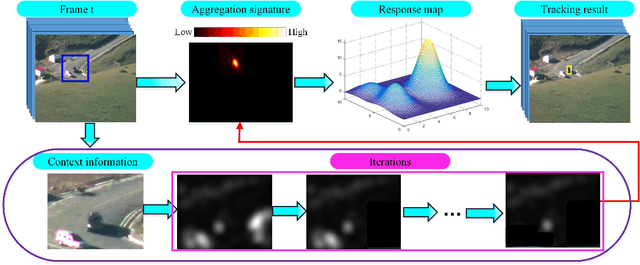
Small object tracking becomes an increasingly important task, which however has been largely unexplored in computer vision. The great challenges stem from the facts that: 1) small objects show extreme vague and variable appearances, and 2) they tend to be lost easier as compared to normal-sized ones due to the shaking of lens. In this paper, we propose a novel aggregation signature suitable for small object tracking, especially aiming for the challenge of sudden and large drift. We make three-fold contributions in this work. First, technically, we propose a new descriptor, named aggregation signature, based on saliency, able to represent highly distinctive features for small objects. Second, theoretically, we prove that the proposed signature matches the foreground object more accurately with a high probability. Third, experimentally, the aggregation signature achieves a high performance on multiple datasets, outperforming the state-of-the-art methods by large margins. Moreover, we contribute with two newly collected benchmark datasets, i.e., small90 and small112, for visually small object tracking. The datasets will be available in https://github.com/bczhangbczhang/.
Face Detection on Surveillance Images
Oct 22, 2019
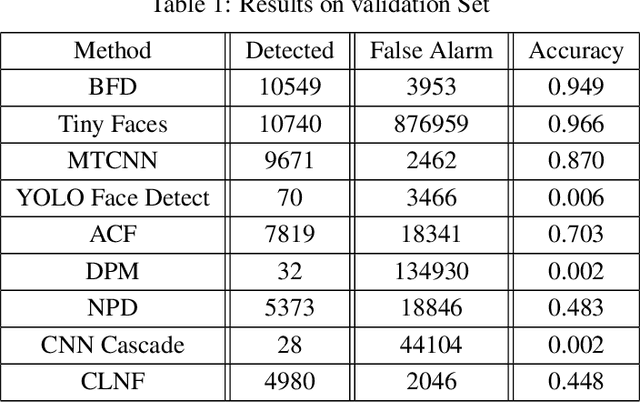

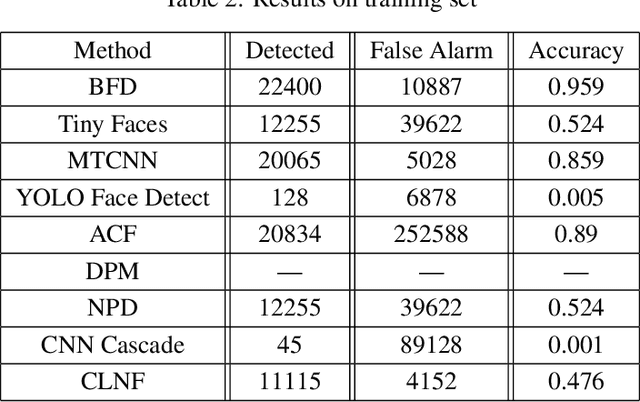
In last few decades, a lot of progress has been made in the field of face detection. Various face detection methods have been proposed by numerous researchers working in this area. The two well-known benchmarking platform: the FDDB and WIDER face detection provide quite challenging scenarios to assess the efficacy of the detection methods. These benchmarking data sets are mostly created using images from the public network ie. the Internet. A recent, face detection and open-set recognition challenge has shown that those same face detection algorithms produce high false alarms for images taken in surveillance scenario. This shows the difficult nature of the surveillance environment. Our proposed body pose based face detection method was one of the top performers in this competition. In this paper, we perform a comparative performance analysis of some of the well known face detection methods including the few used in that competition, and, compare them to our proposed body pose based face detection method. Experiment results show that, our proposed method that leverages body information to detect faces, is the most realistic approach in terms of accuracy, false alarms and average detection time, when surveillance scenario is in consideration.
WiderPerson: A Diverse Dataset for Dense Pedestrian Detection in the Wild
Sep 25, 2019
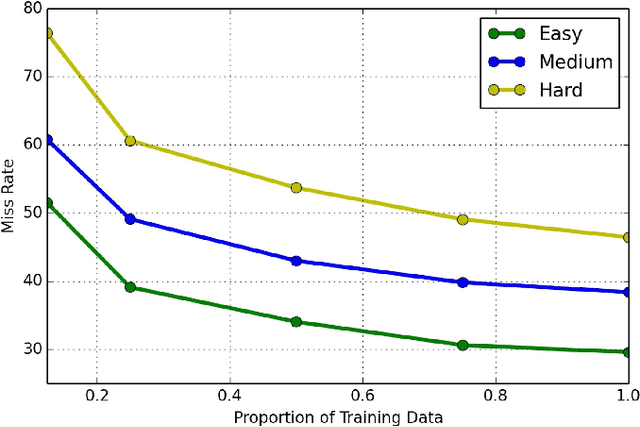
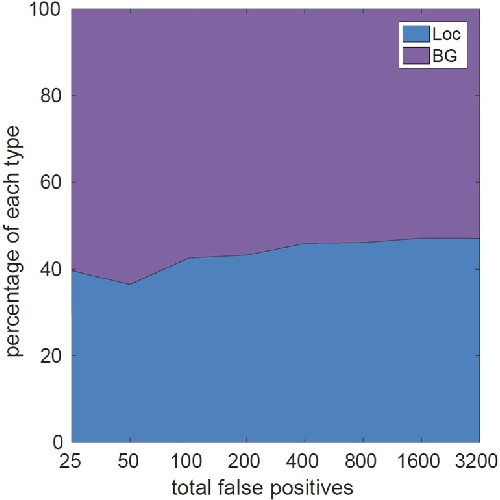

Pedestrian detection has achieved significant progress with the availability of existing benchmark datasets. However, there is a gap in the diversity and density between real world requirements and current pedestrian detection benchmarks: 1) most of existing datasets are taken from a vehicle driving through the regular traffic scenario, usually leading to insufficient diversity; 2) crowd scenarios with highly occluded pedestrians are still under represented, resulting in low density. To narrow this gap and facilitate future pedestrian detection research, we introduce a large and diverse dataset named WiderPerson for dense pedestrian detection in the wild. This dataset involves five types of annotations in a wide range of scenarios, no longer limited to the traffic scenario. There are a total of $13,382$ images with $399,786$ annotations, i.e., $29.87$ annotations per image, which means this dataset contains dense pedestrians with various kinds of occlusions. Hence, pedestrians in the proposed dataset are extremely challenging due to large variations in the scenario and occlusion, which is suitable to evaluate pedestrian detectors in the wild. We introduce an improved Faster R-CNN and the vanilla RetinaNet to serve as baselines for the new pedestrian detection benchmark. Several experiments are conducted on previous datasets including Caltech-USA and CityPersons to analyze the generalization capabilities of the proposed dataset and we achieve state-of-the-art performances on these previous datasets without bells and whistles. Finally, we analyze common failure cases and find the classification ability of pedestrian detector needs to be improved to reduce false alarm and miss detection rates. The proposed dataset is available at http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson