 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See Through with Events
Dec 05, 2022



Although synthetic aperture imaging (SAI) can achieve the seeing-through effect by blurring out off-focus foreground occlusions while recovering in-focus occluded scenes from multi-view images, its performance is often deteriorated by dense occlusions and extreme lighting conditions. To address the problem, this paper presents an Event-based SAI (E-SAI) method by relying on the asynchronous events with extremely low latency and high dynamic range acquired by an event camera. Specifically, the collected events are first refocused by a Refocus-Net module to align in-focus events while scattering out off-focus ones. Following that, a hybrid network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs) is proposed to encode the spatio-temporal information from the refocused events and reconstruct a visual image of the occluded targets. Extensive experiments demonstrate that our proposed E-SAI method can achieve remarkable performance in dealing with very dense occlusions and extreme lighting conditions and produce high-quality images from pure events. Codes and datasets are available at https://dvs-whu.cn/projects/esai/.
NOPE-SAC: Neural One-Plane RANSAC for Sparse-View Planar 3D Reconstruction
Nov 30, 2022This paper studies the challenging two-view 3D reconstruction in a rigorous sparse-view configuration, which is suffering from insufficient correspondences in the input image pairs for camera pose estimation. We present a novel Neural One-PlanE RANSAC framework (termed NOPE-SAC in short) that exerts excellent capability to learn one-plane pose hypotheses from 3D plane correspondences. Building on the top of a siamese plane detection network, our NOPE-SAC first generates putative plane correspondences with a coarse initial pose. It then feeds the learned 3D plane parameters of correspondences into shared MLPs to estimate the one-plane camera pose hypotheses, which are subsequently reweighed in a RANSAC manner to obtain the final camera pose. Because the neural one-plane pose minimizes the number of plane correspondences for adaptive pose hypotheses generation, it enables stable pose voting and reliable pose refinement in a few plane correspondences for the sparse-view inputs. In the experiments, we demonstrate that our NOPE-SAC significantly improves the camera pose estimation for the two-view inputs with severe viewpoint changes, setting several new state-of-the-art performances on two challenging benchmarks, i.e., MatterPort3D and ScanNet, for sparse-view 3D reconstruction. The source code is released at https://github.com/IceTTTb/NopeSAC for reproducible research.
Level-S$^2$fM: Structure from Motion on Neural Level Set of Implicit Surfaces
Nov 22, 2022



This paper presents a neural incremental Structure-from-Motion (SfM) approach, Level-S$^2$fM. In our formulation, we aim at simultaneously learning coordinate MLPs for the implicit surfaces and the radiance fields, and estimating the camera poses and scene geometry, which is mainly sourced from the established keypoint correspondences by SIFT. Our formulation would face some new challenges due to inevitable two-view and few-view configurations at the beginning of incremental SfM pipeline for the optimization of coordinate MLPs, but we found that the strong inductive biases conveying in the 2D correspondences are feasible and promising to avoid those challenges by exploiting the relationship between the ray sampling schemes used in volumetric rendering and the sphere tracing of finding the zero-level set of implicit surfaces. Based on this, we revisit the pipeline of incremental SfM and renew the key components of two-view geometry initialization, the camera pose registration, and the 3D points triangulation, as well as the Bundle Adjustment in a novel perspective of neural implicit surfaces. Because the coordinate MLPs unified the scene geometry in small MLP networks, our Level-S$^2$fM treats the zero-level set of the implicit surface as an informative top-down regularization to manage the reconstructed 3D points, reject the outlier of correspondences by querying SDF, adjust the estimated geometries by NBA (Neural BA), finally yielding promising results of 3D reconstruction. Furthermore, our Level-S$^2$fM alleviated the requirement of camera poses for neural 3D reconstruction.
Detecting Line Segments in Motion-blurred Images with Events
Nov 20, 2022



Making line segment detectors more reliable under motion blurs is one of the most important challenges for practical applications, such as visual SLAM and 3D reconstruction. Existing line segment detection methods face severe performance degradation for accurately detecting and locating line segments when motion blur occurs. While event data shows strong complementary characteristics to images for minimal blur and edge awareness at high-temporal resolution, potentially beneficial for reliable line segment recognition. To robustly detect line segments over motion blurs, we propose to leverage the complementary information of images and events. To achieve this, we first design a general frame-event feature fusion network to extract and fuse the detailed image textures and low-latency event edges, which consists of a channel-attention-based shallow fusion module and a self-attention-based dual hourglass module. We then utilize two state-of-the-art wireframe parsing networks to detect line segments on the fused feature map. Besides, we contribute a synthetic and a realistic dataset for line segment detection, i.e., FE-Wireframe and FE-Blurframe, with pairwise motion-blurred images and events. Extensive experiments on both datasets demonstrate the effectiveness of the proposed method. When tested on the real dataset, our method achieves 63.3% mean structural average precision (msAP) with the model pre-trained on the FE-Wireframe and fine-tuned on the FE-Blurframe, improved by 32.6 and 11.3 points compared with models trained on synthetic only and real only, respectively. The codes, datasets, and trained models are released at: https://levenberg.github.io/FE-LSD
Holistically-Attracted Wireframe Parsing: From Supervised to Self-Supervised Learning
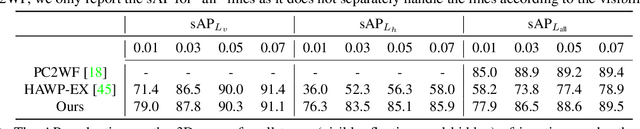
Oct 24, 2022This paper presents Holistically-Attracted Wireframe Parsing (HAWP) for 2D images using both fully supervised and self-supervised learning paradigms. At the core is a parsimonious representation that encodes a line segment using a closed-form 4D geometric vector, which enables lifting line segments in wireframe to an end-to-end trainable holistic attraction field that has built-in geometry-awareness, context-awareness and robustness. The proposed HAWP consists of three components: generating line segment and end-point proposal, binding line segment and end-point, and end-point-decoupled lines-of-interest verification. For self-supervised learning, a simulation-to-reality pipeline is exploited in which a HAWP is first trained using synthetic data and then used to ``annotate" wireframes in real images with Homographic Adaptation. With the self-supervised annotations, a HAWP model for real images is trained from scratch. In experiments, the proposed HAWP achieves state-of-the-art performance in both the Wireframe dataset and the YorkUrban dataset in fully-supervised learning. It also demonstrates a significantly better repeatability score than prior arts with much more efficient training in self-supervised learning. Furthermore, the self-supervised HAWP shows great potential for general wireframe parsing without onerous wireframe labels.
Anomaly Detection in Aerial Videos with Transformers
Sep 25, 2022

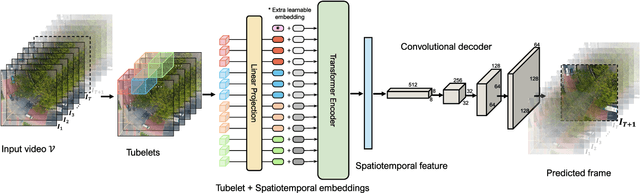
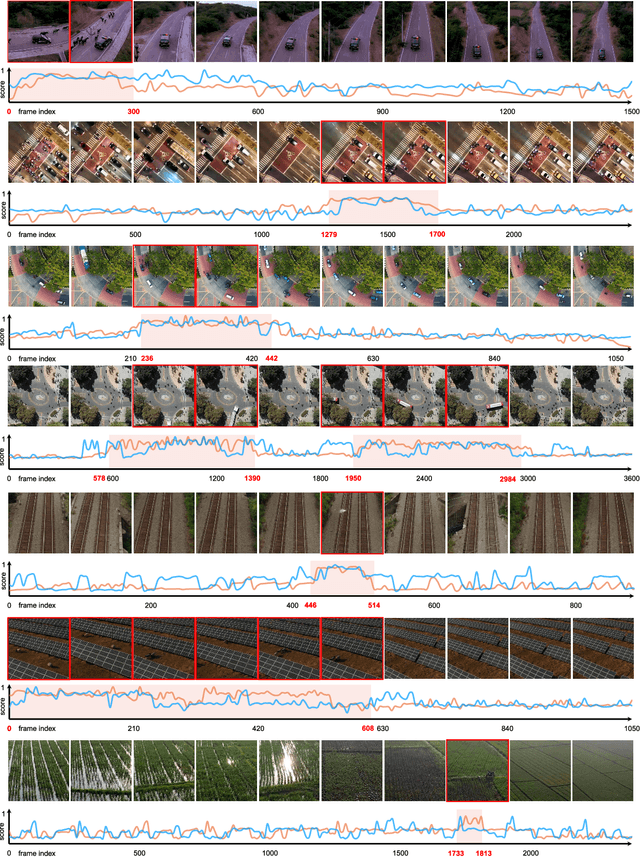
Unmanned aerial vehicles (UAVs) are widely applied for purposes of inspection, search, and rescue operations by the virtue of low-cost, large-coverage, real-time, and high-resolution data acquisition capacities. Massive volumes of aerial videos are produced in these processes, in which normal events often account for an overwhelming proportion. It is extremely difficult to localize and extract abnormal events containing potentially valuable information from long video streams manually. Therefore, we are dedicated to developing anomaly detection methods to solve this issue. In this paper, we create a new dataset, named DroneAnomaly, for anomaly detection in aerial videos. This dataset provides 37 training video sequences and 22 testing video sequences from 7 different realistic scenes with various anomalous events. There are 87,488 color video frames (51,635 for training and 35,853 for testing) with the size of $640 \times 640$ at 30 frames per second. Based on this dataset, we evaluate existing methods and offer a benchmark for this task. Furthermore, we present a new baseline model, ANomaly Detection with Transformers (ANDT), which treats consecutive video frames as a sequence of tubelets, utilizes a Transformer encoder to learn feature representations from the sequence, and leverages a decoder to predict the next frame. Our network models normality in the training phase and identifies an event with unpredictable temporal dynamics as an anomaly in the test phase. Moreover, To comprehensively evaluate the performance of our proposed method, we use not only our Drone-Anomaly dataset but also another dataset. We will make our dataset and code publicly available. A demo video is available at https://youtu.be/ancczYryOBY. We make our dataset and code publicly available .
FuTH-Net: Fusing Temporal Relations and Holistic Features for Aerial Video Classification
Sep 22, 2022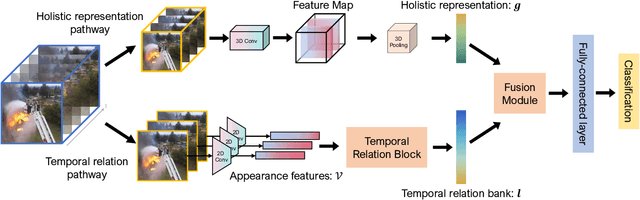

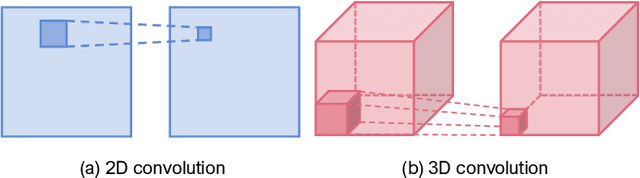
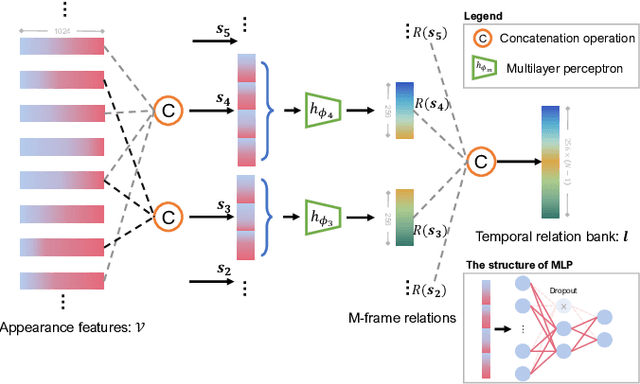
Unmanned aerial vehicles (UAVs) are now widely applied to data acquisition due to its low cost and fast mobility. With the increasing volume of aerial videos, the demand for automatically parsing these videos is surging. To achieve this, current researches mainly focus on extracting a holistic feature with convolutions along both spatial and temporal dimensions. However, these methods are limited by small temporal receptive fields and cannot adequately capture long-term temporal dependencies which are important for describing complicated dynamics. In this paper, we propose a novel deep neural network, termed FuTH-Net, to model not only holistic features, but also temporal relations for aerial video classification. Furthermore, the holistic features are refined by the multi-scale temporal relations in a novel fusion module for yielding more discriminative video representations. More specially, FuTH-Net employs a two-pathway architecture: (1) a holistic representation pathway to learn a general feature of both frame appearances and shortterm temporal variations and (2) a temporal relation pathway to capture multi-scale temporal relations across arbitrary frames, providing long-term temporal dependencies. Afterwards, a novel fusion module is proposed to spatiotemporal integrate the two features learned from the two pathways. Our model is evaluated on two aerial video classification datasets, ERA and Drone-Action, and achieves the state-of-the-art results. This demonstrates its effectiveness and good generalization capacity across different recognition tasks (event classification and human action recognition). To facilitate further research, we release the code at https://gitlab.lrz.de/ai4eo/reasoning/futh-net.
Transformers in Remote Sensing: A Survey
Sep 02, 2022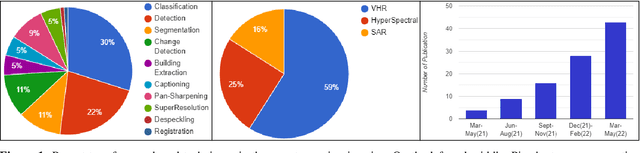
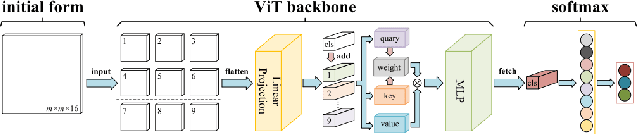
Deep learning-based algorithms have seen a massive popularity in different areas of remote sensing image analysis over the past decade. Recently, transformers-based architectures, originally introduced in natural language processing, have pervaded computer vision field where the self-attention mechanism has been utilized as a replacement to the popular convolution operator for capturing long-range dependencies. Inspired by recent advances in computer vision, remote sensing community has also witnessed an increased exploration of vision transformers for a diverse set of tasks. Although a number of surveys have focused on transformers in computer vision in general, to the best of our knowledge we are the first to present a systematic review of recent advances based on transformers in remote sensing. Our survey covers more than 60 recent transformers-based methods for different remote sensing problems in sub-areas of remote sensing: very high-resolution (VHR), hyperspectral (HSI) and synthetic aperture radar (SAR) imagery. We conclude the survey by discussing different challenges and open issues of transformers in remote sensing. Additionally, we intend to frequently update and maintain the latest transformers in remote sensing papers with their respective code at: https://github.com/VIROBO-15/Transformer-in-Remote-Sensing
Enabling Country-Scale Land Cover Mapping with Meter-Resolution Satellite Imagery
Sep 01, 2022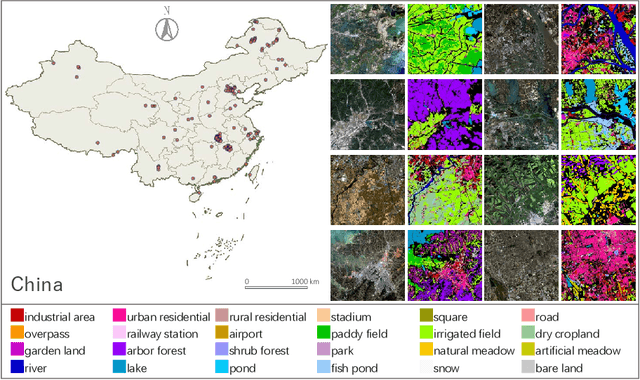



High-resolution satellite images can provide abundant, detailed spatial information for land cover classification, which is particularly important for studying the complicated built environment. However, due to the complex land cover patterns, the costly training sample collections, and the severe distribution shifts of satellite imageries, few studies have applied high-resolution images to land cover mapping in detailed categories at large scale. To fill this gap, we present a large-scale land cover dataset, Five-Billion-Pixels. It contains more than 5 billion labeled pixels of 150 high-resolution Gaofen-2 (4 m) satellite images, annotated in a 24-category system covering artificial-constructed, agricultural, and natural classes. In addition, we propose a deep-learning-based unsupervised domain adaptation approach that can transfer classification models trained on labeled dataset (referred to as the source domain) to unlabeled data (referred to as the target domain) for large-scale land cover mapping. Specifically, we introduce an end-to-end Siamese network employing dynamic pseudo-label assignment and class balancing strategy to perform adaptive domain joint learning. To validate the generalizability of our dataset and the proposed approach across different sensors and different geographical regions, we carry out land cover mapping on five megacities in China and six cities in other five Asian countries severally using: PlanetScope (3 m), Gaofen-1 (8 m), and Sentinel-2 (10 m) satellite images. Over a total study area of 60,000 square kilometers, the experiments show promising results even though the input images are entirely unlabeled. The proposed approach, trained with the Five-Billion-Pixels dataset, enables high-quality and detailed land cover mapping across the whole country of China and some other Asian countries at meter-resolution.
HoW-3D: Holistic 3D Wireframe Perception from a Single Image
Aug 19, 2022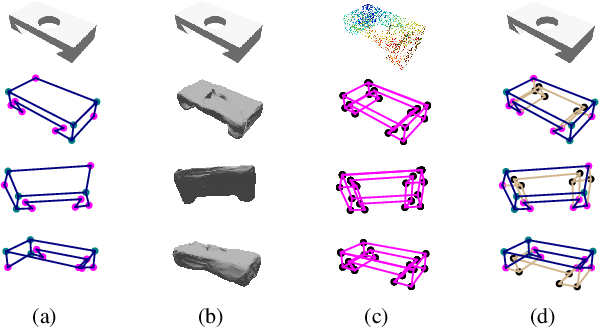

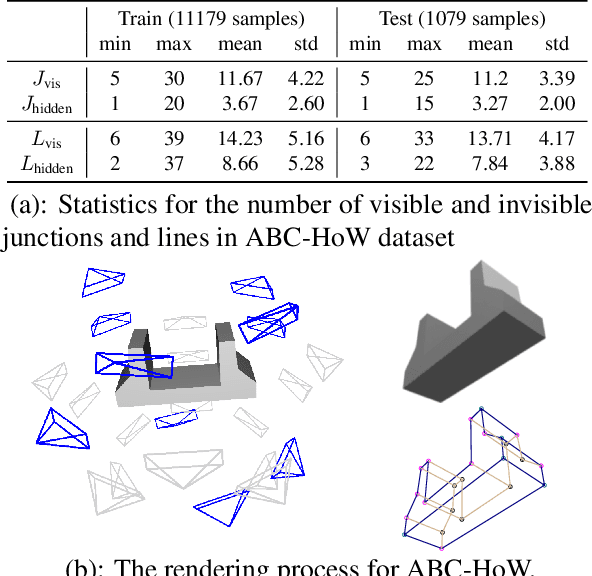
This paper studies the problem of holistic 3D wireframe perception (HoW-3D), a new task of perceiving both the visible 3D wireframes and the invisible ones from single-view 2D images. As the non-front surfaces of an object cannot be directly observed in a single view, estimating the non-line-of-sight (NLOS) geometries in HoW-3D is a fundamentally challenging problem and remains open in computer vision. We study the problem of HoW-3D by proposing an ABC-HoW benchmark, which is created on top of CAD models sourced from the ABC-dataset with 12k single-view images and the corresponding holistic 3D wireframe models. With our large-scale ABC-HoW benchmark available, we present a novel Deep Spatial Gestalt (DSG) model to learn the visible junctions and line segments as the basis and then infer the NLOS 3D structures from the visible cues by following the Gestalt principles of human vision systems. In our experiments, we demonstrate that our DSG model performs very well in inferring the holistic 3D wireframes from single-view images. Compared with the strong baseline methods, our DSG model outperforms the previous wireframe detectors in detecting the invisible line geometry in single-view images and is even very competitive with prior arts that take high-fidelity PointCloud as inputs on reconstructing 3D wireframes.