 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToLL: Topological Layout Learning with Structural Multi-view Augmentation for 3D Scene Graph Pretraining
Mar 30, 20263D Scene Graph (3DSG) generation plays a pivotal role in spatial understanding and semantic-affordance perception. However, its generalizability is often constrained by data scarcity. Current solutions primarily focus on cross-modal assisted representation learning and object-centric generation pre-training. The former relies heavily on predicate annotations, while the latter's predicate learning may be bypassed due to strong object priors. Consequently, they could not often provide a label-free and robust self-supervised proxy task for 3DSG fine-tuning. To bridge this gap, we propose a Topological Layout Learning (ToLL) for 3DSG pretraining framework. In detail, we design an Anchor-Conditioned Topological Geometry Reasoning, with a GNN to recover the global layout of zero-centered subgraphs by the spatial priors from sparse anchors. This process is strictly modulated by predicate features, thereby enforcing the predicate relation learning. Furthermore, we construct a Structural Multi-view Augmentation to avoid semantic corruption, and enhancing representations via self-distillation. The extensive experiments on 3DSSG dataset demonstrate that our ToLL could improve representation quality, outperforming state-of-the-art baselines.
Revisiting Document Image Dewarping by Grid Regularization
Mar 31, 2022

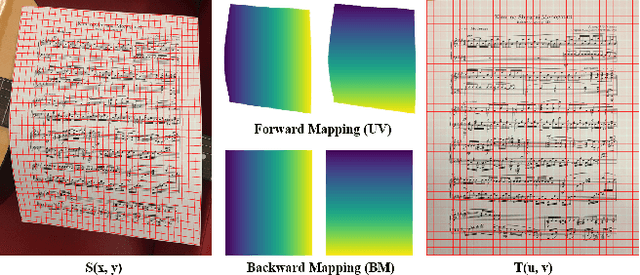
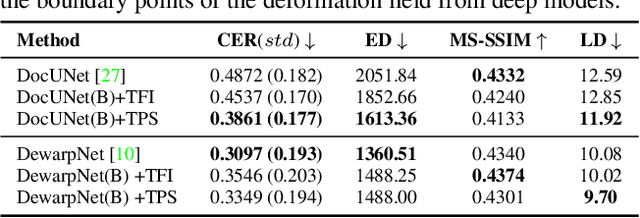
This paper addresses the problem of document image dewarping, which aims at eliminating the geometric distortion in document images for document digitization. Instead of designing a better neural network to approximate the optical flow fields between the inputs and outputs, we pursue the best readability by taking the text lines and the document boundaries into account from a constrained optimization perspective. Specifically, our proposed method first learns the boundary points and the pixels in the text lines and then follows the most simple observation that the boundaries and text lines in both horizontal and vertical directions should be kept after dewarping to introduce a novel grid regularization scheme. To obtain the final forward mapping for dewarping, we solve an optimization problem with our proposed grid regularization. The experiments comprehensively demonstrate that our proposed approach outperforms the prior arts by large margins in terms of readability (with the metrics of Character Errors Rate and the Edit Distance) while maintaining the best image quality on the publicly-available DocUNet benchmark.