 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS: Neuro-anatomical Inductive Priors for Sphere-based Brain Decoding
May 24, 2026Current fMRI decoders face a performance-fidelity trade-off where efficient ID encoders outperform geometrically faithful surface-based models. We argue this is partly driven by inefficient surface tokenization and the failure to use anatomy as a predictive signal. We present NeurIPS, a framework that improves surface-based decoding by reframing anatomical variation from a nuisance to a powerful inductive prior. NeurIPS unites two innovations: a Selective ROI Spherical Tokenizer (SRST) for efficient geometric encoding, and a Structure-Guided Mixture of Experts (SG-MoE) that explicitly models individual anatomy using cortical features. On the Natural Scenes Dataset, NeurIPS establishes a new state-of-the-art for surface decoders and achieves performance comparable to strong 1D baselines. This is achieved with unprecedented efficiency, as the model converges dramatically faster (10 vs. 600 epochs). This efficiency enables rapid adaptation to new subjects using only 20% of data and ensures robust scalability as the training cohort is expanded. Ablations provide causal evidence that these gains are driven by the model's use of cortical features, not by memorizing subject IDs. By leveraging anatomical priors, NeurIPS provides a principled and scalable path toward robust, generalizable brain decoding.
Patched Line Segment Learning for Vector Road Mapping
Sep 06, 2023This paper presents a novel approach to computing vector road maps from satellite remotely sensed images, building upon a well-defined Patched Line Segment (PaLiS) representation for road graphs that holds geometric significance. Unlike prevailing methods that derive road vector representations from satellite images using binary masks or keypoints, our method employs line segments. These segments not only convey road locations but also capture their orientations, making them a robust choice for representation. More precisely, given an input image, we divide it into non-overlapping patches and predict a suitable line segment within each patch. This strategy enables us to capture spatial and structural cues from these patch-based line segments, simplifying the process of constructing the road network graph without the necessity of additional neural networks for connectivity. In our experiments, we demonstrate how an effective representation of a road graph significantly enhances the performance of vector road mapping on established benchmarks, without requiring extensive modifications to the neural network architecture. Furthermore, our method achieves state-of-the-art performance with just 6 GPU hours of training, leading to a substantial 32-fold reduction in training costs in terms of GPU hours.
Accurate Polygonal Mapping of Buildings in Satellite Imagery
Aug 01, 2022
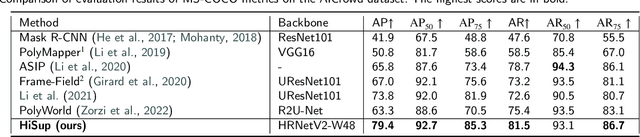
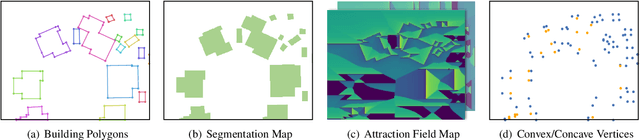

This paper studies the problem of polygonal mapping of buildings by tackling the issue of mask reversibility that leads to a notable performance gap between the predicted masks and polygons from the learning-based methods. We addressed such an issue by exploiting the hierarchical supervision (of bottom-level vertices, mid-level line segments and the high-level regional masks) and proposed a novel interaction mechanism of feature embedding sourced from different levels of supervision signals to obtain reversible building masks for polygonal mapping of buildings. As a result, we show that the learned reversible building masks take all the merits of the advances of deep convolutional neural networks for high-performing polygonal mapping of buildings. In the experiments, we evaluated our method on the two public benchmarks of AICrowd and Inria. On the AICrowd dataset, our proposed method obtains unanimous improvements on the metrics of AP, APboundary and PoLiS. For the Inria dataset, our proposed method also obtains very competitive results on the metrics of IoU and Accuracy. The models and source code are available at https://github.com/SarahwXU.