 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRDrive: An Open Source Mixed Reality Driving Simulator for Automotive User Research
Mar 09, 2026Designing and evaluating in-vehicle interfaces requires experimental platforms that combine ecological validity with experimental control. Driving simulators are widely used for this purpose. However, they face a fundamental trade-off: high-fidelity physical simulators are costly and difficult to adapt, while virtual reality simulators provide flexibility at the expense of physical interaction with the vehicle. In this work, we present MRDrive, an open mixed-reality driving simulator designed to support HCI research on in-vehicle interaction, attention, and explainability in manual and automated driving contexts. MRDrive enables drivers and passengers to interact with a real vehicle cabin while being fully immersed in a virtual driving environment. We demonstrate the capabilities of MRDrive through a small pilot study that illustrates how the simulator can be used to collect and analyze eye-tracking and touch interaction data in an automated driving scenario. MRDRive is available at: https://github.com/ciao-group/mrdrive
Log2Motion: Biomechanical Motion Synthesis from Touch Logs
Jan 28, 2026Touch data from mobile devices are collected at scale but reveal little about the interactions that produce them. While biomechanical simulations can illuminate motor control processes, they have not yet been developed for touch interactions. To close this gap, we propose a novel computational problem: synthesizing plausible motion directly from logs. Our key insight is a reinforcement learning-driven musculoskeletal forward simulation that generates biomechanically plausible motion sequences consistent with events recorded in touch logs. We achieve this by integrating a software emulator into a physics simulator, allowing biomechanical models to manipulate real applications in real-time. Log2Motion produces rich syntheses of user movements from touch logs, including estimates of motion, speed, accuracy, and effort. We assess the plausibility of generated movements by comparing against human data from a motion capture study and prior findings, and demonstrate Log2Motion in a large-scale dataset. Biomechanical motion synthesis provides a new way to understand log data, illuminating the ergonomics and motor control underlying touch interactions.
GTA: Generative Traffic Agents for Simulating Realistic Mobility Behavior
Jan 27, 2026People's transportation choices reflect complex trade-offs shaped by personal preferences, social norms, and technology acceptance. Predicting such behavior at scale is a critical challenge with major implications for urban planning and sustainable transport. Traditional methods use handcrafted assumptions and costly data collection, making them impractical for early-stage evaluations of new technologies or policies. We introduce Generative Traffic Agents (GTA) for simulating large-scale, context-sensitive transportation choices using LLM-powered, persona-based agents. GTA generates artificial populations from census-based sociodemographic data. It simulates activity schedules and mode choices, enabling scalable, human-like simulations without handcrafted rules. We evaluate GTA in Berlin-scale experiments, comparing simulation results against empirical data. While agents replicate patterns, such as modal split by socioeconomic status, they show systematic biases in trip length and mode preference. GTA offers new opportunities for modeling how future innovations, from bike lanes to transit apps, shape mobility decisions.
SHRUG-FM: Reliability-Aware Foundation Models for Earth Observation
Nov 13, 2025Geospatial foundation models for Earth observation often fail to perform reliably in environments underrepresented during pretraining. We introduce SHRUG-FM, a framework for reliability-aware prediction that integrates three complementary signals: out-of-distribution (OOD) detection in the input space, OOD detection in the embedding space and task-specific predictive uncertainty. Applied to burn scar segmentation, SHRUG-FM shows that OOD scores correlate with lower performance in specific environmental conditions, while uncertainty-based flags help discard many poorly performing predictions. Linking these flags to land cover attributes from HydroATLAS shows that failures are not random but concentrated in certain geographies, such as low-elevation zones and large river areas, likely due to underrepresentation in pretraining data. SHRUG-FM provides a pathway toward safer and more interpretable deployment of GFMs in climate-sensitive applications, helping bridge the gap between benchmark performance and real-world reliability.
Off to new Shores: A Dataset & Benchmark for (near-)coastal Flood Inundation Forecasting
Sep 27, 2024



Floods are among the most common and devastating natural hazards, imposing immense costs on our society and economy due to their disastrous consequences. Recent progress in weather prediction and spaceborne flood mapping demonstrated the feasibility of anticipating extreme events and reliably detecting their catastrophic effects afterwards. However, these efforts are rarely linked to one another and there is a critical lack of datasets and benchmarks to enable the direct forecasting of flood extent. To resolve this issue, we curate a novel dataset enabling a timely prediction of flood extent. Furthermore, we provide a representative evaluation of state-of-the-art methods, structured into two benchmark tracks for forecasting flood inundation maps i) in general and ii) focused on coastal regions. Altogether, our dataset and benchmark provide a comprehensive platform for evaluating flood forecasts, enabling future solutions for this critical challenge. Data, code & models are shared at https://github.com/Multihuntr/GFF under a CC0 license.
Implicit Assimilation of Sparse In Situ Data for Dense & Global Storm Surge Forecasting
Apr 05, 2024



Hurricanes and coastal floods are among the most disastrous natural hazards. Both are intimately related to storm surges, as their causes and effects, respectively. However, the short-term forecasting of storm surges has proven challenging, especially when targeting previously unseen locations or sites without tidal gauges. Furthermore, recent work improved short and medium-term weather forecasting but the handling of raw unassimilated data remains non-trivial. In this paper, we tackle both challenges and demonstrate that neural networks can implicitly assimilate sparse in situ tide gauge data with coarse ocean state reanalysis in order to forecast storm surges. We curate a global dataset to learn and validate the dense prediction of storm surges, building on preceding efforts. Other than prior work limited to known gauges, our approach extends to ungauged sites, paving the way for global storm surge forecasting.
UnCRtainTS: Uncertainty Quantification for Cloud Removal in Optical Satellite Time Series
Apr 11, 2023Clouds and haze often occlude optical satellite images, hindering continuous, dense monitoring of the Earth's surface. Although modern deep learning methods can implicitly learn to ignore such occlusions, explicit cloud removal as pre-processing enables manual interpretation and allows training models when only few annotations are available. Cloud removal is challenging due to the wide range of occlusion scenarios -- from scenes partially visible through haze, to completely opaque cloud coverage. Furthermore, integrating reconstructed images in downstream applications would greatly benefit from trustworthy quality assessment. In this paper, we introduce UnCRtainTS, a method for multi-temporal cloud removal combining a novel attention-based architecture, and a formulation for multivariate uncertainty prediction. These two components combined set a new state-of-the-art performance in terms of image reconstruction on two public cloud removal datasets. Additionally, we show how the well-calibrated predicted uncertainties enable a precise control of the reconstruction quality.
High-Resolution Cloud Removal with Multi-Modal and Multi-Resolution Data Fusion: A New Baseline and Benchmark
Jan 09, 2023



In this paper, we introduce Planet-CR, a benchmark dataset for high-resolution cloud removal with multi-modal and multi-resolution data fusion. Planet-CR is the first public dataset for cloud removal to feature globally sampled high resolution optical observations, in combination with paired radar measurements as well as pixel-level land cover annotations. It provides solid basis for exhaustive evaluation in terms of generating visually pleasing textures and semantically meaningful structures. With this dataset, we consider the problem of cloud removal in high resolution optical remote sensing imagery by integrating multi-modal and multi-resolution information. Existing multi-modal data fusion based methods, which assume the image pairs are aligned pixel-to-pixel, are hence not appropriate for this problem. To this end, we design a new baseline named Align-CR to perform the low-resolution SAR image guided high-resolution optical image cloud removal. It implicitly aligns the multi-modal and multi-resolution data during the reconstruction process to promote the cloud removal performance. The experimental results demonstrate that the proposed Align-CR method gives the best performance in both visual recovery quality and semantic recovery quality. The project is available at https://github.com/zhu-xlab/Planet-CR, and hope this will inspire future research.
On the Forces of Driver Distraction: Explainable Predictions for the Visual Demand of In-Vehicle Touchscreen Interactions
Jan 05, 2023



With modern infotainment systems, drivers are increasingly tempted to engage in secondary tasks while driving. Since distracted driving is already one of the main causes of fatal accidents, in-vehicle touchscreen Human-Machine Interfaces (HMIs) must be as little distracting as possible. To ensure that these systems are safe to use, they undergo elaborate and expensive empirical testing, requiring fully functional prototypes. Thus, early-stage methods informing designers about the implication their design may have on driver distraction are of great value. This paper presents a machine learning method that, based on anticipated usage scenarios, predicts the visual demand of in-vehicle touchscreen interactions and provides local and global explanations of the factors influencing drivers' visual attention allocation. The approach is based on large-scale natural driving data continuously collected from production line vehicles and employs the SHapley Additive exPlanation (SHAP) method to provide explanations leveraging informed design decisions. Our approach is more accurate than related work and identifies interactions during which long glances occur with 68 % accuracy and predicts the total glance duration with a mean error of 2.4 s. Our explanations replicate the results of various recent studies and provide fast and easily accessible insights into the effect of UI elements, driving automation, and vehicle speed on driver distraction. The system can not only help designers to evaluate current designs but also help them to better anticipate and understand the implications their design decisions might have on future designs.
Exploring the Potential of SAR Data for Cloud Removal in Optical Satellite Imagery
Jun 06, 2022
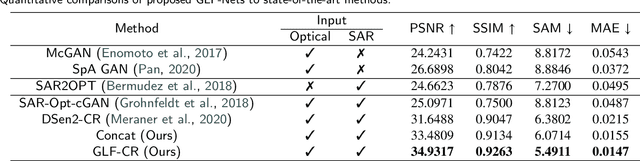
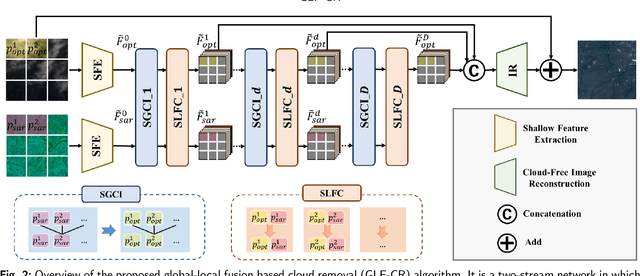
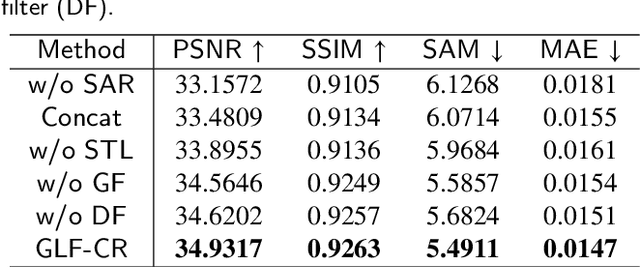
The challenge of the cloud removal task can be alleviated with the aid of Synthetic Aperture Radar (SAR) images that can penetrate cloud cover. However, the large domain gap between optical and SAR images as well as the severe speckle noise of SAR images may cause significant interference in SAR-based cloud removal, resulting in performance degeneration. In this paper, we propose a novel global-local fusion based cloud removal (GLF-CR) algorithm to leverage the complementary information embedded in SAR images. Exploiting the power of SAR information to promote cloud removal entails two aspects. The first, global fusion, guides the relationship among all local optical windows to maintain the structure of the recovered region consistent with the remaining cloud-free regions. The second, local fusion, transfers complementary information embedded in the SAR image that corresponds to cloudy areas to generate reliable texture details of the missing regions, and uses dynamic filtering to alleviate the performance degradation caused by speckle noise. Extensive evaluation demonstrates that the proposed algorithm can yield high quality cloud-free images and performs favorably against state-of-the-art cloud removal algorithms.