 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Calibrated Human-in-the-Loop Reinforcement Learning for Robotic Manipulation
Jun 02, 2026Human-in-the-loop reinforcement learning (HIL-RL) improves sample efficiency in real-robot manipulation through online human intervention. However, successful trajectories may include suboptimal actions that deviate from the desired task-execution path and force human intervention. Existing HIL-RL methods typically apply the consistent credit assignment principle to all transitions, uniformly propagating discounted terminal rewards through suboptimal segments, ignoring the actual contribution of each transition to task success. This overestimates Q-values for critic learning and indirectly misguides actor updates toward suboptimal behavior patterns. To this end, we propose PACT, a Preference-calibrated Actor-Critic Training framework that leverages the implicit preference signals induced by intervention to perform credit reassignment on identified suboptimal segments while directly guiding policy training for unbiased critic-actor learning. Specifically, we first design a progress model that learns from human demonstration and identifies suboptimal segments for credit correction. Then, from the human action and resampled policy action at the intervention state, we build preference pairs to define a counterfactual advantage that penalizes Bellman targets of the identified suboptimal segment, enabling directional credit calibration. Moreover, we directly align the policy with human corrective actions in the bounded mean space, providing an additional signal beyond critic-guided updates. Across five real-robot manipulation tasks, PACT improves the average success rate by 24.5% and achieves 1.3 times faster convergence, thereby improving both RL sample efficiency and performance. Code is available at https://anonymous.4open.science/r/HILRL-A1X-BC05.
ProUIE: A Macro-to-Micro Progressive Learning Method for LLM-based Universal Information Extraction
Apr 12, 2026LLM-based universal information extraction (UIE) methods often rely on additional information beyond the original training data, which increases training complexity yet often yields limited gains. To address this, we propose ProUIE, a Macro-to-Micro progressive learning approach that improves UIE without introducing any external information. ProUIE consists of three stages: (i) macro-level Complete Modeling (CM), which learns NER, RE, and EE along their intrinsic difficulty order on the full training data to build a unified extraction foundation, (ii) meso-level Streamlined Alignment (SA), which operates on sampled data with simplified target formats, streamlining and regularizing structured outputs to make them more concise and controllable, and (iii) micro-level Deep Exploration (DE), which applies GRPO with stepwise fine-grained rewards (SFR) over structural units to guide exploration and improve performance. Experiments on 36 public datasets show that ProUIE consistently improves unified extraction, outperforming strong instruction-tuned baselines on average for NER and RE while using a smaller backbone, and it further demonstrates clear gains in large-scale production-oriented information extraction.
Unified Multimodal and Multilingual Retrieval via Multi-Task Learning with NLU Integration
Jan 21, 2026Multimodal retrieval systems typically employ Vision Language Models (VLMs) that encode images and text independently into vectors within a shared embedding space. Despite incorporating text encoders, VLMs consistently underperform specialized text models on text-only retrieval tasks. Moreover, introducing additional text encoders increases storage, inference overhead, and exacerbates retrieval inefficiencies, especially in multilingual settings. To address these limitations, we propose a multi-task learning framework that unifies the feature representation across images, long and short texts, and intent-rich queries. To our knowledge, this is the first work to jointly optimize multilingual image retrieval, text retrieval, and natural language understanding (NLU) tasks within a single framework. Our approach integrates image and text retrieval with a shared text encoder that is enhanced by NLU features for intent understanding and retrieval accuracy.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025



Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
Multiple-Mode Affine Frequency Division Multiplexing with Index Modulation
Jul 17, 2025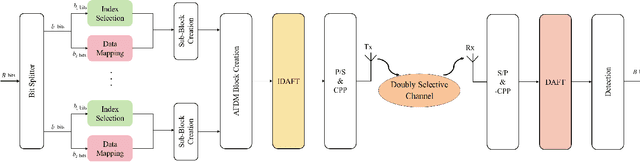
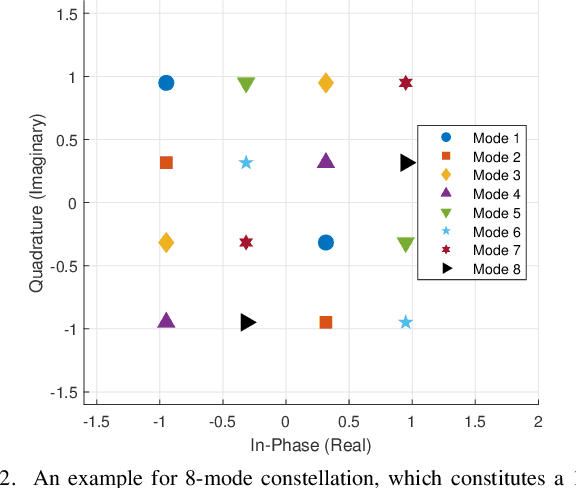
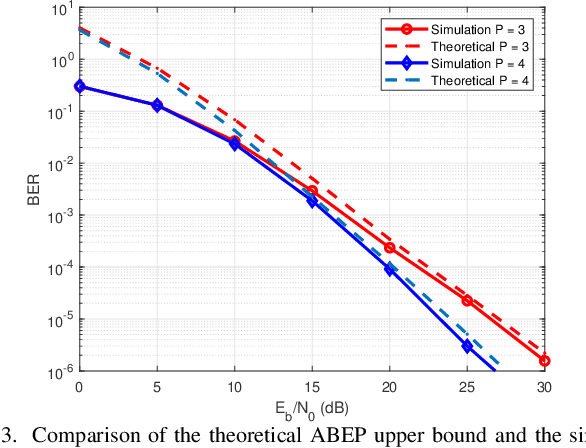
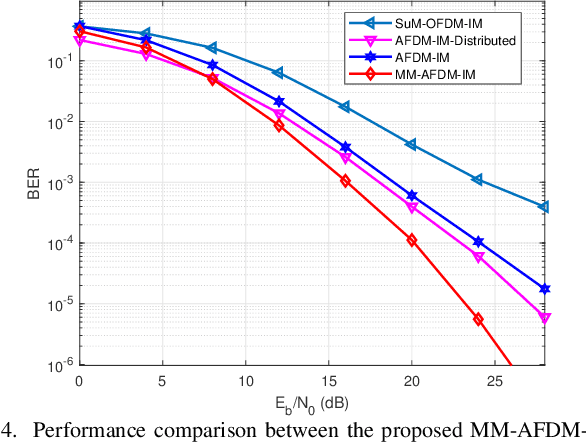
Affine frequency division multiplexing (AFDM), a promising multicarrier technique utilizing chirp signals, has been envisioned as an effective solution for high-mobility communication scenarios. In this paper, we develop a multiple-mode index modulation scheme tailored for AFDM, termed as MM-AFDM-IM, which aims to further improve the spectral and energy efficiencies of AFDM. Specifically, multiple constellation alphabets are selected for different chirp-based subcarriers (chirps). Aside from classical amplitude/phase modulation, additional information bits can be conveyed by the dynamic patterns of both constellation mode selection and chirp activation, without extra energy consumption. Furthermore, we discuss the mode selection strategy and derive an asymptotically tight upper bound on the bit error rate (BER) of the proposed scheme under maximum-likelihood detection. Simulation results are provided to demonstrate the superior performance of MM-AFDM-IM compared to conventional benchmark schemes.
Intelligent Metasurface-Enabled Integrated Sensing and Communication: Unified Framework and Key Technologies
Jun 16, 2025



As the demand for ubiquitous connectivity and high-precision environmental awareness grows, integrated sensing and communication (ISAC) has emerged as a key technology for sixth-generation (6G) wireless networks. Intelligent metasurfaces (IMs) have also been widely adopted in ISAC scenarios due to their efficient, programmable control over electromagnetic waves. This provides a versatile solution that meets the dual-function requirements of next-generation networks. Although reconfigurable intelligent surfaces (RISs) have been extensively studied for manipulating the propagation channel between base and mobile stations, the full potential of IMs in ISAC transceiver design remains under-explored. Against this backdrop, this article explores emerging IM-enabled transceiver designs for ISAC systems. It begins with an overview of representative IM architectures, their unique principles, and their inherent advantages in EM wave manipulation. Next, a unified ISAC framework is established to systematically model the design and derivation of diverse IM-enabled transceiver structures. This lays the foundation for performance optimization, trade-offs, and analysis. The paper then discusses several critical technologies for IM-enabled ISAC transceivers, including dedicated channel modeling, effective channel estimation, tailored beamforming strategies, and dual-functional waveform design.
Pre-Chirp-Domain Index Modulation for Affine Frequency Division Multiplexing
Feb 23, 2024



Affine frequency division multiplexing (AFDM), tailored as a novel multicarrier technique utilizing chirp signals for high-mobility communications, exhibits marked advantages compared to traditional orthogonal frequency division multiplexing (OFDM). AFDM is based on the discrete affine Fourier transform (DAFT) with two modifiable parameters of the chirp signals, termed as the pre-chirp parameter and post-chirp parameter, respectively. These parameters can be fine-tuned to avoid overlapping channel paths with different delays or Doppler shifts, leading to performance enhancement especially for doubly dispersive channel. In this paper, we propose a novel AFDM structure with the pre-chirp index modulation (PIM) philosophy (AFDM-PIM), which can embed additional information bits into the pre-chirp parameter design for both spectral and energy efficiency enhancement. Specifically, we first demonstrate that the application of distinct pre-chirp parameters to various subcarriers in the AFDM modulation process maintains the orthogonality among these subcarriers. Then, different pre-chirp parameters are flexibly assigned to each AFDM subcarrier according to the incoming bits. By such arrangement, aside from classical phase/amplitude modulation, extra binary bits can be implicitly conveyed by the indices of selected pre-chirping parameters realizations without additional energy consumption. At the receiver, both a maximum likelihood (ML) detector and a reduced-complexity ML-minimum mean square error (ML-MMSE) detector are employed to recover the information bits. It has been shown via simulations that the proposed AFDM-PIM exhibits superior bit error rate (BER) performance compared to classical AFDM, OFDM and IM-aided OFDM algorithms.