 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Train one, Classify one, Teach one" -- Cross-surgery transfer learning for surgical step recognition
Feb 24, 2021
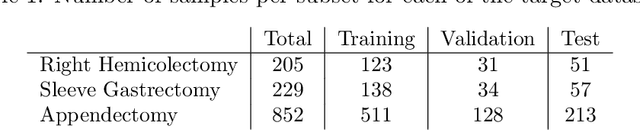

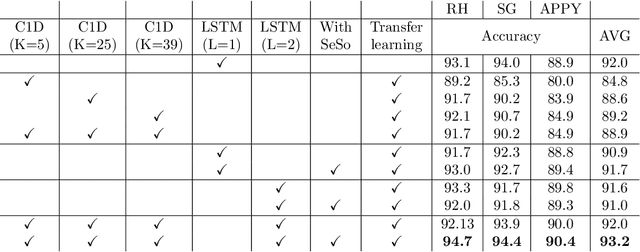
Prior work demonstrated the ability of machine learning to automatically recognize surgical workflow steps from videos. However, these studies focused on only a single type of procedure. In this work, we analyze, for the first time, surgical step recognition on four different laparoscopic surgeries: Cholecystectomy, Right Hemicolectomy, Sleeve Gastrectomy, and Appendectomy. Inspired by the traditional apprenticeship model, in which surgical training is based on the Halstedian method, we paraphrase the "see one, do one, teach one" approach for the surgical intelligence domain as "train one, classify one, teach one". In machine learning, this approach is often referred to as transfer learning. To analyze the impact of transfer learning across different laparoscopic procedures, we explore various time-series architectures and examine their performance on each target domain. We introduce a new architecture, the Time-Series Adaptation Network (TSAN), an architecture optimized for transfer learning of surgical step recognition, and we show how TSAN can be pre-trained using self-supervised learning on a Sequence Sorting task. Such pre-training enables TSAN to learn workflow steps of a new laparoscopic procedure type from only a small number of labeled samples from the target procedure. Our proposed architecture leads to better performance compared to other possible architectures, reaching over 90% accuracy when transferring from laparoscopic Cholecystectomy to the other three procedure types.
SAFCAR: Structured Attention Fusion for Compositional Action Recognition
Dec 17, 2020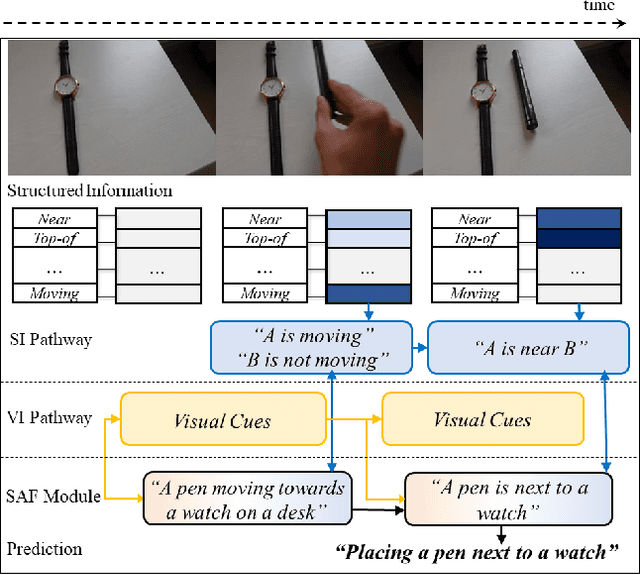
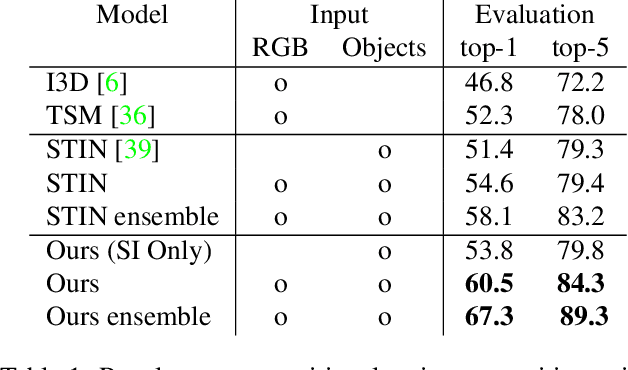
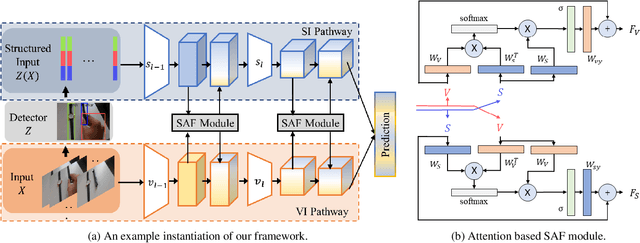
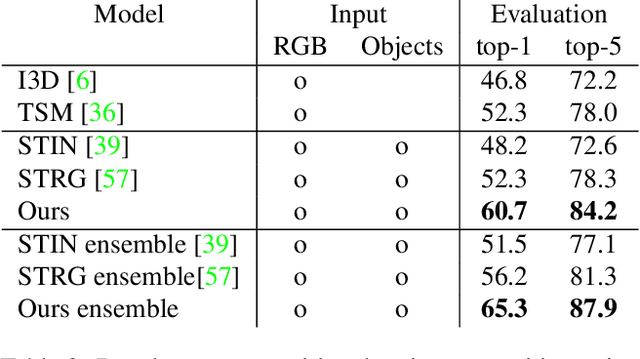
We present a general framework for compositional action recognition -- i.e. action recognition where the labels are composed out of simpler components such as subjects, atomic-actions and objects. The main challenge in compositional action recognition is that there is a combinatorially large set of possible actions that can be composed using basic components. However, compositionality also provides a structure that can be exploited. To do so, we develop and test a novel Structured Attention Fusion (SAF) self-attention mechanism to combine information from object detections, which capture the time-series structure of an action, with visual cues that capture contextual information. We show that our approach recognizes novel verb-noun compositions more effectively than current state of the art systems, and it generalizes to unseen action categories quite efficiently from only a few labeled examples. We validate our approach on the challenging Something-Else tasks from the Something-Something-V2 dataset. We further show that our framework is flexible and can generalize to a new domain by showing competitive results on the Charades-Fewshot dataset.
Orientation Matters: 6-DoF Autonomous Camera Movement for Minimally Invasive Surgery
Dec 04, 2020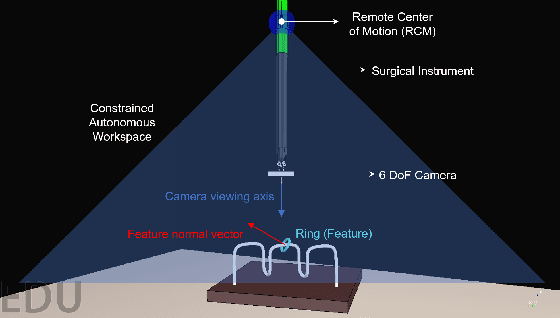
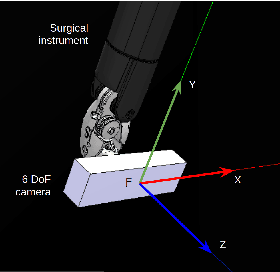
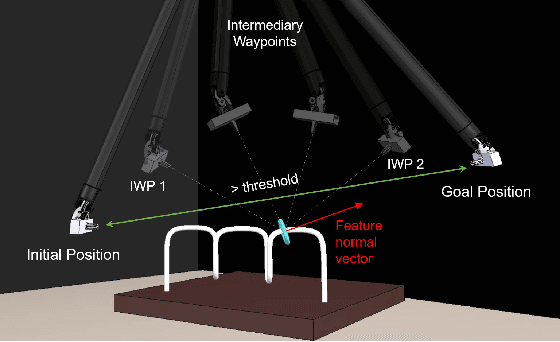
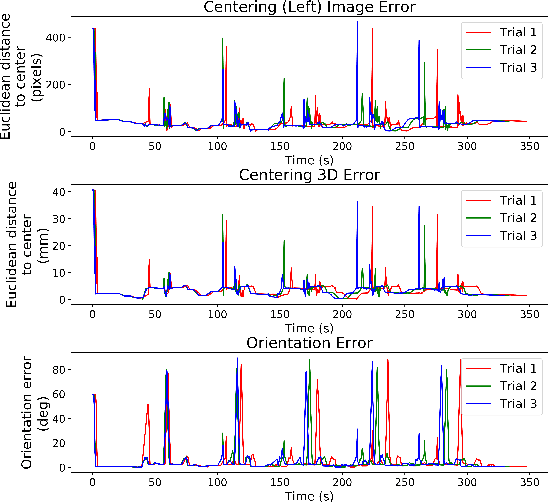
We propose a new method for six-degree-of-freedom (6-DoF) autonomous camera movement for minimally invasive surgery, which, unlike previous methods, takes into account both the position and orientation information from structures in the surgical scene. In addition to locating the camera for a good view of the manipulated object, our autonomous camera takes into account workspace constraints, including the horizon and safety constraints. We developed a simulation environment to test our method on the "wire chaser" surgical training task from validated training curricula in conventional laparoscopy and robot-assisted surgery. Furthermore, we propose, for the first time, the application of the proposed autonomous camera method in video-based surgical skill assessment, an area where videos are typically recorded using fixed cameras. In a study with N=30 human subjects, we show that video examination of the autonomous camera view as it tracks the ring motion over the wire leads to more accurate user error (ring touching the wire) detection than when using a fixed camera view, or camera movement with a fixed orientation. Our preliminary work suggests that there are potential benefits to autonomous camera positioning informed by scene orientation, and this can direct designers of automated endoscopes and surgical robotic systems, especially when using chip-on-tip cameras that can be wristed for 6-DoF motion.
Fine-grained activity recognition for assembly videos
Dec 02, 2020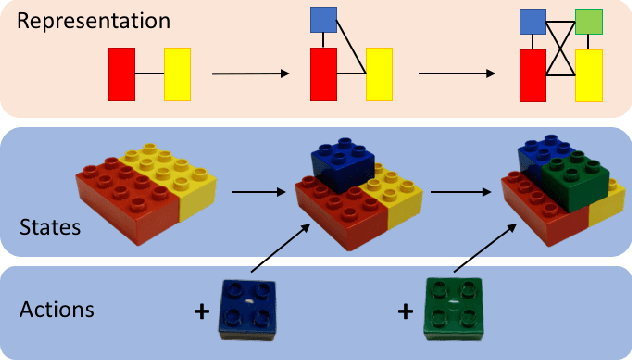
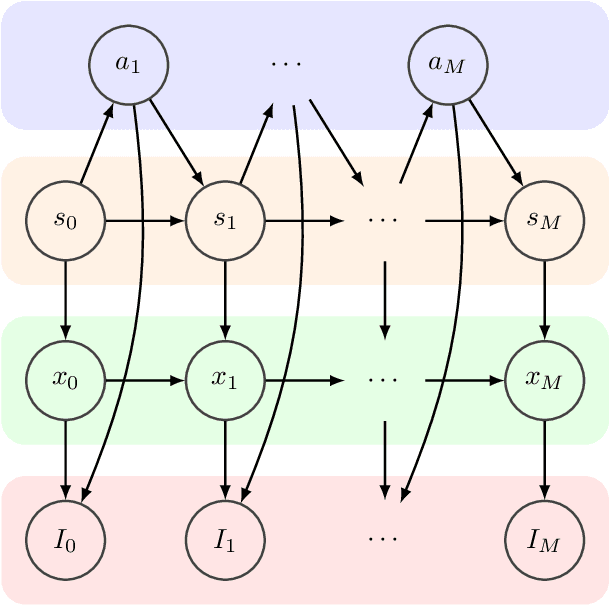

In this paper we address the task of recognizing assembly actions as a structure (e.g. a piece of furniture or a toy block tower) is built up from a set of primitive objects. Recognizing the full range of assembly actions requires perception at a level of spatial detail that has not been attempted in the action recognition literature to date. We extend the fine-grained activity recognition setting to address the task of assembly action recognition in its full generality by unifying assembly actions and kinematic structures within a single framework. We use this framework to develop a general method for recognizing assembly actions from observation sequences, along with observation features that take advantage of a spatial assembly's special structure. Finally, we evaluate our method empirically on two application-driven data sources: (1) An IKEA furniture-assembly dataset, and (2) A block-building dataset. On the first, our system recognizes assembly actions with an average framewise accuracy of 70% and an average normalized edit distance of 10%. On the second, which requires fine-grained geometric reasoning to distinguish between assemblies, our system attains an average normalized edit distance of 23% -- a relative improvement of 69% over prior work.
Nothing But Geometric Constraints: A Model-Free Method for Articulated Object Pose Estimation
Nov 30, 2020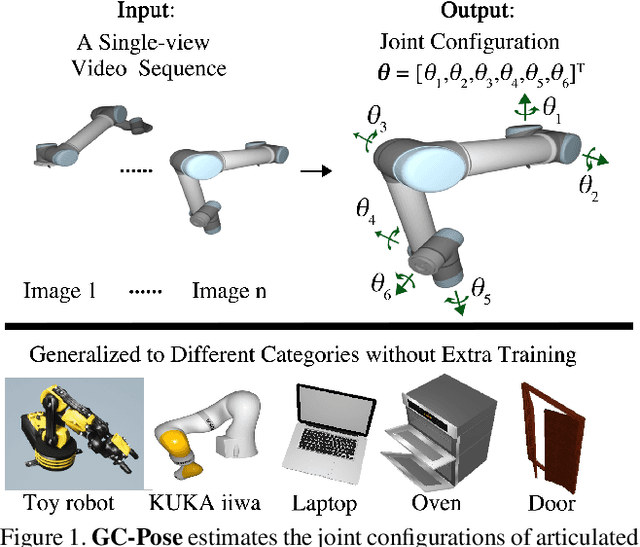

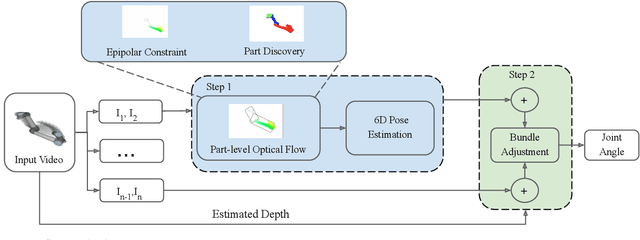

We propose an unsupervised vision-based system to estimate the joint configurations of the robot arm from a sequence of RGB or RGB-D images without knowing the model a priori, and then adapt it to the task of category-independent articulated object pose estimation. We combine a classical geometric formulation with deep learning and extend the use of epipolar constraint to multi-rigid-body systems to solve this task. Given a video sequence, the optical flow is estimated to get the pixel-wise dense correspondences. After that, the 6D pose is computed by a modified PnP algorithm. The key idea is to leverage the geometric constraints and the constraint between multiple frames. Furthermore, we build a synthetic dataset with different kinds of robots and multi-joint articulated objects for the research of vision-based robot control and robotic vision. We demonstrate the effectiveness of our method on three benchmark datasets and show that our method achieves higher accuracy than the state-of-the-art supervised methods in estimating joint angles of robot arms and articulated objects.
Autonomously Navigating a Surgical Tool Inside the Eye by Learning from Demonstration
Nov 16, 2020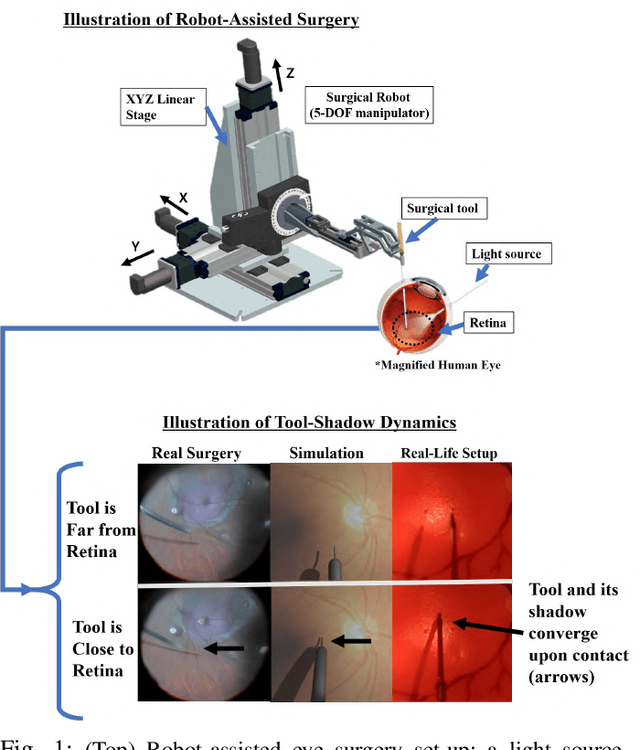
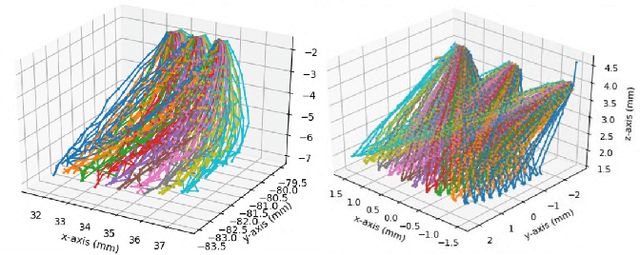
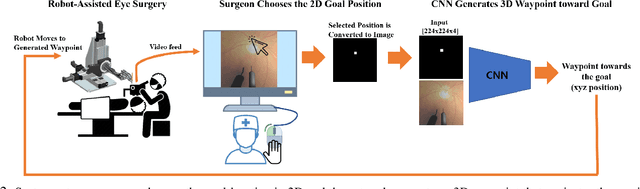
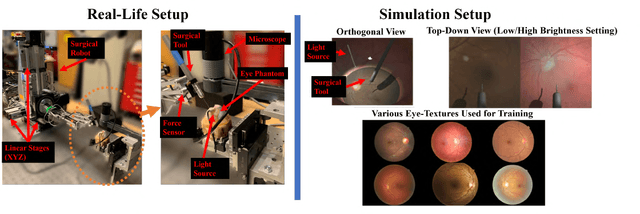
A fundamental challenge in retinal surgery is safely navigating a surgical tool to a desired goal position on the retinal surface while avoiding damage to surrounding tissues, a procedure that typically requires tens-of-microns accuracy. In practice, the surgeon relies on depth-estimation skills to localize the tool-tip with respect to the retina in order to perform the tool-navigation task, which can be prone to human error. To alleviate such uncertainty, prior work has introduced ways to assist the surgeon by estimating the tool-tip distance to the retina and providing haptic or auditory feedback. However, automating the tool-navigation task itself remains unsolved and largely unexplored. Such a capability, if reliably automated, could serve as a building block to streamline complex procedures and reduce the chance for tissue damage. Towards this end, we propose to automate the tool-navigation task by learning to mimic expert demonstrations of the task. Specifically, a deep network is trained to imitate expert trajectories toward various locations on the retina based on recorded visual servoing to a given goal specified by the user. The proposed autonomous navigation system is evaluated in simulation and in physical experiments using a silicone eye phantom. We show that the network can reliably navigate a needle surgical tool to various desired locations within 137 microns accuracy in physical experiments and 94 microns in simulation on average, and generalizes well to unseen situations such as in the presence of auxiliary surgical tools, variable eye backgrounds, and brightness conditions.
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020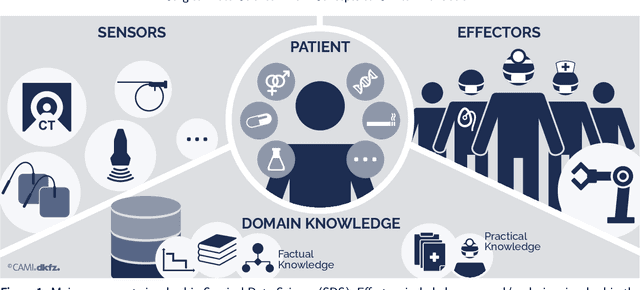
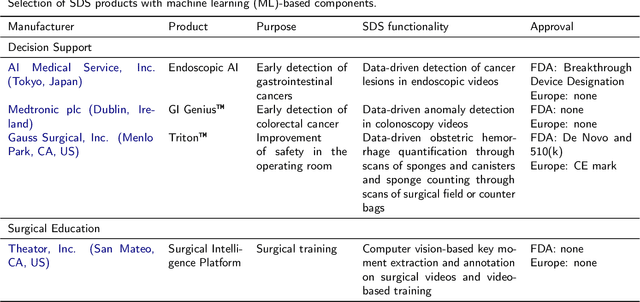
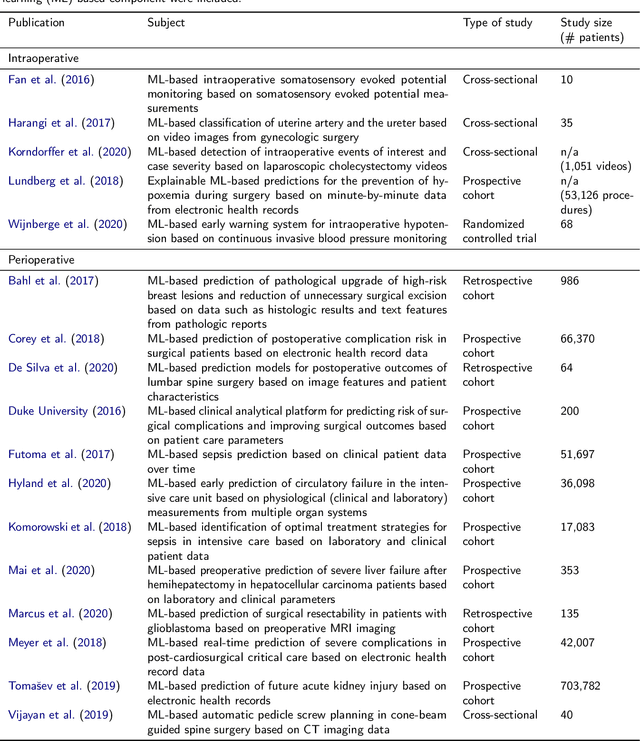
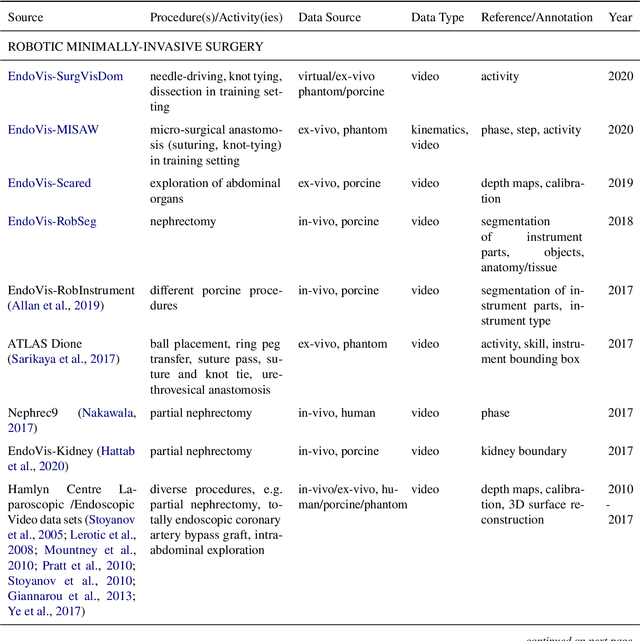
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.
Deep Hiearchical Multi-Label Classification Applied to Chest X-Ray Abnormality Taxonomies
Sep 23, 2020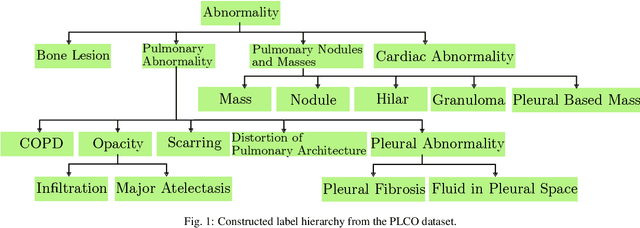
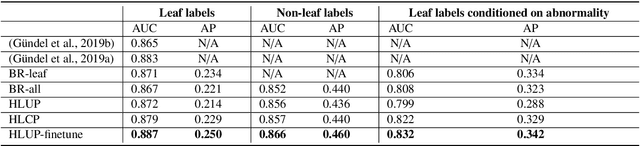
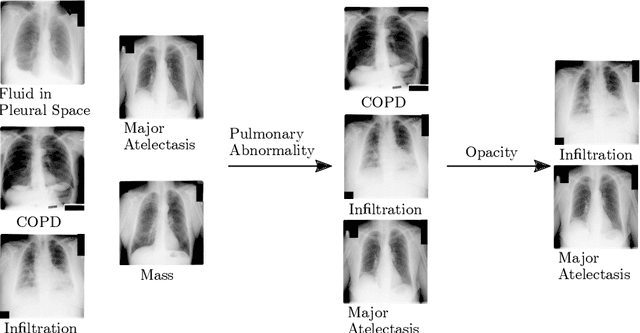
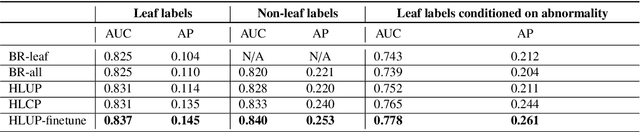
CXRs are a crucial and extraordinarily common diagnostic tool, leading to heavy research for CAD solutions. However, both high classification accuracy and meaningful model predictions that respect and incorporate clinical taxonomies are crucial for CAD usability. To this end, we present a deep HMLC approach for CXR CAD. Different than other hierarchical systems, we show that first training the network to model conditional probability directly and then refining it with unconditional probabilities is key in boosting performance. In addition, we also formulate a numerically stable cross-entropy loss function for unconditional probabilities that provides concrete performance improvements. Finally, we demonstrate that HMLC can be an effective means to manage missing or incomplete labels. To the best of our knowledge, we are the first to apply HMLC to medical imaging CAD. We extensively evaluate our approach on detecting abnormality labels from the CXR arm of the PLCO dataset, which comprises over $198,000$ manually annotated CXRs. When using complete labels, we report a mean AUC of 0.887, the highest yet reported for this dataset. These results are supported by ancillary experiments on the PadChest dataset, where we also report significant improvements, 1.2% and 4.1% in AUC and AP, respectively over strong "flat" classifiers. Finally, we demonstrate that our HMLC approach can much better handle incompletely labelled data. These performance improvements, combined with the inherent usefulness of taxonomic predictions, indicate that our approach represents a useful step forward for CXR CAD.
Learning Representations of Endoscopic Videos to Detect Tool Presence Without Supervision
Aug 27, 2020
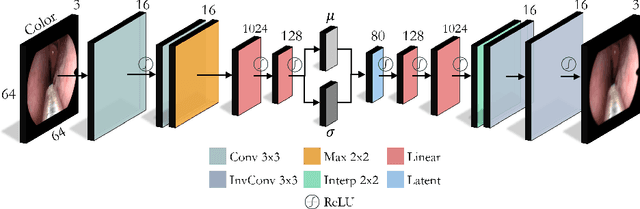
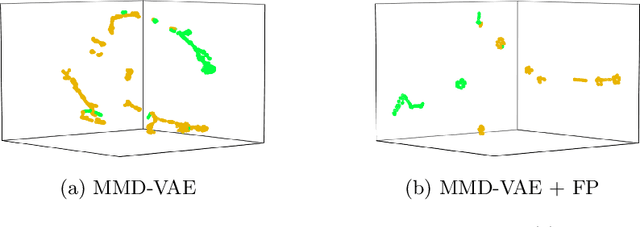
In this work, we explore whether it is possible to learn representations of endoscopic video frames to perform tasks such as identifying surgical tool presence without supervision. We use a maximum mean discrepancy (MMD) variational autoencoder (VAE) to learn low-dimensional latent representations of endoscopic videos and manipulate these representations to distinguish frames containing tools from those without tools. We use three different methods to manipulate these latent representations in order to predict tool presence in each frame. Our fully unsupervised methods can identify whether endoscopic video frames contain tools with average precision of 71.56, 73.93, and 76.18, respectively, comparable to supervised methods. Our code is available at https://github.com/zdavidli/tool-presence/
Anatomy-Aware Siamese Network: Exploiting Semantic Asymmetry for Accurate Pelvic Fracture Detection in X-ray Images
Jul 12, 2020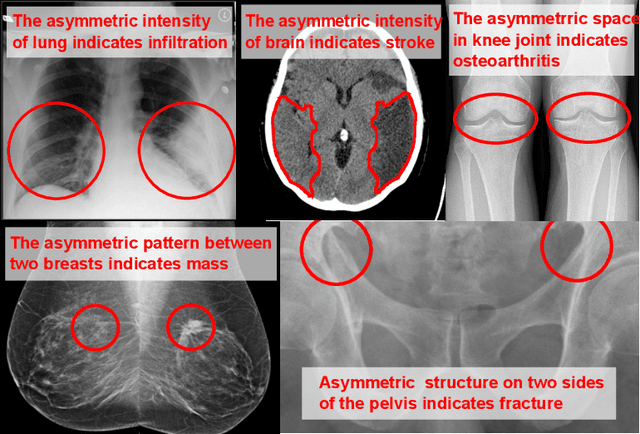
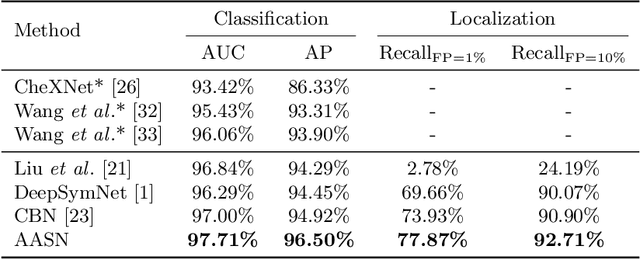
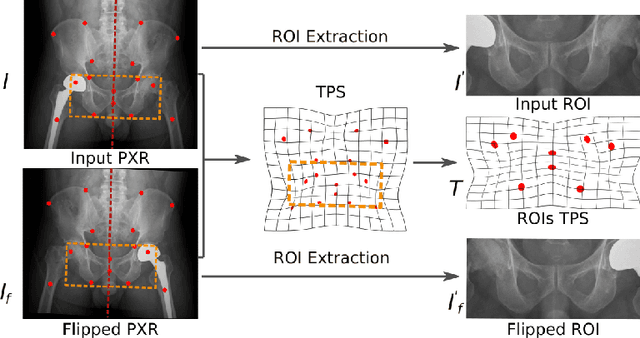
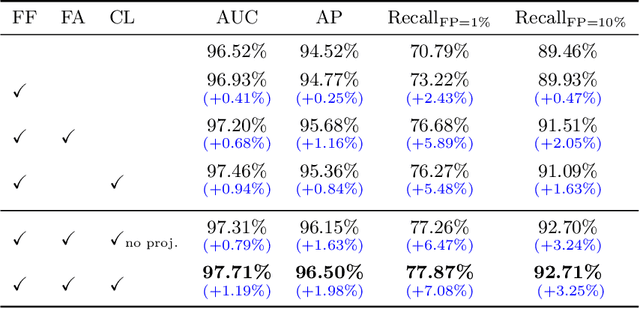
Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.