 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedTalk: Triplane-Free Talking Head Synthesis using Embedding-Driven Gaussian Deformation
Mar 08, 2026Real-time talking head synthesis increasingly relies on deformable 3D Gaussian Splatting (3DGS) due to its low latency. Tri-planes are the standard choice for encoding Gaussians prior to deformation, since they provide a continuous domain with explicit spatial relationships. However, tri-plane representations are limited by grid resolution and approximation errors introduced by projecting 3D volumetric fields onto 2D subspaces. Recent work has shown the superiority of learnt embeddings for driving temporal deformations in 4D scene reconstruction. We introduce $\textbf{EmbedTalk}$, which shows how such embeddings can be leveraged for modelling speech deformations in talking head synthesis. Through comprehensive experiments, we show that EmbedTalk outperforms existing 3DGS-based methods in rendering quality, lip synchronisation, and motion consistency, while remaining competitive with state-of-the-art generative models. Moreover, replacing the tri-plane encoding with learnt embeddings enables significantly more compact models that achieve over 60 FPS on a mobile GPU (RTX 2060 6 GB). Our code will be placed in the public domain on acceptance.
NeeCo: Image Synthesis of Novel Instrument States Based on Dynamic and Deformable 3D Gaussian Reconstruction
Aug 11, 2025



Computer vision-based technologies significantly enhance surgical automation by advancing tool tracking, detection, and localization. However, Current data-driven approaches are data-voracious, requiring large, high-quality labeled image datasets, which limits their application in surgical data science. Our Work introduces a novel dynamic Gaussian Splatting technique to address the data scarcity in surgical image datasets. We propose a dynamic Gaussian model to represent dynamic surgical scenes, enabling the rendering of surgical instruments from unseen viewpoints and deformations with real tissue backgrounds. We utilize a dynamic training adjustment strategy to address challenges posed by poorly calibrated camera poses from real-world scenarios. Additionally, we propose a method based on dynamic Gaussians for automatically generating annotations for our synthetic data. For evaluation, we constructed a new dataset featuring seven scenes with 14,000 frames of tool and camera motion and tool jaw articulation, with a background of an ex-vivo porcine model. Using this dataset, we synthetically replicate the scene deformation from the ground truth data, allowing direct comparisons of synthetic image quality. Experimental results illustrate that our method generates photo-realistic labeled image datasets with the highest values in Peak-Signal-to-Noise Ratio (29.87). We further evaluate the performance of medical-specific neural networks trained on real and synthetic images using an unseen real-world image dataset. Our results show that the performance of models trained on synthetic images generated by the proposed method outperforms those trained with state-of-the-art standard data augmentation by 10%, leading to an overall improvement in model performances by nearly 15%.
Score Before You Speak: Improving Persona Consistency in Dialogue Generation using Response Quality Scores
Aug 09, 2025



Persona-based dialogue generation is an important milestone towards building conversational artificial intelligence. Despite the ever-improving capabilities of large language models (LLMs), effectively integrating persona fidelity in conversations remains challenging due to the limited diversity in existing dialogue data. We propose a novel framework SBS (Score-Before-Speaking), which outperforms previous methods and yields improvements for both million and billion-parameter models. Unlike previous methods, SBS unifies the learning of responses and their relative quality into a single step. The key innovation is to train a dialogue model to correlate augmented responses with a quality score during training and then leverage this knowledge at inference. We use noun-based substitution for augmentation and semantic similarity-based scores as a proxy for response quality. Through extensive experiments with benchmark datasets (PERSONA-CHAT and ConvAI2), we show that score-conditioned training allows existing models to better capture a spectrum of persona-consistent dialogues. Our ablation studies also demonstrate that including scores in the input prompt during training is superior to conventional training setups. Code and further details are available at https://arpita2512.github.io/score_before_you_speak
Can Diffusion Models Bridge the Domain Gap in Cardiac MR Imaging?
Aug 08, 2025Magnetic resonance (MR) imaging, including cardiac MR, is prone to domain shift due to variations in imaging devices and acquisition protocols. This challenge limits the deployment of trained AI models in real-world scenarios, where performance degrades on unseen domains. Traditional solutions involve increasing the size of the dataset through ad-hoc image augmentation or additional online training/transfer learning, which have several limitations. Synthetic data offers a promising alternative, but anatomical/structural consistency constraints limit the effectiveness of generative models in creating image-label pairs. To address this, we propose a diffusion model (DM) trained on a source domain that generates synthetic cardiac MR images that resemble a given reference. The synthetic data maintains spatial and structural fidelity, ensuring similarity to the source domain and compatibility with the segmentation mask. We assess the utility of our generative approach in multi-centre cardiac MR segmentation, using the 2D nnU-Net, 3D nnU-Net and vanilla U-Net segmentation networks. We explore domain generalisation, where, domain-invariant segmentation models are trained on synthetic source domain data, and domain adaptation, where, we shift target domain data towards the source domain using the DM. Both strategies significantly improved segmentation performance on data from an unseen target domain, in terms of surface-based metrics (Welch's t-test, p < 0.01), compared to training segmentation models on real data alone. The proposed method ameliorates the need for transfer learning or online training to address domain shift challenges in cardiac MR image analysis, especially useful in data-scarce settings.
SurgRIPE challenge: Benchmark of Surgical Robot Instrument Pose Estimation
Jan 06, 2025



Accurate instrument pose estimation is a crucial step towards the future of robotic surgery, enabling applications such as autonomous surgical task execution. Vision-based methods for surgical instrument pose estimation provide a practical approach to tool tracking, but they often require markers to be attached to the instruments. Recently, more research has focused on the development of marker-less methods based on deep learning. However, acquiring realistic surgical data, with ground truth instrument poses, required for deep learning training, is challenging. To address the issues in surgical instrument pose estimation, we introduce the Surgical Robot Instrument Pose Estimation (SurgRIPE) challenge, hosted at the 26th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) in 2023. The objectives of this challenge are: (1) to provide the surgical vision community with realistic surgical video data paired with ground truth instrument poses, and (2) to establish a benchmark for evaluating markerless pose estimation methods. The challenge led to the development of several novel algorithms that showcased improved accuracy and robustness over existing methods. The performance evaluation study on the SurgRIPE dataset highlights the potential of these advanced algorithms to be integrated into robotic surgery systems, paving the way for more precise and autonomous surgical procedures. The SurgRIPE challenge has successfully established a new benchmark for the field, encouraging further research and development in surgical robot instrument pose estimation.
PlutoNet: An Efficient Polyp Segmentation Network
Apr 12, 2022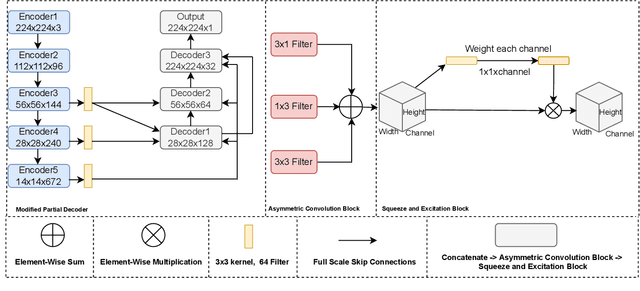
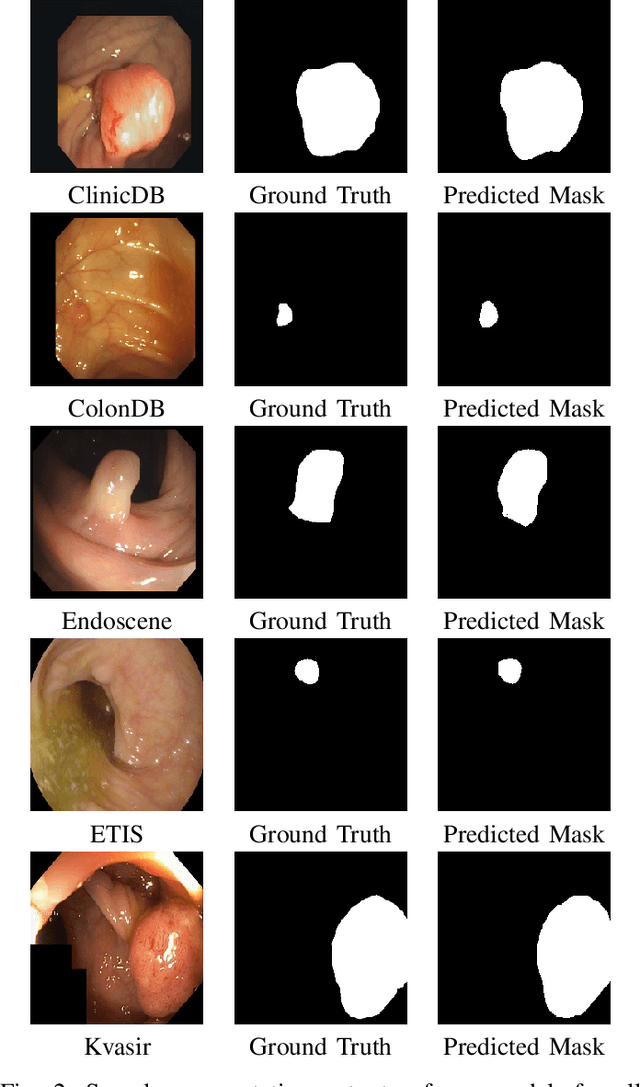

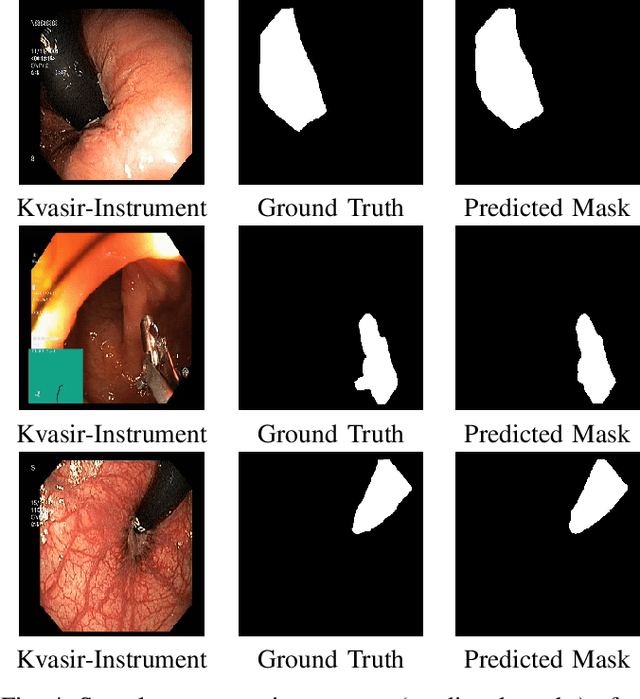
Polyps in the colon can turn into cancerous cells if not removed with early intervention. Deep learning models are used to minimize the number of polyps that goes unnoticed by the experts, and to accurately segment the detected polyps during these interventions. Although these models perform well on these tasks, they require too many parameters, which can pose a problem with real-time applications. To address this problem, we propose a novel segmentation model called PlutoNet which requires only 2,626,337 parameters while outperforming state-of-the-art models on multiple medical image segmentation tasks. We use EfficientNetB0 architecture as a backbone and propose the novel \emph{modified partial decoder}, which is a combination of partial decoder and full scale connections, which further reduces the number of parameters required, as well as captures semantic details. We use asymmetric convolutions to handle varying polyp sizes. Finally, we weight each feature map to improve segmentation by using a squeeze and excitation block. In addition to polyp segmentation in colonoscopy, we tested our model on segmentation of nuclei and surgical instruments to demonstrate its generalizability to different medical image segmentation tasks. Our model outperformed the state-of-the-art models with a Dice score of \%92.3 in CVC-ClinicDB dataset and \%89.3 in EndoScene dataset, a Dice score of \%91.93 on the 2018 Data Science Bowl Challenge dataset, and a Dice score of \%94.8 on Kvasir-Instrument dataset. Our experiments and ablation studies show that our model is superior in terms of accuracy, and it is able generalize well to multiple medical segmentation tasks.
Using Human Gaze For Surgical Activity Recognition
Mar 09, 2022



Automatically recognizing surgical activities plays an important role in providing feedback to surgeons, and is a fundamental step towards computer-aided surgical systems. Human gaze and visual saliency carry important information about visual attention, and can be used in computer vision systems. Although state-of-the-art surgical activity recognition models learn spatial temporal features, none of these models make use of human gaze and visual saliency. In this study, we propose to use human gaze with a spatial temporal attention mechanism for activity recognition in surgical videos. Our model consists of an I3D-based architecture, learns spatio-temporal features using 3D convolutions, as well as learning an attention map using human gaze. We evaluated our model on the Suturing task of JIGSAWS which is a publicly available surgical video understanding dataset. Our evaluations on a subset of random video segments in this task suggest that our approach achieves promising results with an accuracy of 86.2%.
An Efficient Polyp Segmentation Network
Mar 08, 2022Cancer is a disease that occurs as a result of uncontrolled division and proliferation of cells. The number of cancer cases has been on the rise over the recent years.. Colon cancer is one of the most common types of cancer in the world. Polyps that can be seen in the large intestine can cause cancer if not removed with early intervention. Deep learning and image segmentation techniques are used to minimize the number of polyps that goes unnoticed by the experts during the diagnosis. Although these techniques give good results, they require too many parameters. We propose a new model to solve this problem. Our proposed model includes less parameters as well as outperforming the success of the state of the art models. In the proposed model, a partial decoder is used to reduce the number of parameters while maintaning success. EfficientNetB0, which gives successfull results as well as requiring few parameters, is used in the encoder part. Since polyps have variable aspect and aspect ratios, an asymetric convolution block was used instead of using classic convolution block. Kvasir and CVC-ClinicDB datasets were seperated as training, validation and testing, and CVC-ColonDB, ETIS and Endoscene datasets were used for testing. According to the dice metric, our model had the best results with %71.8 in the ColonDB test dataset, %89.3 in the EndoScene test dataset and %74.8 in the ETIS test dataset. Our model requires a total of 2.626.337 parameters. When we compare it in the literature, according to similar studies, the model that requires the least parameters is U-Net++ with 9.042.177 parameters.
MIcro-Surgical Anastomose Workflow recognition challenge report
Mar 24, 2021
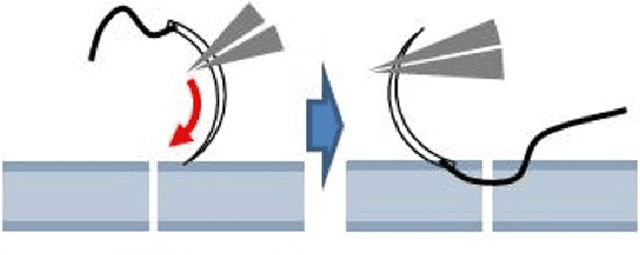
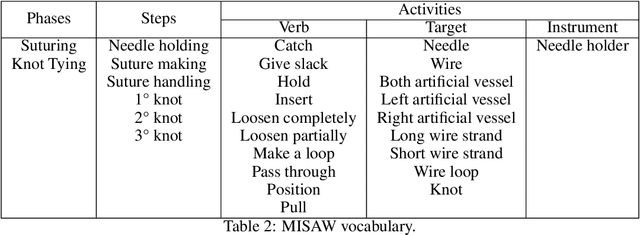
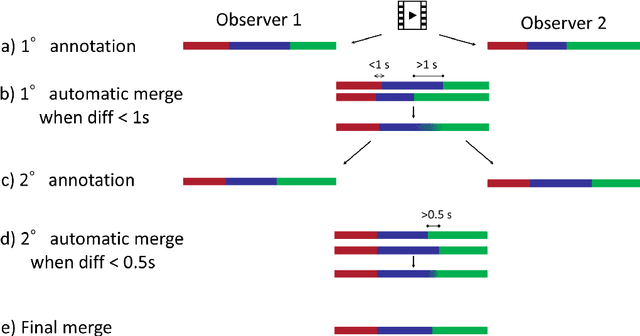
The "MIcro-Surgical Anastomose Workflow recognition on training sessions" (MISAW) challenge provided a data set of 27 sequences of micro-surgical anastomosis on artificial blood vessels. This data set was composed of videos, kinematics, and workflow annotations described at three different granularity levels: phase, step, and activity. The participants were given the option to use kinematic data and videos to develop workflow recognition models. Four tasks were proposed to the participants: three of them were related to the recognition of surgical workflow at three different granularity levels, while the last one addressed the recognition of all granularity levels in the same model. One ranking was made for each task. We used the average application-dependent balanced accuracy (AD-Accuracy) as the evaluation metric. This takes unbalanced classes into account and it is more clinically relevant than a frame-by-frame score. Six teams, including a non-competing team, participated in at least one task. All models employed deep learning models, such as CNN or RNN. The best models achieved more than 95% AD-Accuracy for phase recognition, 80% for step recognition, 60% for activity recognition, and 75% for all granularity levels. For high levels of granularity (i.e., phases and steps), the best models had a recognition rate that may be sufficient for applications such as prediction of remaining surgical time or resource management. However, for activities, the recognition rate was still low for applications that can be employed clinically. The MISAW data set is publicly available to encourage further research in surgical workflow recognition. It can be found at www.synapse.org/MISAW
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020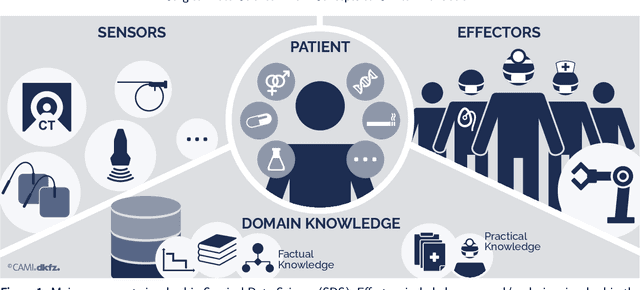
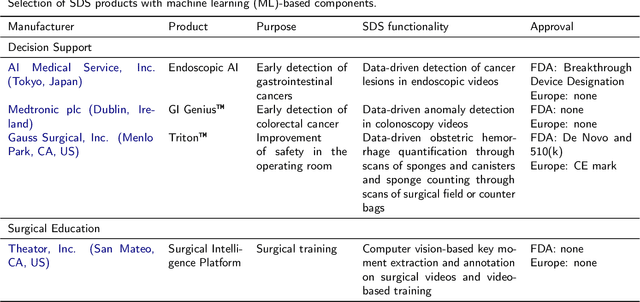
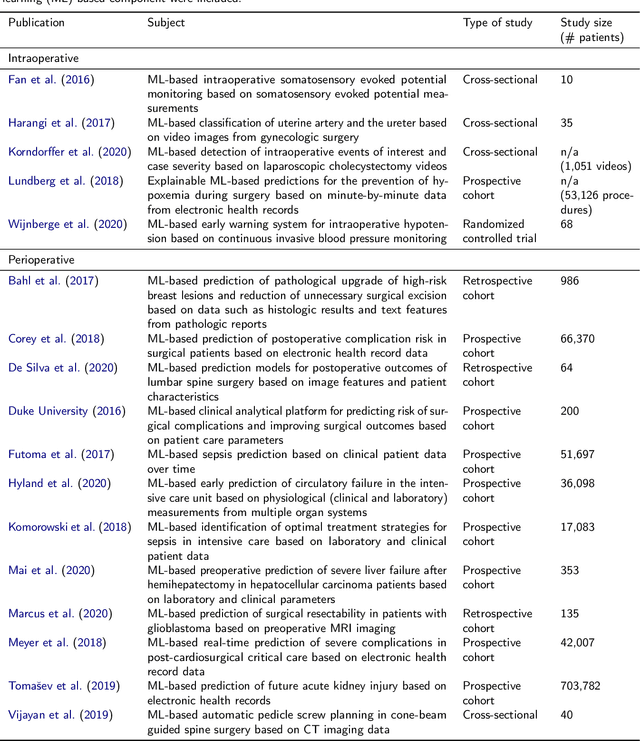
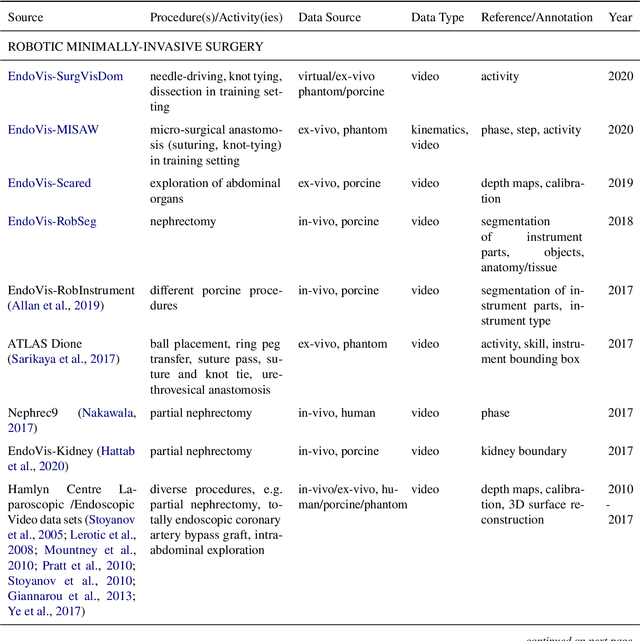
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.