 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
Instrument-Splatting++: Towards Controllable Surgical Instrument Digital Twin Using Gaussian Splatting
Mar 25, 2026High-quality and controllable digital twins of surgical instruments are critical for Real2Sim in robot-assisted surgery, as they enable realistic simulation, synthetic data generation, and perception learning under novel poses. We present Instrument-Splatting++, a monocular 3D Gaussian Splatting (3DGS) framework that reconstructs surgical instruments as a fully controllable Gaussian asset with high fidelity. Our pipeline starts with part-wise geometry pretraining that injects CAD priors into Gaussian primitives and equips the representation with part-aware semantic rendering. Built on the pretrained model, we propose a semantics-aware pose estimation and tracking (SAPET) method to recover per-frame 6-DoF pose and joint angles from unposed endoscopic videos, where a gripper-tip network trained purely from synthetic semantics provides robust supervision and a loose regularization suppresses singular articulations. Finally, we introduce Robust Texture Learning (RTL), which alternates pose refinement and robust appearance optimization, mitigating pose noise during texture learning. The proposed framework can perform pose estimation and learn realistic texture from unposed videos. We validate our method on sequences extracted from EndoVis17/18, SAR-RARP, and an in-house dataset, showing superior photometric quality and improved geometric accuracy over state-of-the-art baselines. We further demonstrate a downstream keypoint detection task where unseen-pose data augmentation from our controllable instrument Gaussian improves performance.
Towards Automated Initial Probe Placement in Transthoracic Teleultrasound Using Human Mesh and Skeleton Recovery
Mar 11, 2026Cardiac and lung ultrasound are technically demanding because operators must identify patient-specific intercostal acoustic windows and then navigate between standard views by adjusting probe position, rotation, and force across different imaging planes. These challenges are amplified in teleultrasound when a novice or robot faces the difficult task of first placing the probe on the patient without in-person expert assistance. We present a framework for automating Patient registration and anatomy-informed Initial Probe placement Guidance (PIPG) using only RGB images from a calibrated camera. The novice first captures the patient using the camera on a mixed reality (MR) head-mounted display (HMD). An edge server then infers a patient-specific body-surface and skeleton model, with spatial smoothing across multiple views. Using bony landmarks from the predicted skeleton, we estimate the intercostal region and project the guidance back onto the reconstructed body surface. To validate the framework, we overlaid the reconstructed body mesh and the virtual probe pose guidance across multiple transthoracic echocardiography scan planes in situ and measured the quantitative placement error. Pilot experiments with healthy volunteers suggest that the proposed probe placement prediction and MR guidance yield consistent initial placement within anatomical variability acceptable for teleultrasound setup
SurgCalib: Gaussian Splatting-Based Hand-Eye Calibration for Robot-Assisted Minimally Invasive Surgery
Mar 09, 2026We present a Gaussian Splatting-based framework for hand-eye calibration of the da Vinci surgical robot. In a vision-guided robotic system, accurate estimation of the rigid transformation between the robot base and the camera frame is essential for reliable closed-loop control. For cable-driven surgical robots, this task faces unique challenges. The encoders of surgical instruments often produce inaccurate proprioceptive measurements due to cable stretch and backlash. Conventional hand-eye calibration approaches typically rely on known fiducial patterns and solve the AX = XB formulation. While effective, introducing additional markers into the operating room (OR) environment can violate sterility protocols and disrupt surgical workflows. In this study, we propose SurgCalib, an automatic, markerless framework that has the potential to be used in the OR. SurgCalib first initializes the pose of the surgical instrument using raw kinematic measurements and subsequently refines this pose through a two-phase optimization procedure under the RCM constraint within a Gaussian Splatting-based differentiable rendering pipeline. We evaluate the proposed method on the public dVRK benchmark, SurgPose. The results demonstrate average 2D tool-tip reprojection errors of 12.24 px (2.06 mm) and 11.33 px (1.9 mm), and 3D tool-tip Euclidean distance errors of 5.98 mm and 4.75 mm, for the left and right instruments, respectively.
Measurement and Potential Field-Based Patient Modeling for Model-Mediated Tele-ultrasound
Sep 18, 2025



Teleoperated ultrasound can improve diagnostic medical imaging access for remote communities. Having accurate force feedback is important for enabling sonographers to apply the appropriate probe contact force to optimize ultrasound image quality. However, large time delays in communication make direct force feedback impractical. Prior work investigated using point cloud-based model-mediated teleoperation and internal potential field models to estimate contact forces and torques. We expand on this by introducing a method to update the internal potential field model of the patient with measured positions and forces for more transparent model-mediated tele-ultrasound. We first generate a point cloud model of the patient's surface and transmit this to the sonographer in a compact data structure. This is converted to a static voxelized volume where each voxel contains a potential field value. These values determine the forces and torques, which are rendered based on overlap between the voxelized volume and a point shell model of the ultrasound transducer. We solve for the potential field using a convex quadratic that combines the spatial Laplace operator with measured forces. This was evaluated on volunteer patients ($n=3$) by computing the accuracy of rendered forces. Results showed the addition of measured forces to the model reduced the force magnitude error by an average of 7.23 N and force vector angle error by an average of 9.37$^{\circ}$ compared to using only Laplace's equation.
AutoCam: Hierarchical Path Planning for an Autonomous Auxiliary Camera in Surgical Robotics
May 15, 2025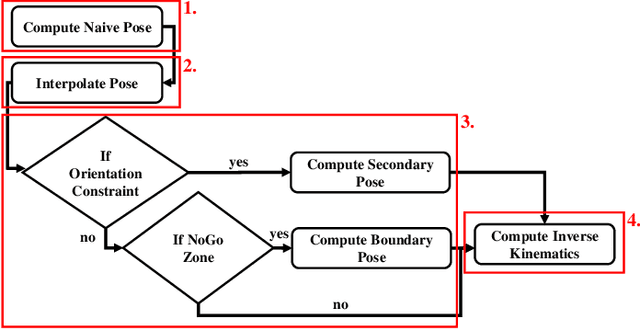

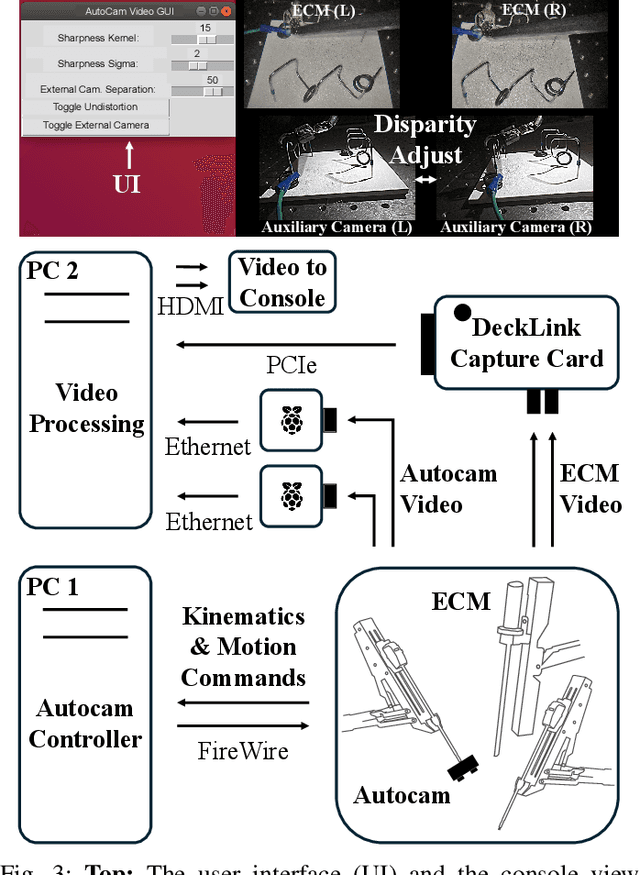
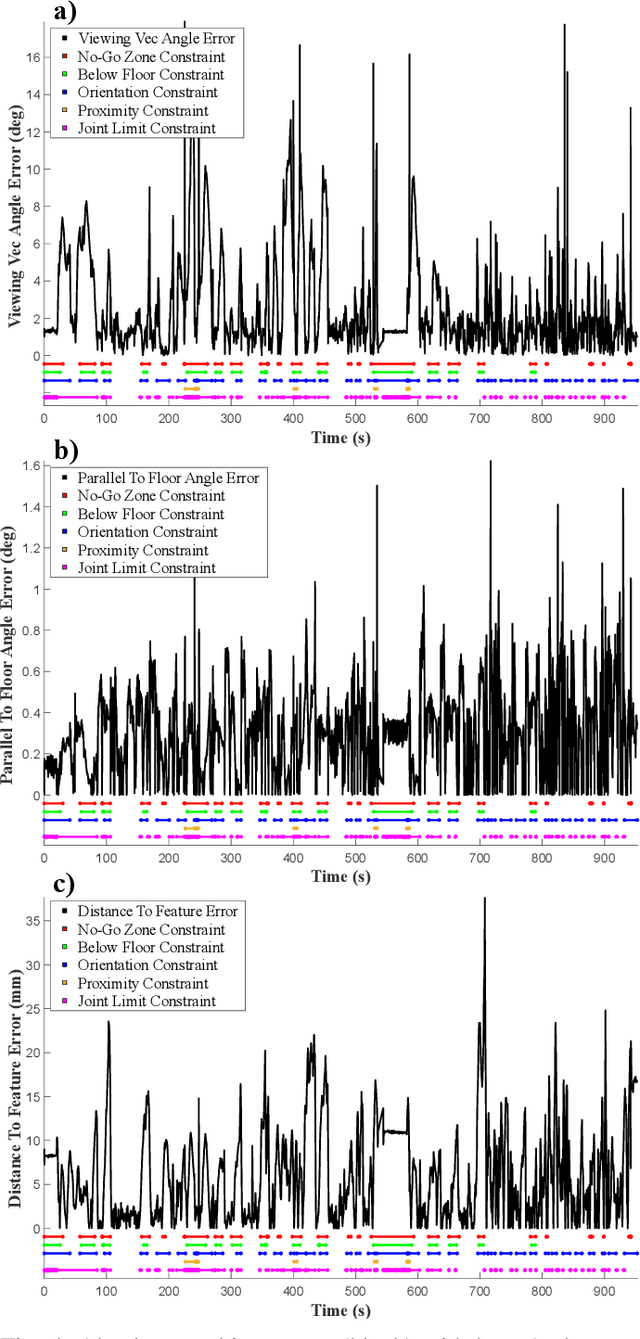
Incorporating an autonomous auxiliary camera into robot-assisted minimally invasive surgery (RAMIS) enhances spatial awareness and eliminates manual viewpoint control. Existing path planning methods for auxiliary cameras track two-dimensional surgical features but do not simultaneously account for camera orientation, workspace constraints, and robot joint limits. This study presents AutoCam: an automatic auxiliary camera placement method to improve visualization in RAMIS. Implemented on the da Vinci Research Kit, the system uses a priority-based, workspace-constrained control algorithm that combines heuristic geometric placement with nonlinear optimization to ensure robust camera tracking. A user study (N=6) demonstrated that the system maintained 99.84% visibility of a salient feature and achieved a pose error of 4.36 $\pm$ 2.11 degrees and 1.95 $\pm$ 5.66 mm. The controller was computationally efficient, with a loop time of 6.8 $\pm$ 12.8 ms. An additional pilot study (N=6), where novices completed a Fundamentals of Laparoscopic Surgery training task, suggests that users can teleoperate just as effectively from AutoCam's viewpoint as from the endoscope's while still benefiting from AutoCam's improved visual coverage of the scene. These results indicate that an auxiliary camera can be autonomously controlled using the da Vinci patient-side manipulators to track a salient feature, laying the groundwork for new multi-camera visualization methods in RAMIS.
Setup-Invariant Augmented Reality for Teaching by Demonstration with Surgical Robots
Apr 09, 2025Augmented reality (AR) is an effective tool in robotic surgery education as it combines exploratory learning with three-dimensional guidance. However, existing AR systems require expert supervision and do not account for differences in the mentor and mentee robot configurations. To enable novices to train outside the operating room while receiving expert-informed guidance, we present dV-STEAR: an open-source system that plays back task-aligned expert demonstrations without assuming identical setup joint positions between expert and novice. Pose estimation was rigorously quantified, showing a registration error of 3.86 (SD=2.01)mm. In a user study (N=24), dV-STEAR significantly improved novice performance on tasks from the Fundamentals of Laparoscopic Surgery. In a single-handed ring-over-wire task, dV-STEAR increased completion speed (p=0.03) and reduced collision time (p=0.01) compared to dry-lab training alone. During a pick-and-place task, it improved success rates (p=0.004). Across both tasks, participants using dV-STEAR exhibited significantly more balanced hand use and reported lower frustration levels. This work presents a novel educational tool implemented on the da Vinci Research Kit, demonstrates its effectiveness in teaching novices, and builds the foundation for further AR integration into robot-assisted surgery.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Instrument-Splatting: Controllable Photorealistic Reconstruction of Surgical Instruments Using Gaussian Splatting
Mar 06, 2025



Real2Sim is becoming increasingly important with the rapid development of surgical artificial intelligence (AI) and autonomy. In this work, we propose a novel Real2Sim methodology, \textit{Instrument-Splatting}, that leverages 3D Gaussian Splatting to provide fully controllable 3D reconstruction of surgical instruments from monocular surgical videos. To maintain both high visual fidelity and manipulability, we introduce a geometry pre-training to bind Gaussian point clouds on part mesh with accurate geometric priors and define a forward kinematics to control the Gaussians as flexible as real instruments. Afterward, to handle unposed videos, we design a novel instrument pose tracking method leveraging semantics-embedded Gaussians to robustly refine per-frame instrument poses and joint states in a render-and-compare manner, which allows our instrument Gaussian to accurately learn textures and reach photorealistic rendering. We validated our method on 2 publicly released surgical videos and 4 videos collected on ex vivo tissues and green screens. Quantitative and qualitative evaluations demonstrate the effectiveness and superiority of the proposed method.
Semantic-ICP: Iterative Closest Point for Non-rigid Multi-Organ Point Cloud Registration
Mar 02, 2025



Point cloud registration is important in computer-aided interventions (CAI). While learning-based point cloud registration methods have been developed, their clinical application is hampered by issues of generalizability and explainability. Therefore, classical point cloud registration methods, such as Iterative Closest Point (ICP), are still widely applied in CAI. ICP methods fail to consider that: (1) the points have well-defined semantic meaning, in that each point can be related to a specific anatomical label; (2) the deformation needs to follow biomechanical energy constraints. In this paper, we present a novel semantic ICP (sem-ICP) method that handles multiple point labels and uses linear elastic energy regularization. We use semantic labels to improve the robustness of the closest point matching and propose a new point cloud deformation representation to apply explicit biomechanical energy regularization. Our experiments on the Learn2reg abdominal MR-CT registration dataset and a trans-oral robotic surgery ultrasound-CT registration dataset show that our method improves the Hausdorff distance compared with other state-of-the-art ICP-based registration methods. We also perform a sensitivity study to show that our rigid initialization achieves better convergence with different initializations and visible ratios.