 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Estimation for LLM-Based Dialogue State Tracking
Sep 15, 2024



Estimation of a model's confidence on its outputs is critical for Conversational AI systems based on large language models (LLMs), especially for reducing hallucination and preventing over-reliance. In this work, we provide an exhaustive exploration of methods, including approaches proposed for open- and closed-weight LLMs, aimed at quantifying and leveraging model uncertainty to improve the reliability of LLM-generated responses, specifically focusing on dialogue state tracking (DST) in task-oriented dialogue systems (TODS). Regardless of the model type, well-calibrated confidence scores are essential to handle uncertainties, thereby improving model performance. We evaluate four methods for estimating confidence scores based on softmax, raw token scores, verbalized confidences, and a combination of these methods, using the area under the curve (AUC) metric to assess calibration, with higher AUC indicating better calibration. We also enhance these with a self-probing mechanism, proposed for closed models. Furthermore, we assess these methods using an open-weight model fine-tuned for the task of DST, achieving superior joint goal accuracy (JGA). Our findings also suggest that fine-tuning open-weight LLMs can result in enhanced AUC performance, indicating better confidence score calibration.
Dialog Flow Induction for Constrainable LLM-Based Chatbots
Aug 03, 2024



LLM-driven dialog systems are used in a diverse set of applications, ranging from healthcare to customer service. However, given their generalization capability, it is difficult to ensure that these chatbots stay within the boundaries of the specialized domains, potentially resulting in inaccurate information and irrelevant responses. This paper introduces an unsupervised approach for automatically inducing domain-specific dialog flows that can be used to constrain LLM-based chatbots. We introduce two variants of dialog flow based on the availability of in-domain conversation instances. Through human and automatic evaluation over various dialog domains, we demonstrate that our high-quality data-guided dialog flows achieve better domain coverage, thereby overcoming the need for extensive manual crafting of such flows.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


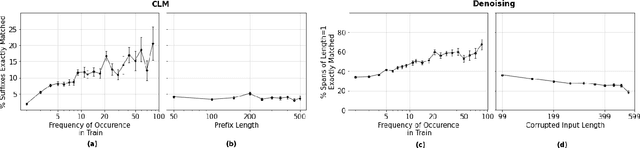
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022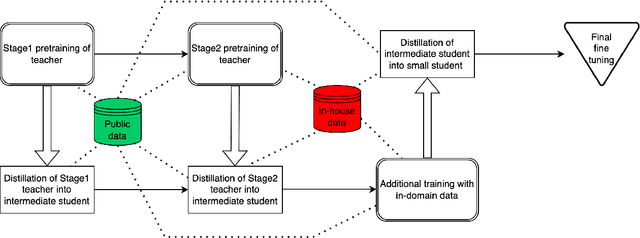
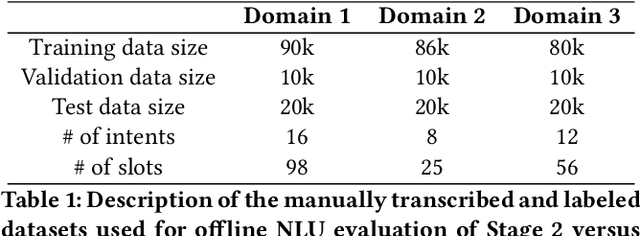
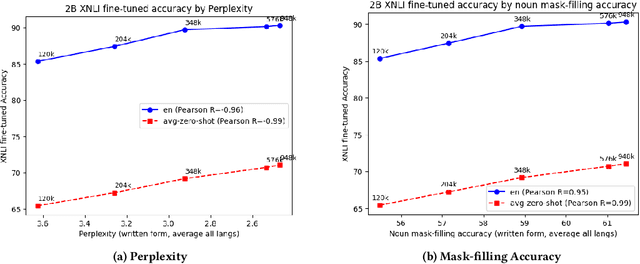
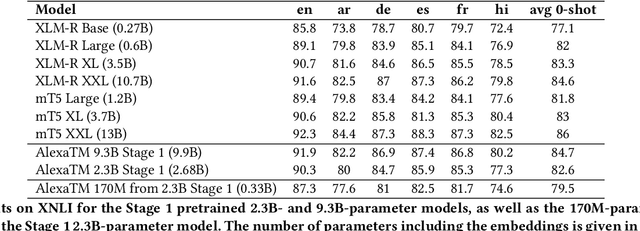
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
MASSIVE: A 1M-Example Multilingual Natural Language Understanding Dataset with 51 Typologically-Diverse Languages
Apr 18, 2022
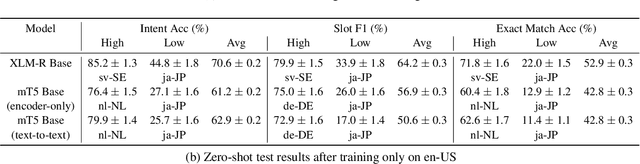

We present the MASSIVE dataset--Multilingual Amazon Slu resource package (SLURP) for Slot-filling, Intent classification, and Virtual assistant Evaluation. MASSIVE contains 1M realistic, parallel, labeled virtual assistant utterances spanning 51 languages, 18 domains, 60 intents, and 55 slots. MASSIVE was created by tasking professional translators to localize the English-only SLURP dataset into 50 typologically diverse languages from 29 genera. We also present modeling results on XLM-R and mT5, including exact match accuracy, intent classification accuracy, and slot-filling F1 score. We have released our dataset, modeling code, and models publicly.
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021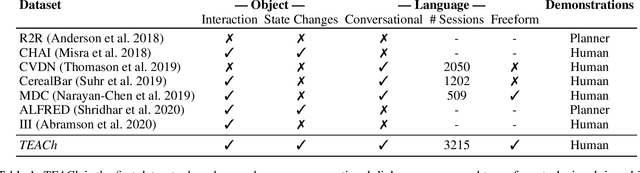
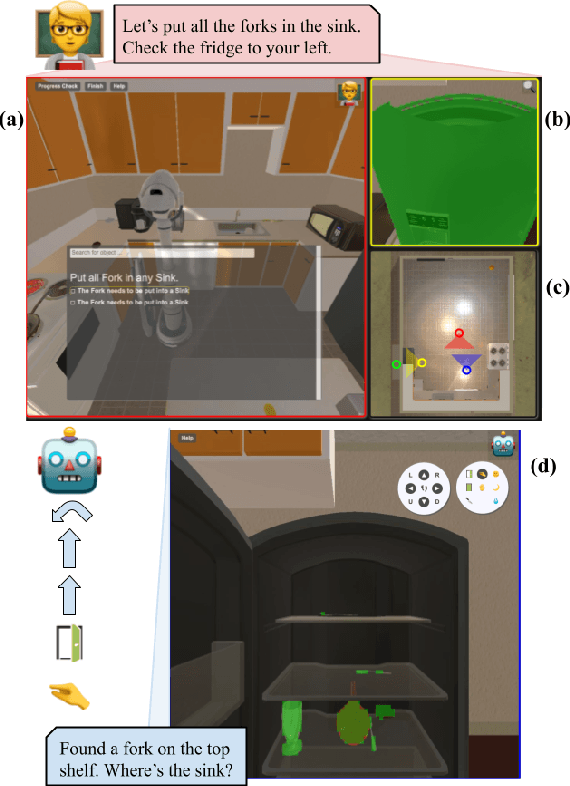
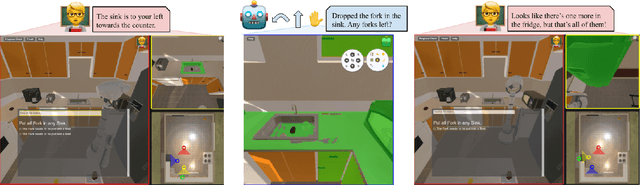
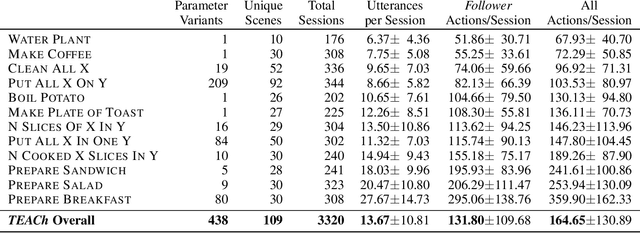
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
Generative Conversational Networks
Jun 15, 2021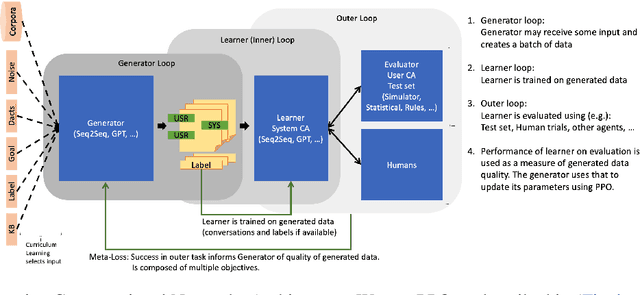
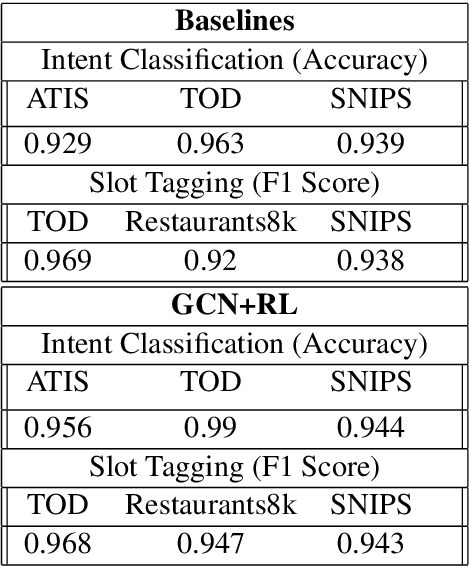
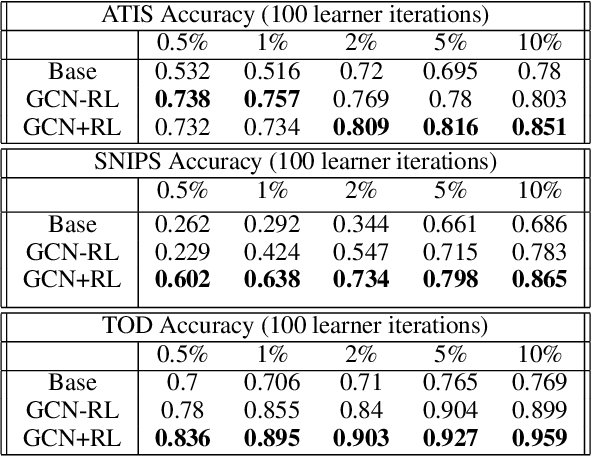
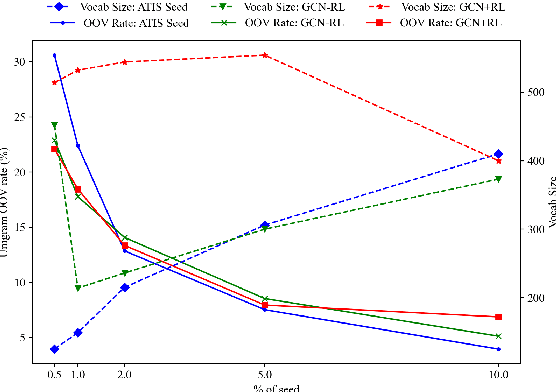
Inspired by recent work in meta-learning and generative teaching networks, we propose a framework called Generative Conversational Networks, in which conversational agents learn to generate their own labelled training data (given some seed data) and then train themselves from that data to perform a given task. We use reinforcement learning to optimize the data generation process where the reward signal is the agent's performance on the task. The task can be any language-related task, from intent detection to full task-oriented conversations. In this work, we show that our approach is able to generalise from seed data and performs well in limited data and limited computation settings, with significant gains for intent detection and slot tagging across multiple datasets: ATIS, TOD, SNIPS, and Restaurants8k. We show an average improvement of 35% in intent detection and 21% in slot tagging over a baseline model trained from the seed data. We also conduct an analysis of the novelty of the generated data and provide generated examples for intent detection, slot tagging, and non-goal oriented conversations.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation
May 24, 2021

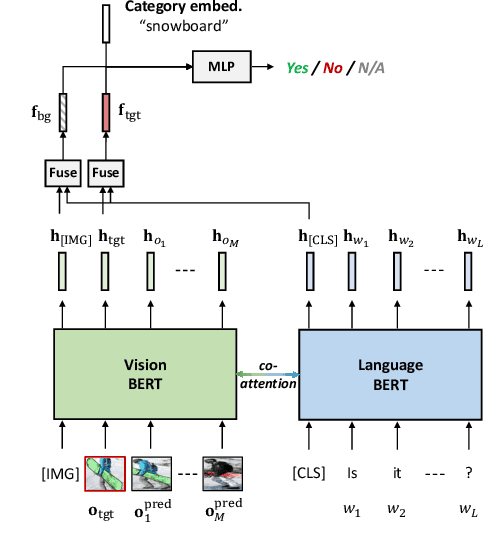
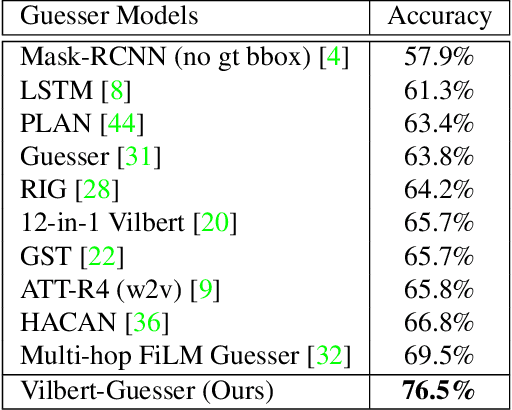
GuessWhat?! is a two-player visual dialog guessing game where player A asks a sequence of yes/no questions (Questioner) and makes a final guess (Guesser) about a target object in an image, based on answers from player B (Oracle). Based on this dialog history between the Questioner and the Oracle, a Guesser makes a final guess of the target object. Previous baseline Oracle model encodes no visual information in the model, and it cannot fully understand complex questions about color, shape, relationships and so on. Most existing work for Guesser encode the dialog history as a whole and train the Guesser models from scratch on the GuessWhat?! dataset. This is problematic since language encoder tend to forget long-term history and the GuessWhat?! data is sparse in terms of learning visual grounding of objects. Previous work for Questioner introduces state tracking mechanism into the model, but it is learned as a soft intermediates without any prior vision-linguistic insights. To bridge these gaps, in this paper we propose Vilbert-based Oracle, Guesser and Questioner, which are all built on top of pretrained vision-linguistic model, Vilbert. We introduce two-way background/target fusion mechanism into Vilbert-Oracle to account for both intra and inter-object questions. We propose a unified framework for Vilbert-Guesser and Vilbert-Questioner, where state-estimator is introduced to best utilize Vilbert's power on single-turn referring expression comprehension. Experimental results show that our proposed models outperform state-of-the-art models significantly by 7%, 10%, 12% for Oracle, Guesser and End-to-End Questioner respectively.
Correcting Automated and Manual Speech Transcription Errors using Warped Language Models
Mar 26, 2021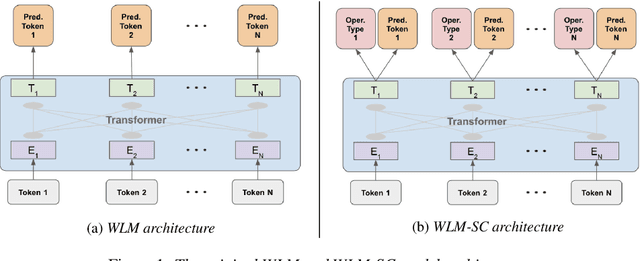
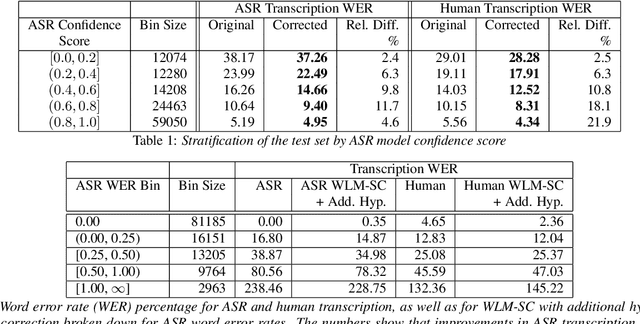
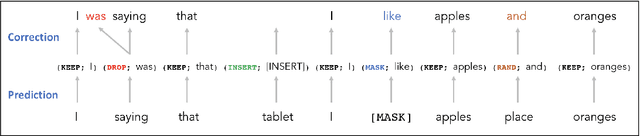
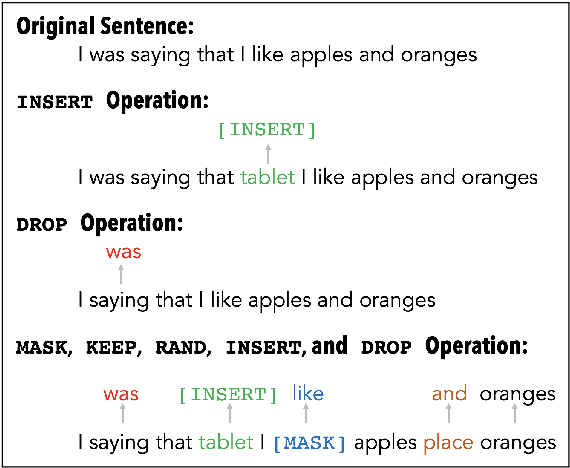
Masked language models have revolutionized natural language processing systems in the past few years. A recently introduced generalization of masked language models called warped language models are trained to be more robust to the types of errors that appear in automatic or manual transcriptions of spoken language by exposing the language model to the same types of errors during training. In this work we propose a novel approach that takes advantage of the robustness of warped language models to transcription noise for correcting transcriptions of spoken language. We show that our proposed approach is able to achieve up to 10% reduction in word error rates of both automatic and manual transcriptions of spoken language.
Are We There Yet? Learning to Localize in Embodied Instruction Following
Jan 09, 2021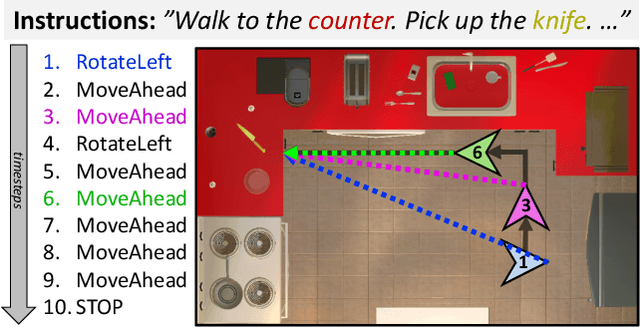
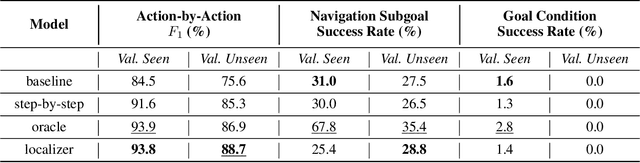
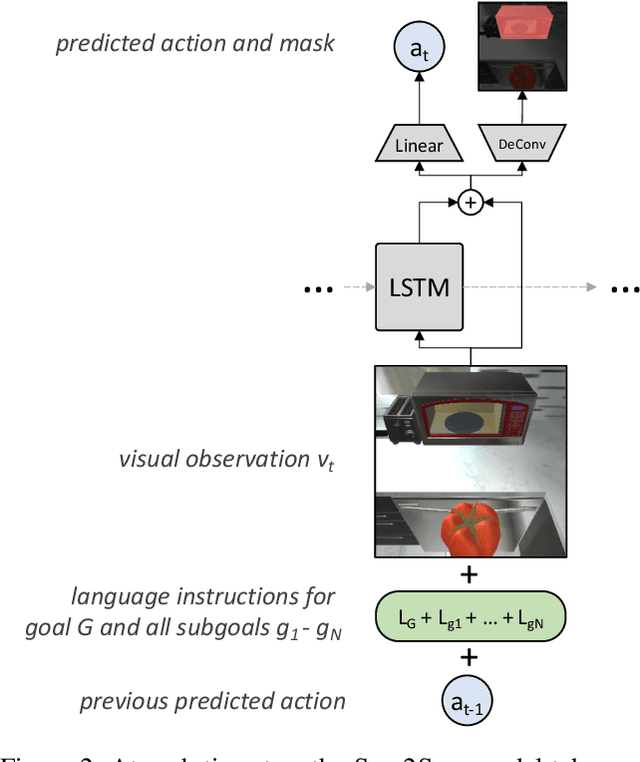
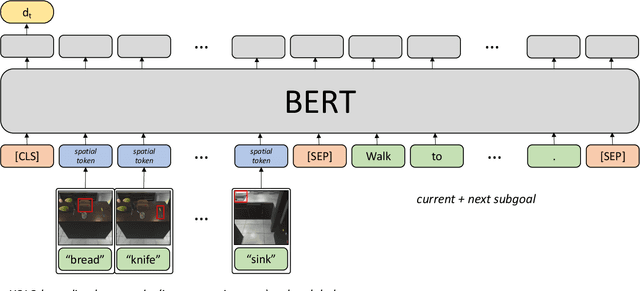
Embodied instruction following is a challenging problem requiring an agent to infer a sequence of primitive actions to achieve a goal environment state from complex language and visual inputs. Action Learning From Realistic Environments and Directives (ALFRED) is a recently proposed benchmark for this problem consisting of step-by-step natural language instructions to achieve subgoals which compose to an ultimate high-level goal. Key challenges for this task include localizing target locations and navigating to them through visual inputs, and grounding language instructions to visual appearance of objects. To address these challenges, in this study, we augment the agent's field of view during navigation subgoals with multiple viewing angles, and train the agent to predict its relative spatial relation to the target location at each timestep. We also improve language grounding by introducing a pre-trained object detection module to the model pipeline. Empirical studies show that our approach exceeds the baseline model performance.