 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Correction for Learning with Open-set Noisy Labels
Jun 01, 2021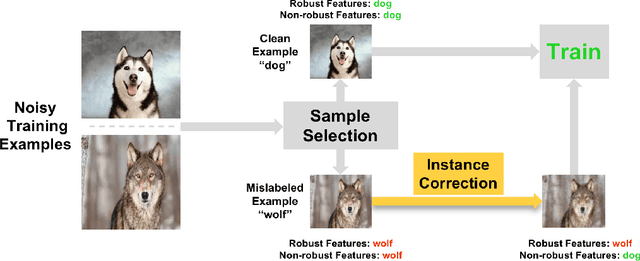
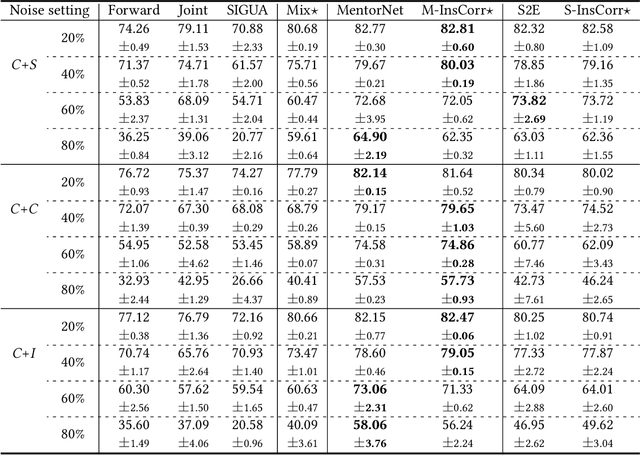

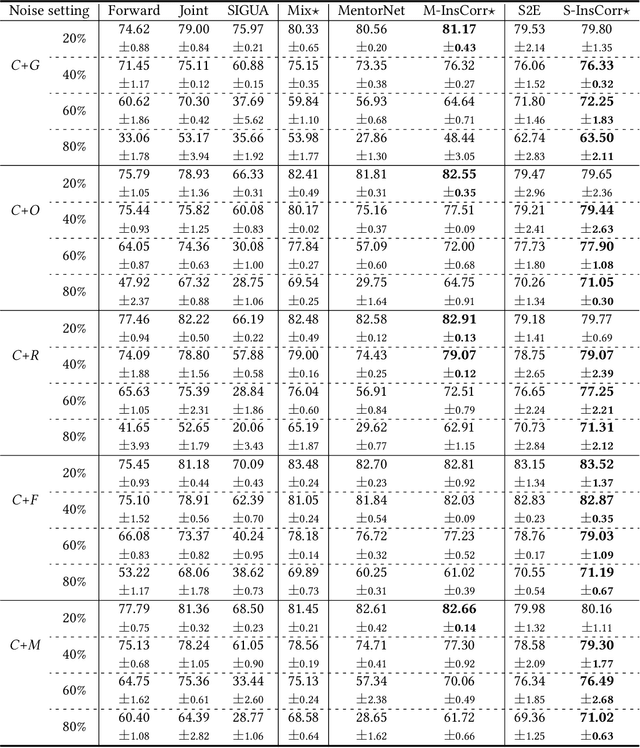
The problem of open-set noisy labels denotes that part of training data have a different label space that does not contain the true class. Lots of approaches, e.g., loss correction and label correction, cannot handle such open-set noisy labels well, since they need training data and test data to share the same label space, which does not hold for learning with open-set noisy labels. The state-of-the-art methods thus employ the sample selection approach to handle open-set noisy labels, which tries to select clean data from noisy data for network parameters updates. The discarded data are seen to be mislabeled and do not participate in training. Such an approach is intuitive and reasonable at first glance. However, a natural question could be raised "can such data only be discarded during training?". In this paper, we show that the answer is no. Specifically, we discuss that the instances of discarded data could consist of some meaningful information for generalization. For this reason, we do not abandon such data, but use instance correction to modify the instances of the discarded data, which makes the predictions for the discarded data consistent with given labels. Instance correction are performed by targeted adversarial attacks. The corrected data are then exploited for training to help generalization. In addition to the analytical results, a series of empirical evidences are provided to justify our claims.
Sample Selection with Uncertainty of Losses for Learning with Noisy Labels
Jun 01, 2021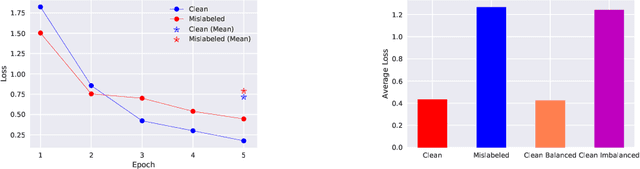
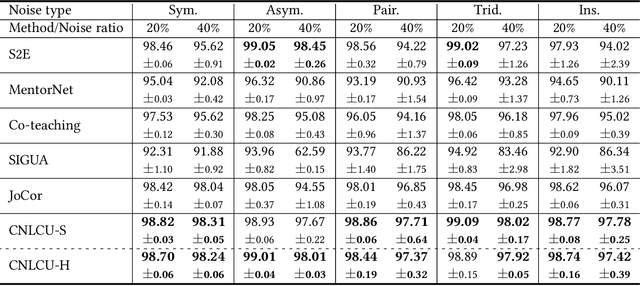
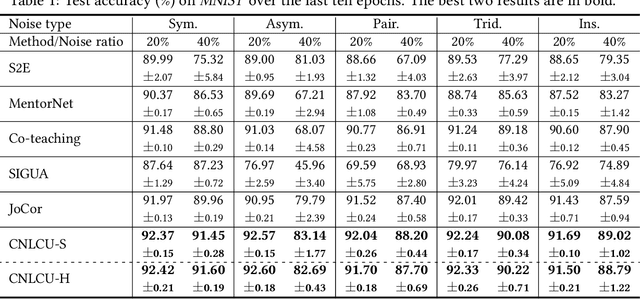
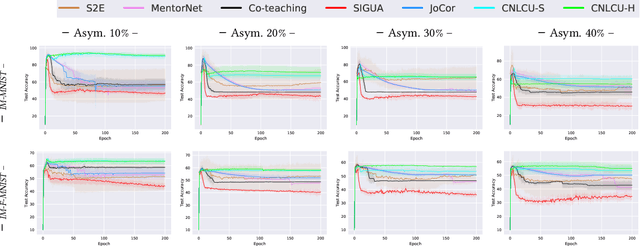
In learning with noisy labels, the sample selection approach is very popular, which regards small-loss data as correctly labeled during training. However, losses are generated on-the-fly based on the model being trained with noisy labels, and thus large-loss data are likely but not certainly to be incorrect. There are actually two possibilities of a large-loss data point: (a) it is mislabeled, and then its loss decreases slower than other data, since deep neural networks "learn patterns first"; (b) it belongs to an underrepresented group of data and has not been selected yet. In this paper, we incorporate the uncertainty of losses by adopting interval estimation instead of point estimation of losses, where lower bounds of the confidence intervals of losses derived from distribution-free concentration inequalities, but not losses themselves, are used for sample selection. In this way, we also give large-loss but less selected data a try; then, we can better distinguish between the cases (a) and (b) by seeing if the losses effectively decrease with the uncertainty after the try. As a result, we can better explore underrepresented data that are correctly labeled but seem to be mislabeled at first glance. Experiments demonstrate that the proposed method is superior to baselines and robust to a broad range of label noise types.
NoiLIn: Do Noisy Labels Always Hurt Adversarial Training?
May 31, 2021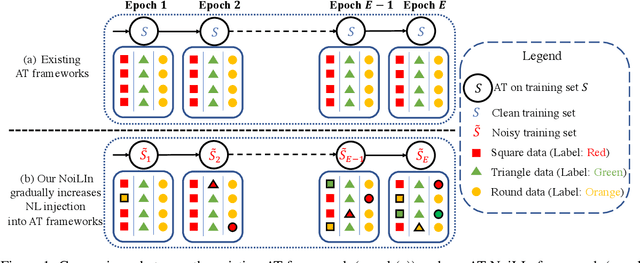

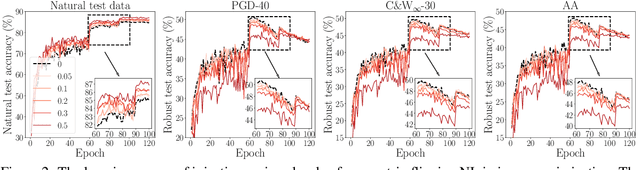

Adversarial training (AT) based on minimax optimization is a popular learning style that enhances the model's adversarial robustness. Noisy labels (NL) commonly undermine the learning and hurt the model's performance. Interestingly, both research directions hardly crossover and hit sparks. In this paper, we raise an intriguing question -- Does NL always hurt AT? Firstly, we find that NL injection in inner maximization for generating adversarial data augments natural data implicitly, which benefits AT's generalization. Secondly, we find NL injection in outer minimization for the learning serves as regularization that alleviates robust overfitting, which benefits AT's robustness. To enhance AT's adversarial robustness, we propose "NoiLIn" that gradually increases \underline{Noi}sy \underline{L}abels \underline{In}jection over the AT's training process. Empirically, NoiLIn answers the previous question negatively -- the adversarial robustness can be indeed enhanced by NL injection. Philosophically, we provide a new perspective of the learning with NL: NL should not always be deemed detrimental, and even in the absence of NL in the training set, we may consider injecting it deliberately.
Estimating Instance-dependent Label-noise Transition Matrix using DNNs
May 27, 2021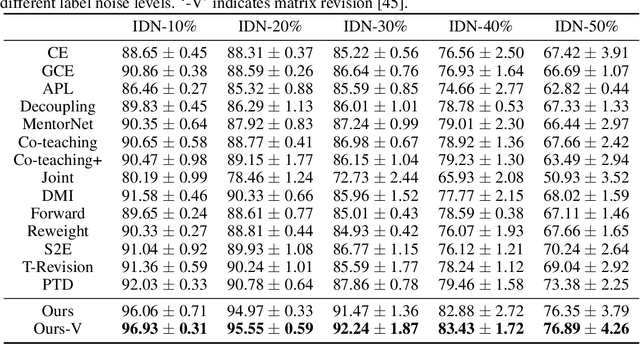
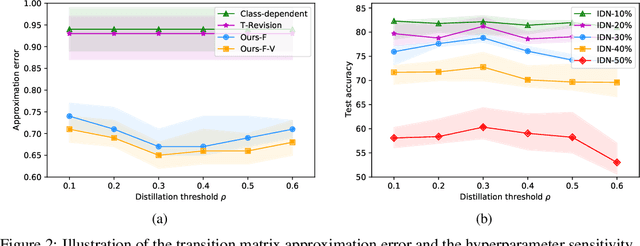
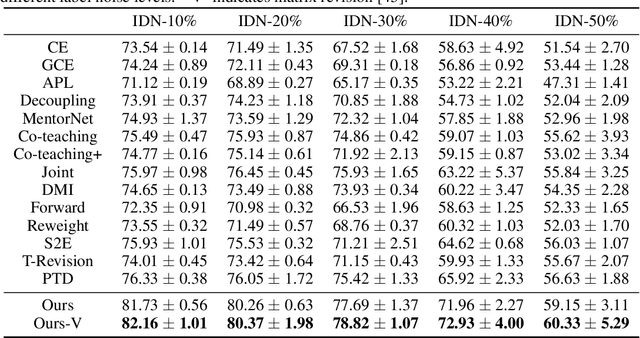
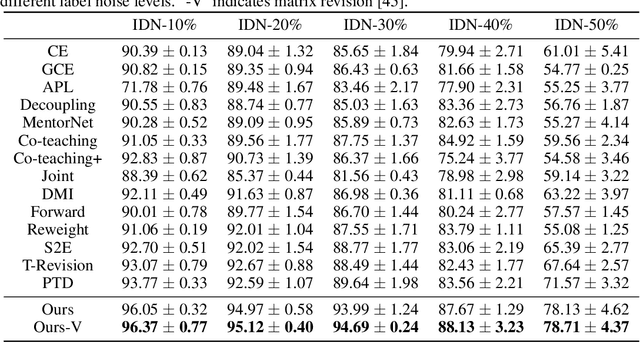
In label-noise learning, estimating the transition matrix is a hot topic as the matrix plays an important role in building statistically consistent classifiers. Traditionally, the transition from clean distribution to noisy distribution (i.e., clean label transition matrix) has been widely exploited to learn a clean label classifier by employing the noisy data. Motivated by that classifiers mostly output Bayes optimal labels for prediction, in this paper, we study to directly model the transition from Bayes optimal distribution to noisy distribution (i.e., Bayes label transition matrix) and learn a Bayes optimal label classifier. Note that given only noisy data, it is ill-posed to estimate either the clean label transition matrix or the Bayes label transition matrix. But favorably, Bayes optimal labels are less uncertain compared with the clean labels, i.e., the class posteriors of Bayes optimal labels are one-hot vectors while those of clean labels are not. This enables two advantages to estimate the Bayes label transition matrix, i.e., (a) we could theoretically recover a set of Bayes optimal labels under mild conditions; (b) the feasible solution space is much smaller. By exploiting the advantages, we estimate the Bayes label transition matrix by employing a deep neural network in a parameterized way, leading to better generalization and superior classification performance.
Meta Discovery: Learning to Discover Novel Classes given Very Limited Data
Feb 18, 2021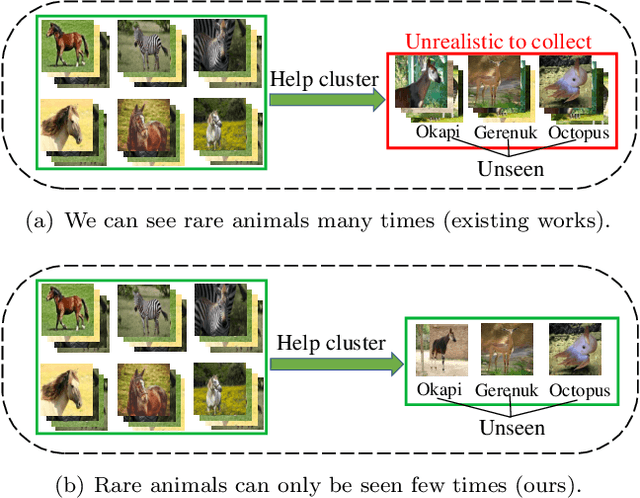

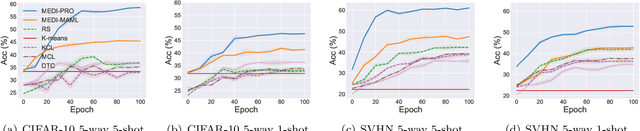
In learning to discover novel classes(L2DNC), we are given labeled data from seen classes and unlabeled data from unseen classes, and we need to train clustering models for the unseen classes. Since L2DNC is a new problem, its application scenario and implicit assumption are unclear. In this paper, we analyze and improve it by linking it to meta-learning: although there are no meta-training and meta-test phases, the underlying assumption is exactly the same, namely high-level semantic features are shared among the seen and unseen classes. Under this assumption, L2DNC is not only theoretically solvable, but also can be empirically solved by meta-learning algorithms slightly modified to fit our proposed framework. This L2DNC methodology significantly reduces the amount of unlabeled data needed for training and makes it more practical, as demonstrated in experiments. The use of very limited data is also justified by the application scenario of L2DNC: since it is unnatural to label only seen-class data, L2DNC is causally sampling instead of labeling. The unseen-class data should be collected on the way of collecting seen-class data, which is why they are novel and first need to be clustered.
Guided Interpolation for Adversarial Training
Feb 15, 2021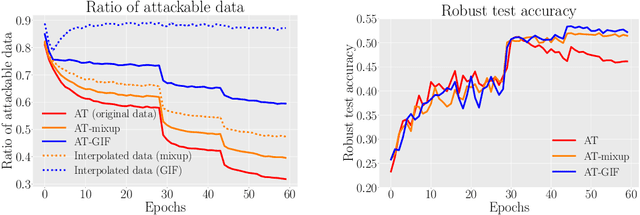

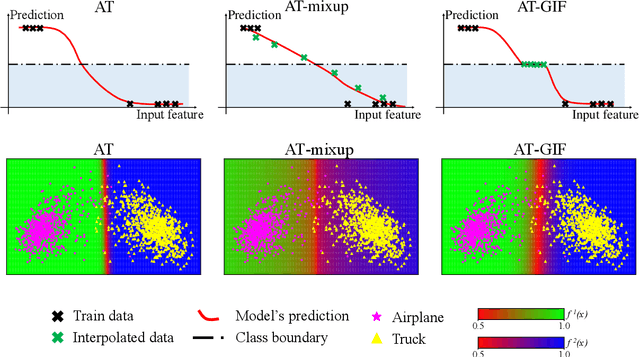

To enhance adversarial robustness, adversarial training learns deep neural networks on the adversarial variants generated by their natural data. However, as the training progresses, the training data becomes less and less attackable, undermining the robustness enhancement. A straightforward remedy is to incorporate more training data, but sometimes incurring an unaffordable cost. In this paper, to mitigate this issue, we propose the guided interpolation framework (GIF): in each epoch, the GIF employs the previous epoch's meta information to guide the data's interpolation. Compared with the vanilla mixup, the GIF can provide a higher ratio of attackable data, which is beneficial to the robustness enhancement; it meanwhile mitigates the model's linear behavior between classes, where the linear behavior is favorable to generalization but not to the robustness. As a result, the GIF encourages the model to predict invariantly in the cluster of each class. Experiments demonstrate that the GIF can indeed enhance adversarial robustness on various adversarial training methods and various datasets.
Learning from Similarity-Confidence Data
Feb 13, 2021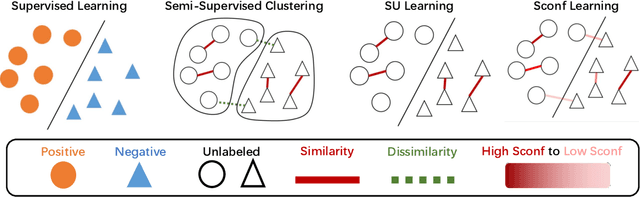

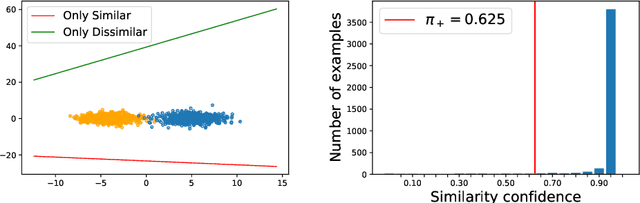
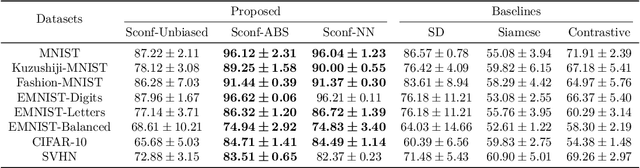
Weakly supervised learning has drawn considerable attention recently to reduce the expensive time and labor consumption of labeling massive data. In this paper, we investigate a novel weakly supervised learning problem of learning from similarity-confidence (Sconf) data, where we aim to learn an effective binary classifier from only unlabeled data pairs equipped with confidence that illustrates their degree of similarity (two examples are similar if they belong to the same class). To solve this problem, we propose an unbiased estimator of the classification risk that can be calculated from only Sconf data and show that the estimation error bound achieves the optimal convergence rate. To alleviate potential overfitting when flexible models are used, we further employ a risk correction scheme on the proposed risk estimator. Experimental results demonstrate the effectiveness of the proposed methods.
CIFS: Improving Adversarial Robustness of CNNs via Channel-wise Importance-based Feature Selection
Feb 10, 2021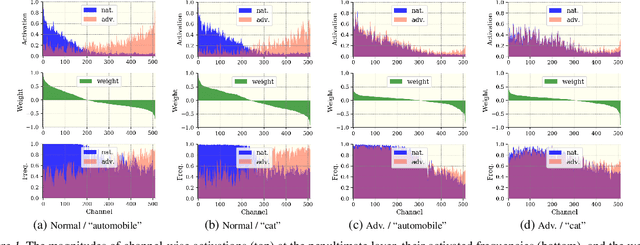
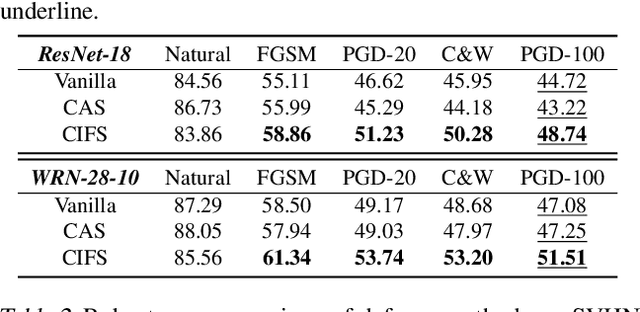
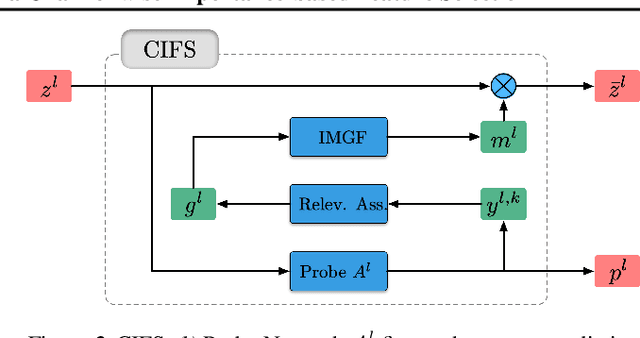
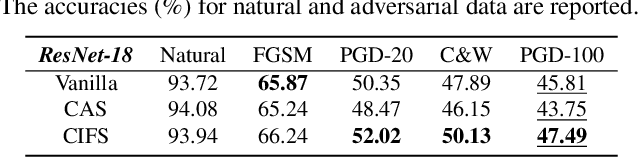
We investigate the adversarial robustness of CNNs from the perspective of channel-wise activations. By comparing \textit{non-robust} (normally trained) and \textit{robustified} (adversarially trained) models, we observe that adversarial training (AT) robustifies CNNs by aligning the channel-wise activations of adversarial data with those of their natural counterparts. However, the channels that are \textit{negatively-relevant} (NR) to predictions are still over-activated when processing adversarial data. Besides, we also observe that AT does not result in similar robustness for all classes. For the robust classes, channels with larger activation magnitudes are usually more \textit{positively-relevant} (PR) to predictions, but this alignment does not hold for the non-robust classes. Given these observations, we hypothesize that suppressing NR channels and aligning PR ones with their relevances further enhances the robustness of CNNs under AT. To examine this hypothesis, we introduce a novel mechanism, i.e., \underline{C}hannel-wise \underline{I}mportance-based \underline{F}eature \underline{S}election (CIFS). The CIFS manipulates channels' activations of certain layers by generating non-negative multipliers to these channels based on their relevances to predictions. Extensive experiments on benchmark datasets including CIFAR10 and SVHN clearly verify the hypothesis and CIFS's effectiveness of robustifying CNNs.
Understanding the Interaction of Adversarial Training with Noisy Labels
Feb 09, 2021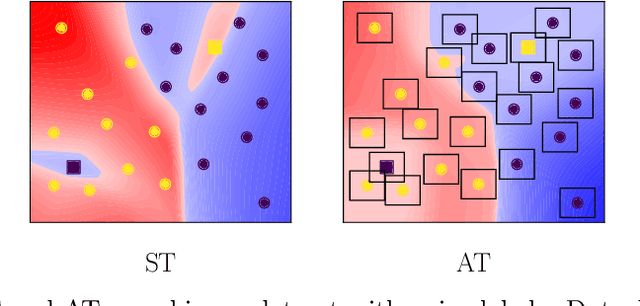
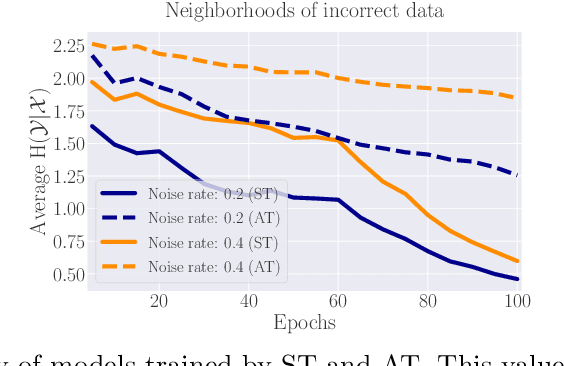
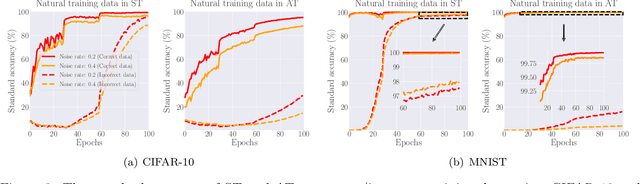
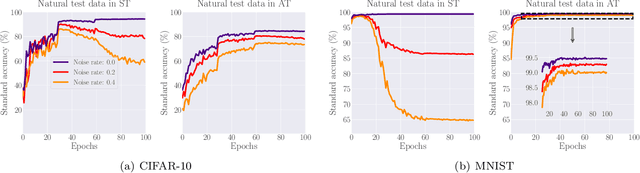
Noisy labels (NL) and adversarial examples both undermine trained models, but interestingly they have hitherto been studied independently. A recent adversarial training (AT) study showed that the number of projected gradient descent (PGD) steps to successfully attack a point (i.e., find an adversarial example in its proximity) is an effective measure of the robustness of this point. Given that natural data are clean, this measure reveals an intrinsic geometric property -- how far a point is from its class boundary. Based on this breakthrough, in this paper, we figure out how AT would interact with NL. Firstly, we find if a point is too close to its noisy-class boundary (e.g., one step is enough to attack it), this point is likely to be mislabeled, which suggests to adopt the number of PGD steps as a new criterion for sample selection for correcting NL. Secondly, we confirm AT with strong smoothing effects suffers less from NL (without NL corrections) than standard training (ST), which suggests AT itself is an NL correction. Hence, AT with NL is helpful for improving even the natural accuracy, which again illustrates the superiority of AT as a general-purpose robust learning criterion.
Learning Diverse-Structured Networks for Adversarial Robustness
Feb 08, 2021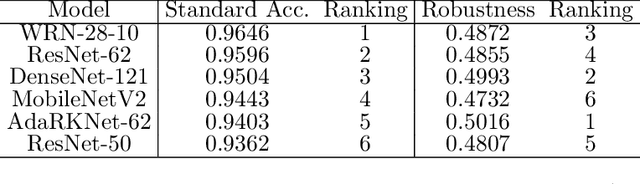
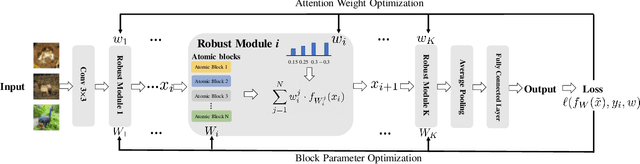
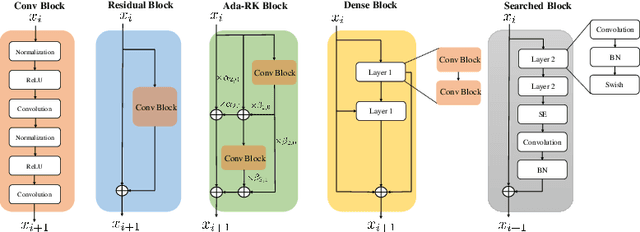
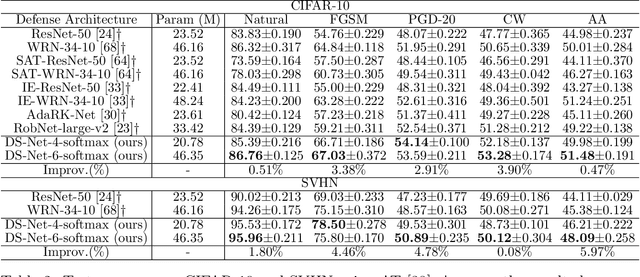
In adversarial training (AT), the main focus has been the objective and optimizer while the model has been less studied, so that the models being used are still those classic ones in standard training (ST). Classic network architectures (NAs) are generally worse than searched NAs in ST, which should be the same in AT. In this paper, we argue that NA and AT cannot be handled independently, since given a dataset, the optimal NA in ST would be no longer optimal in AT. That being said, AT is time-consuming itself; if we directly search NAs in AT over large search spaces, the computation will be practically infeasible. Thus, we propose a diverse-structured network (DS-Net), to significantly reduce the size of the search space: instead of low-level operations, we only consider predefined atomic blocks, where an atomic block is a time-tested building block like the residual block. There are only a few atomic blocks and thus we can weight all atomic blocks rather than find the best one in a searched block of DS-Net, which is an essential trade-off between exploring diverse structures and exploiting the best structures. Empirical results demonstrate the advantages of DS-Net, i.e., weighting the atomic blocks.