 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGCN:Sparse Graph Convolution Network for Pedestrian Trajectory Prediction
Apr 04, 2021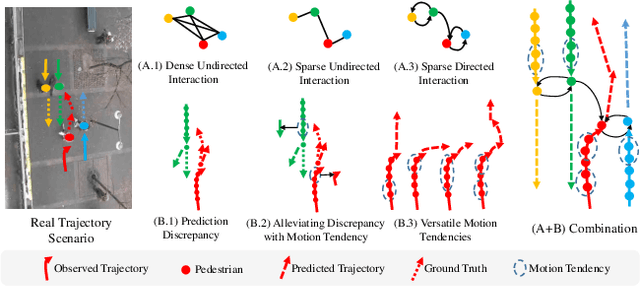
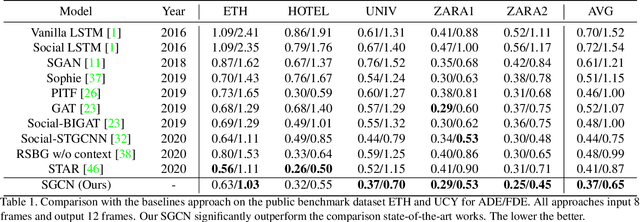
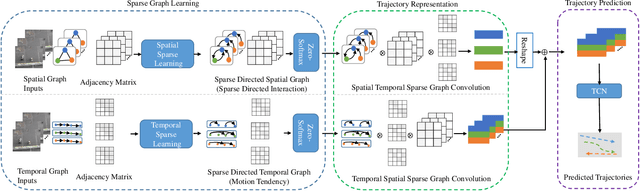
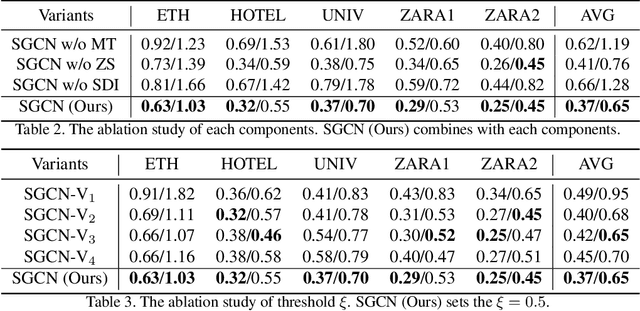
Pedestrian trajectory prediction is a key technology in autopilot, which remains to be very challenging due to complex interactions between pedestrians. However, previous works based on dense undirected interaction suffer from modeling superfluous interactions and neglect of trajectory motion tendency, and thus inevitably result in a considerable deviance from the reality. To cope with these issues, we present a Sparse Graph Convolution Network~(SGCN) for pedestrian trajectory prediction. Specifically, the SGCN explicitly models the sparse directed interaction with a sparse directed spatial graph to capture adaptive interaction pedestrians. Meanwhile, we use a sparse directed temporal graph to model the motion tendency, thus to facilitate the prediction based on the observed direction. Finally, parameters of a bi-Gaussian distribution for trajectory prediction are estimated by fusing the above two sparse graphs. We evaluate our proposed method on the ETH and UCY datasets, and the experimental results show our method outperforms comparative state-of-the-art methods by 9% in Average Displacement Error(ADE) and 13% in Final Displacement Error(FDE). Notably, visualizations indicate that our method can capture adaptive interactions between pedestrians and their effective motion tendencies.
Weakly Supervised Temporal Action Localization Through Learning Explicit Subspaces for Action and Context
Mar 30, 2021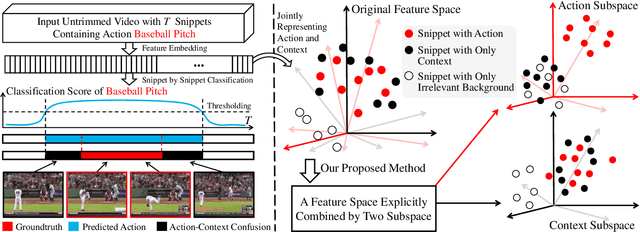

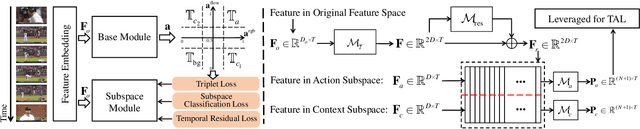
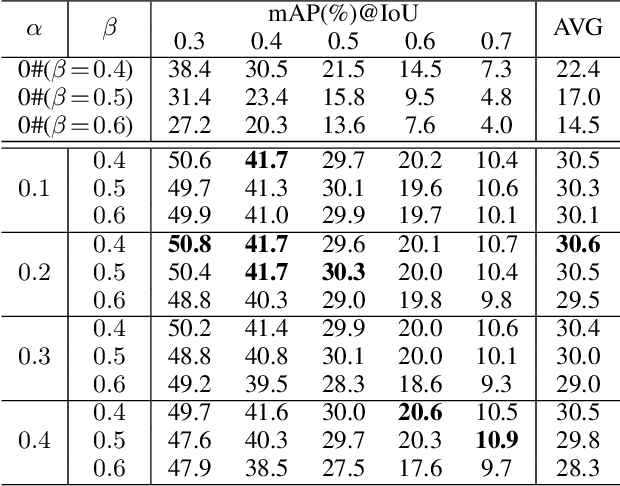
Weakly-supervised Temporal Action Localization (WS-TAL) methods learn to localize temporal starts and ends of action instances in a video under only video-level supervision. Existing WS-TAL methods rely on deep features learned for action recognition. However, due to the mismatch between classification and localization, these features cannot distinguish the frequently co-occurring contextual background, i.e., the context, and the actual action instances. We term this challenge action-context confusion, and it will adversely affect the action localization accuracy. To address this challenge, we introduce a framework that learns two feature subspaces respectively for actions and their context. By explicitly accounting for action visual elements, the action instances can be localized more precisely without the distraction from the context. To facilitate the learning of these two feature subspaces with only video-level categorical labels, we leverage the predictions from both spatial and temporal streams for snippets grouping. In addition, an unsupervised learning task is introduced to make the proposed module focus on mining temporal information. The proposed approach outperforms state-of-the-art WS-TAL methods on three benchmarks, i.e., THUMOS14, ActivityNet v1.2 and v1.3 datasets.
ACSNet: Action-Context Separation Network for Weakly Supervised Temporal Action Localization
Mar 28, 2021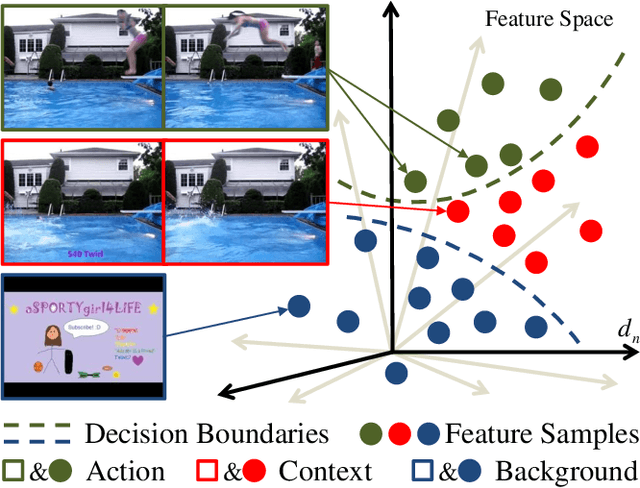
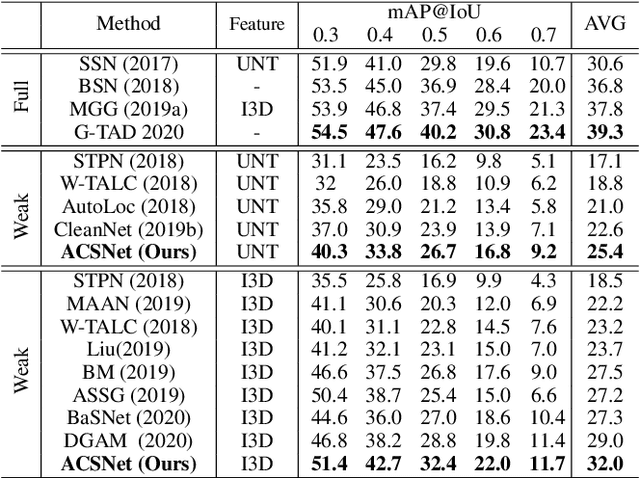
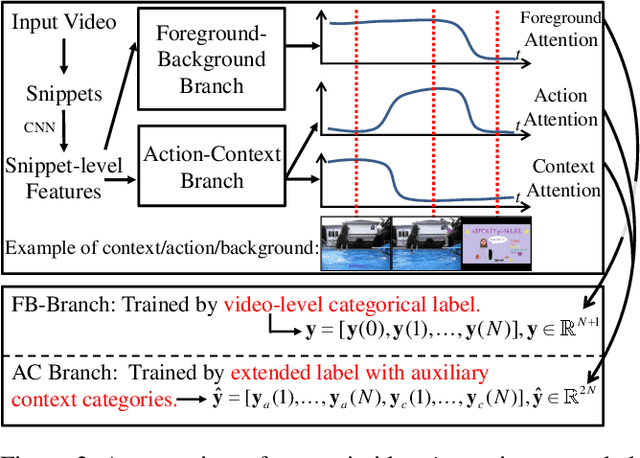
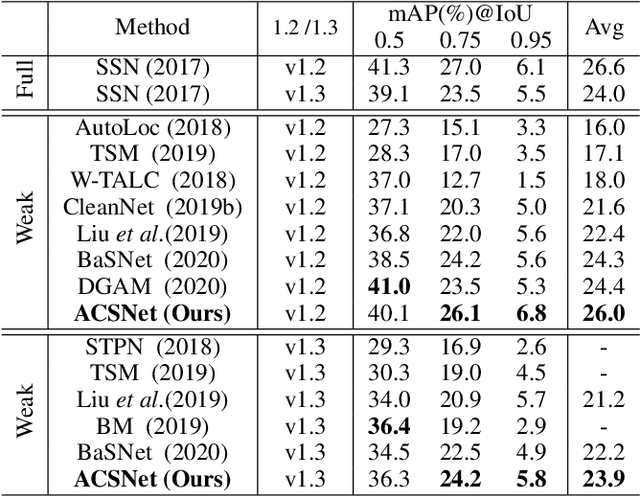
The object of Weakly-supervised Temporal Action Localization (WS-TAL) is to localize all action instances in an untrimmed video with only video-level supervision. Due to the lack of frame-level annotations during training, current WS-TAL methods rely on attention mechanisms to localize the foreground snippets or frames that contribute to the video-level classification task. This strategy frequently confuse context with the actual action, in the localization result. Separating action and context is a core problem for precise WS-TAL, but it is very challenging and has been largely ignored in the literature. In this paper, we introduce an Action-Context Separation Network (ACSNet) that explicitly takes into account context for accurate action localization. It consists of two branches (i.e., the Foreground-Background branch and the Action-Context branch). The Foreground- Background branch first distinguishes foreground from background within the entire video while the Action-Context branch further separates the foreground as action and context. We associate video snippets with two latent components (i.e., a positive component and a negative component), and their different combinations can effectively characterize foreground, action and context. Furthermore, we introduce extended labels with auxiliary context categories to facilitate the learning of action-context separation. Experiments on THUMOS14 and ActivityNet v1.2/v1.3 datasets demonstrate the ACSNet outperforms existing state-of-the-art WS-TAL methods by a large margin.
Beyond Visual Attractiveness: Physically Plausible Single Image HDR Reconstruction for Spherical Panoramas
Mar 24, 2021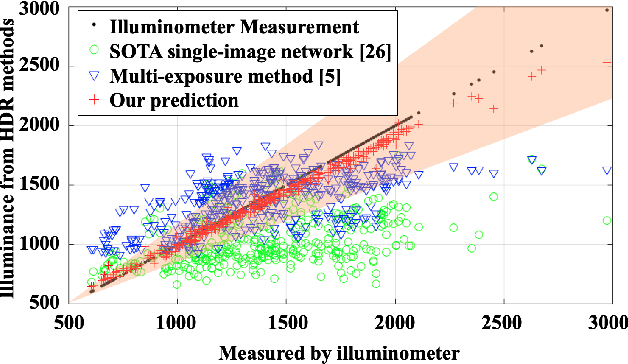
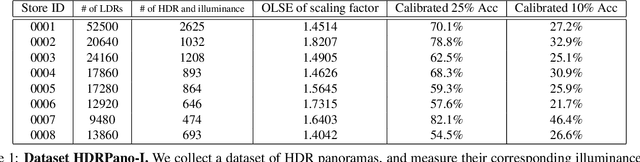
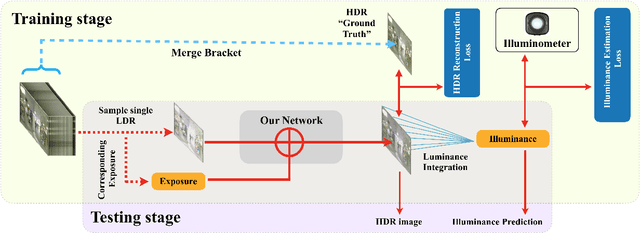
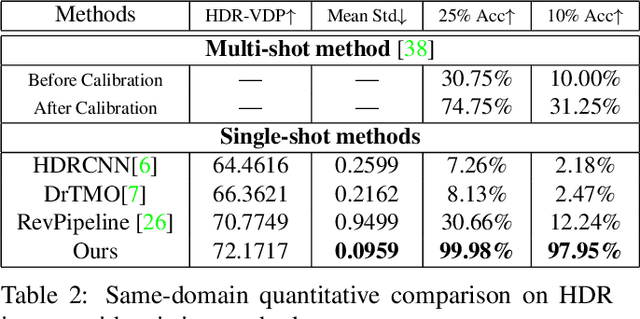
HDR reconstruction is an important task in computer vision with many industrial needs. The traditional approaches merge multiple exposure shots to generate HDRs that correspond to the physical quantity of illuminance of the scene. However, the tedious capturing process makes such multi-shot approaches inconvenient in practice. In contrast, recent single-shot methods predict a visually appealing HDR from a single LDR image through deep learning. But it is not clear whether the previously mentioned physical properties would still hold, without training the network to explicitly model them. In this paper, we introduce the physical illuminance constraints to our single-shot HDR reconstruction framework, with a focus on spherical panoramas. By the proposed physical regularization, our method can generate HDRs which are not only visually appealing but also physically plausible. For evaluation, we collect a large dataset of LDR and HDR images with ground truth illuminance measures. Extensive experiments show that our HDR images not only maintain high visual quality but also top all baseline methods in illuminance prediction accuracy.
Practical Relative Order Attack in Deep Ranking
Mar 20, 2021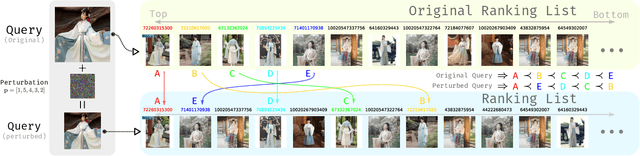

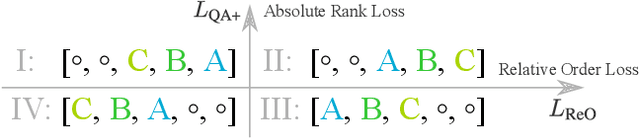
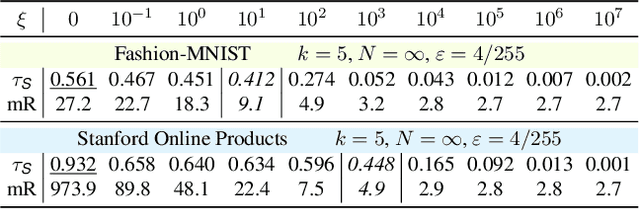
Recent studies unveil the vulnerabilities of deep ranking models, where an imperceptible perturbation can trigger dramatic changes in the ranking result. While previous attempts focus on manipulating absolute ranks of certain candidates, the possibility of adjusting their relative order remains under-explored. In this paper, we formulate a new adversarial attack against deep ranking systems, i.e., the Order Attack, which covertly alters the relative order among a selected set of candidates according to an attacker-specified permutation, with limited interference to other unrelated candidates. Specifically, it is formulated as a triplet-style loss imposing an inequality chain reflecting the specified permutation. However, direct optimization of such white-box objective is infeasible in a real-world attack scenario due to various black-box limitations. To cope with them, we propose a Short-range Ranking Correlation metric as a surrogate objective for black-box Order Attack to approximate the white-box method. The Order Attack is evaluated on the Fashion-MNIST and Stanford-Online-Products datasets under both white-box and black-box threat models. The black-box attack is also successfully implemented on a major e-commerce platform. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed methods, revealing a new type of ranking model vulnerability.
Diverse Semantic Image Synthesis via Probability Distribution Modeling
Mar 11, 2021
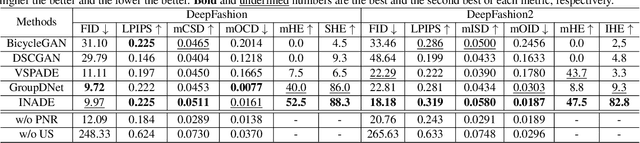
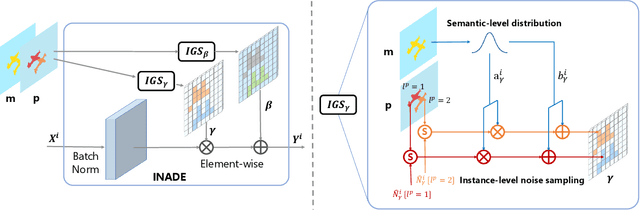
Semantic image synthesis, translating semantic layouts to photo-realistic images, is a one-to-many mapping problem. Though impressive progress has been recently made, diverse semantic synthesis that can efficiently produce semantic-level multimodal results, still remains a challenge. In this paper, we propose a novel diverse semantic image synthesis framework from the perspective of semantic class distributions, which naturally supports diverse generation at semantic or even instance level. We achieve this by modeling class-level conditional modulation parameters as continuous probability distributions instead of discrete values, and sampling per-instance modulation parameters through instance-adaptive stochastic sampling that is consistent across the network. Moreover, we propose prior noise remapping, through linear perturbation parameters encoded from paired references, to facilitate supervised training and exemplar-based instance style control at test time. Extensive experiments on multiple datasets show that our method can achieve superior diversity and comparable quality compared to state-of-the-art methods. Code will be available at \url{https://github.com/tzt101/INADE.git}
Deep Model Intellectual Property Protection via Deep Watermarking
Mar 08, 2021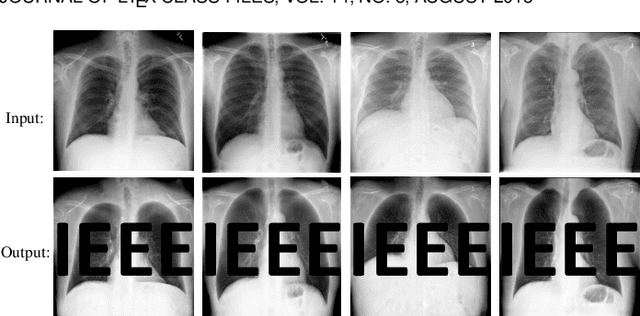
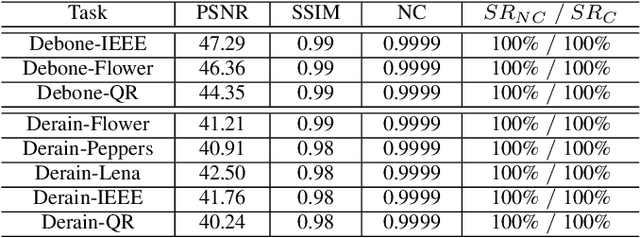
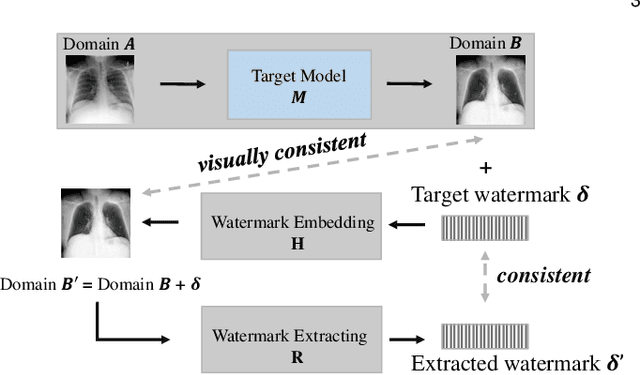

Despite the tremendous success, deep neural networks are exposed to serious IP infringement risks. Given a target deep model, if the attacker knows its full information, it can be easily stolen by fine-tuning. Even if only its output is accessible, a surrogate model can be trained through student-teacher learning by generating many input-output training pairs. Therefore, deep model IP protection is important and necessary. However, it is still seriously under-researched. In this work, we propose a new model watermarking framework for protecting deep networks trained for low-level computer vision or image processing tasks. Specifically, a special task-agnostic barrier is added after the target model, which embeds a unified and invisible watermark into its outputs. When the attacker trains one surrogate model by using the input-output pairs of the barrier target model, the hidden watermark will be learned and extracted afterwards. To enable watermarks from binary bits to high-resolution images, a deep invisible watermarking mechanism is designed. By jointly training the target model and watermark embedding, the extra barrier can even be absorbed into the target model. Through extensive experiments, we demonstrate the robustness of the proposed framework, which can resist attacks with different network structures and objective functions.
Semantic Image Synthesis via Efficient Class-Adaptive Normalization
Dec 08, 2020

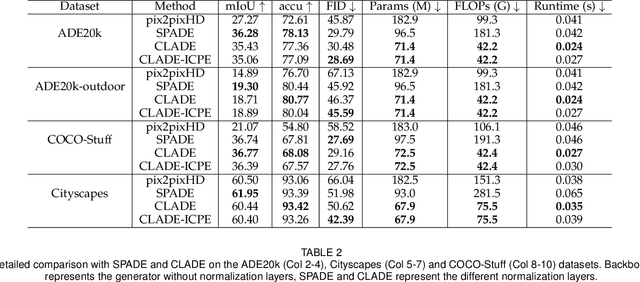
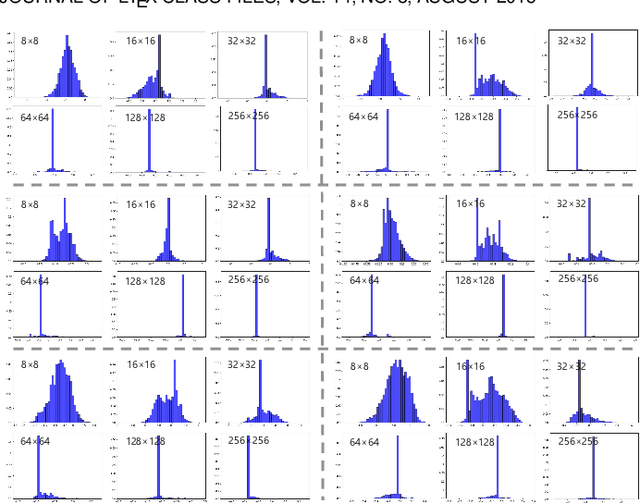
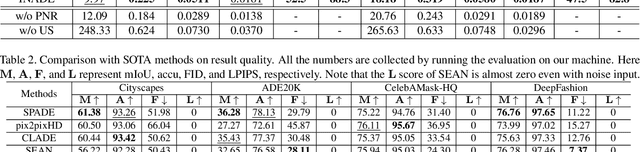
Spatially-adaptive normalization (SPADE) is remarkably successful recently in conditional semantic image synthesis, which modulates the normalized activation with spatially-varying transformations learned from semantic layouts, to prevent the semantic information from being washed away. Despite its impressive performance, a more thorough understanding of the advantages inside the box is still highly demanded to help reduce the significant computation and parameter overhead introduced by this novel structure. In this paper, from a return-on-investment point of view, we conduct an in-depth analysis of the effectiveness of this spatially-adaptive normalization and observe that its modulation parameters benefit more from semantic-awareness rather than spatial-adaptiveness, especially for high-resolution input masks. Inspired by this observation, we propose class-adaptive normalization (CLADE), a lightweight but equally-effective variant that is only adaptive to semantic class. In order to further improve spatial-adaptiveness, we introduce intra-class positional map encoding calculated from semantic layouts to modulate the normalization parameters of CLADE and propose a truly spatially-adaptive variant of CLADE, namely CLADE-ICPE. %Benefiting from this design, CLADE greatly reduces the computation cost while being able to preserve the semantic information in the generation. Through extensive experiments on multiple challenging datasets, we demonstrate that the proposed CLADE can be generalized to different SPADE-based methods while achieving comparable generation quality compared to SPADE, but it is much more efficient with fewer extra parameters and lower computational cost. The code is available at https://github.com/tzt101/CLADE.git
Passport-aware Normalization for Deep Model Protection
Nov 03, 2020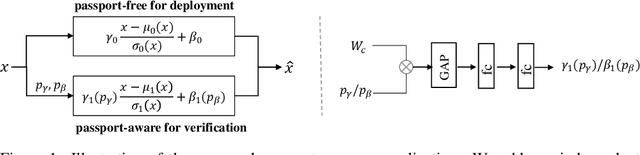

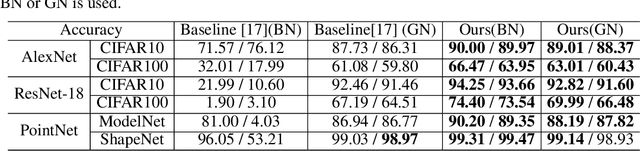
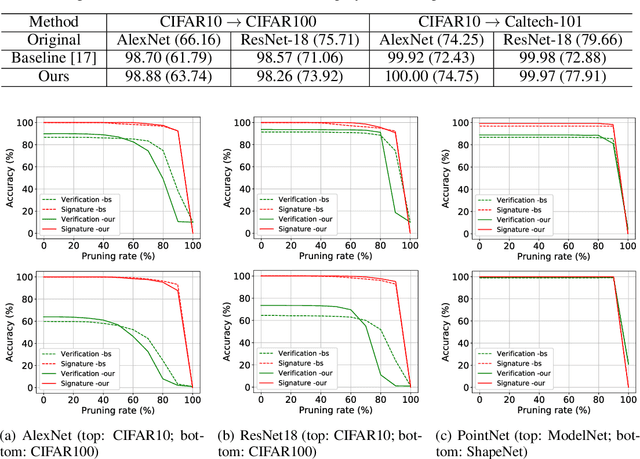
Despite tremendous success in many application scenarios, deep learning faces serious intellectual property (IP) infringement threats. Considering the cost of designing and training a good model, infringements will significantly infringe the interests of the original model owner. Recently, many impressive works have emerged for deep model IP protection. However, they either are vulnerable to ambiguity attacks, or require changes in the target network structure by replacing its original normalization layers and hence cause significant performance drops. To this end, we propose a new passport-aware normalization formulation, which is generally applicable to most existing normalization layers and only needs to add another passport-aware branch for IP protection. This new branch is jointly trained with the target model but discarded in the inference stage. Therefore it causes no structure change in the target model. Only when the model IP is suspected to be stolen by someone, the private passport-aware branch is added back for ownership verification. Through extensive experiments, we verify its effectiveness in both image and 3D point recognition models. It is demonstrated to be robust not only to common attack techniques like fine-tuning and model compression, but also to ambiguity attacks. By further combining it with trigger-set based methods, both black-box and white-box verification can be achieved for enhanced security of deep learning models deployed in real systems. Code can be found at https://github.com/ZJZAC/Passport-aware-Normalization.
LG-GAN: Label Guided Adversarial Network for Flexible Targeted Attack of Point Cloud-based Deep Networks
Nov 01, 2020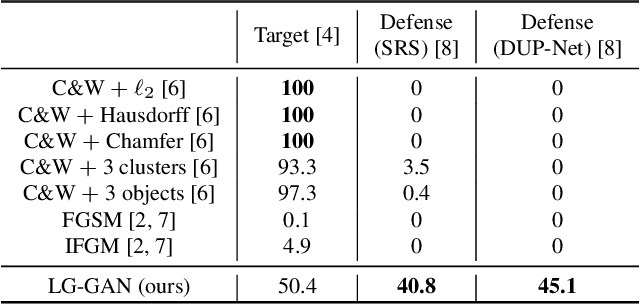
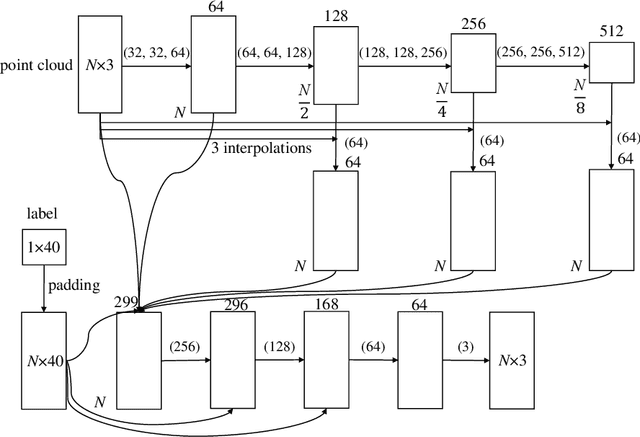
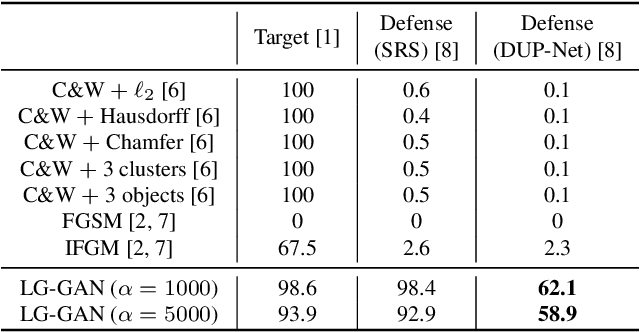

Deep neural networks have made tremendous progress in 3D point-cloud recognition. Recent works have shown that these 3D recognition networks are also vulnerable to adversarial samples produced from various attack methods, including optimization-based 3D Carlini-Wagner attack, gradient-based iterative fast gradient method, and skeleton-detach based point-dropping. However, after a careful analysis, these methods are either extremely slow because of the optimization/iterative scheme, or not flexible to support targeted attack of a specific category. To overcome these shortcomings, this paper proposes a novel label guided adversarial network (LG-GAN) for real-time flexible targeted point cloud attack. To the best of our knowledge, this is the first generation based 3D point cloud attack method. By feeding the original point clouds and target attack label into LG-GAN, it can learn how to deform the point clouds to mislead the recognition network into the specific label only with a single forward pass. In detail, LGGAN first leverages one multi-branch adversarial network to extract hierarchical features of the input point clouds, then incorporates the specified label information into multiple intermediate features using the label encoder. Finally, the encoded features will be fed into the coordinate reconstruction decoder to generate the target adversarial sample. By evaluating different point-cloud recognition models (e.g., PointNet, PointNet++ and DGCNN), we demonstrate that the proposed LG-GAN can support flexible targeted attack on the fly while guaranteeing good attack performance and higher efficiency simultaneously.