 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Tracking Translation: A Comprehensive Analysis of Visual SLAM in Human-Centered XR and IoT Ecosystems
Nov 11, 2024



Advancements in tracking algorithms have empowered nascent applications across various domains, from steering autonomous vehicles to guiding robots to enhancing augmented reality experiences for users. However, these algorithms are application-specific and do not work across applications with different types of motion; even a tracking algorithm designed for a given application does not work in scenarios deviating from highly standard conditions. For example, a tracking algorithm designed for robot navigation inside a building will not work for tracking the same robot in an outdoor environment. To demonstrate this problem, we evaluate the performance of the state-of-the-art tracking methods across various applications and scenarios. To inform our analysis, we first categorize algorithmic, environmental, and locomotion-related challenges faced by tracking algorithms. We quantitatively evaluate the performance using multiple tracking algorithms and representative datasets for a wide range of Internet of Things (IoT) and Extended Reality (XR) applications, including autonomous vehicles, drones, and humans. Our analysis shows that no tracking algorithm works across different applications and scenarios within applications. Ultimately, using the insights generated from our analysis, we discuss multiple approaches to improving the tracking performance using input data characterization, leveraging intermediate information, and output evaluation.
A Neurosymbolic Approach to Adaptive Feature Extraction in SLAM
Jul 09, 2024



Autonomous robots, autonomous vehicles, and humans wearing mixed-reality headsets require accurate and reliable tracking services for safety-critical applications in dynamically changing real-world environments. However, the existing tracking approaches, such as Simultaneous Localization and Mapping (SLAM), do not adapt well to environmental changes and boundary conditions despite extensive manual tuning. On the other hand, while deep learning-based approaches can better adapt to environmental changes, they typically demand substantial data for training and often lack flexibility in adapting to new domains. To solve this problem, we propose leveraging the neurosymbolic program synthesis approach to construct adaptable SLAM pipelines that integrate the domain knowledge from traditional SLAM approaches while leveraging data to learn complex relationships. While the approach can synthesize end-to-end SLAM pipelines, we focus on synthesizing the feature extraction module. We first devise a domain-specific language (DSL) that can encapsulate domain knowledge on the important attributes for feature extraction and the real-world performance of various feature extractors. Our neurosymbolic architecture then undertakes adaptive feature extraction, optimizing parameters via learning while employing symbolic reasoning to select the most suitable feature extractor. Our evaluations demonstrate that our approach, neurosymbolic Feature EXtraction (nFEX), yields higher-quality features. It also reduces the pose error observed for the state-of-the-art baseline feature extractors ORB and SIFT by up to 90% and up to 66%, respectively, thereby enhancing the system's efficiency and adaptability to novel environments.
Optimizing Fiducial Marker Placement for Improved Visual Localization
Nov 02, 2022Adding fiducial markers to a scene is a well-known strategy for making visual localization algorithms more robust. Traditionally, these marker locations are selected by humans who are familiar with visual localization techniques. This paper explores the problem of automatic marker placement within a scene. Specifically, given a predetermined set of markers and a scene model, we compute optimized marker positions within the scene that can improve accuracy in visual localization. Our main contribution is a novel framework for modeling camera localizability that incorporates both natural scene features and artificial fiducial markers added to the scene. We present optimized marker placement (OMP), a greedy algorithm that is based on the camera localizability framework. We have also designed a simulation framework for testing marker placement algorithms on 3D models and images generated from synthetic scenes. We have evaluated OMP within this testbed and demonstrate an improvement in the localization rate by up to 20 percent on three different scenes.
PatchMatch-RL: Deep MVS with Pixelwise Depth, Normal, and Visibility
Aug 19, 2021
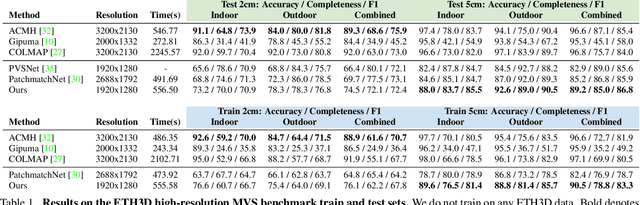
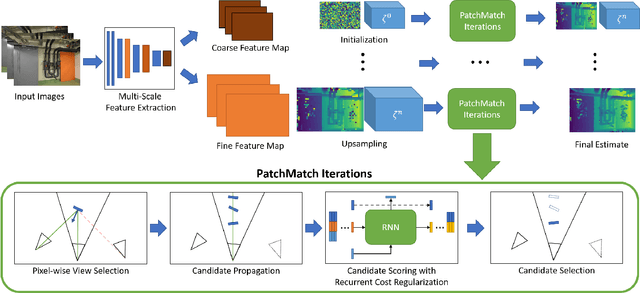
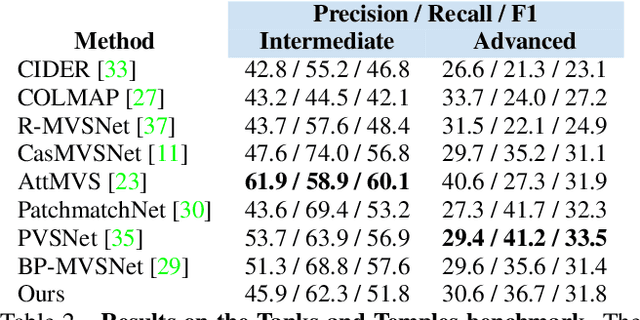
Recent learning-based multi-view stereo (MVS) methods show excellent performance with dense cameras and small depth ranges. However, non-learning based approaches still outperform for scenes with large depth ranges and sparser wide-baseline views, in part due to their PatchMatch optimization over pixelwise estimates of depth, normals, and visibility. In this paper, we propose an end-to-end trainable PatchMatch-based MVS approach that combines advantages of trainable costs and regularizations with pixelwise estimates. To overcome the challenge of the non-differentiable PatchMatch optimization that involves iterative sampling and hard decisions, we use reinforcement learning to minimize expected photometric cost and maximize likelihood of ground truth depth and normals. We incorporate normal estimation by using dilated patch kernels, and propose a recurrent cost regularization that applies beyond frontal plane-sweep algorithms to our pixelwise depth/normal estimates. We evaluate our method on widely used MVS benchmarks, ETH3D and Tanks and Temples (TnT), and compare to other state of the art learning based MVS models. On ETH3D, our method outperforms other recent learning-based approaches and performs comparably on advanced TnT.
gDLS*: Generalized Pose-and-Scale Estimation Given Scale and Gravity Priors
Apr 05, 2020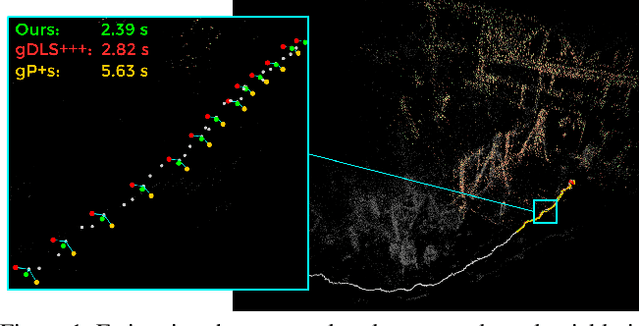
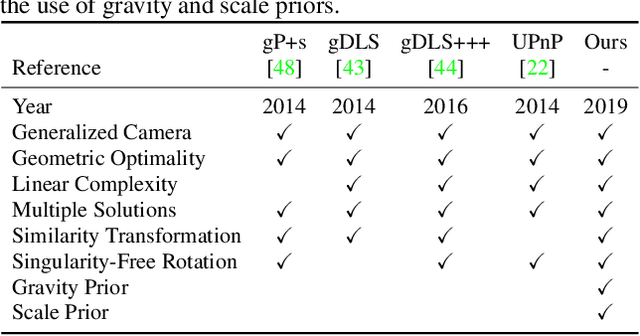
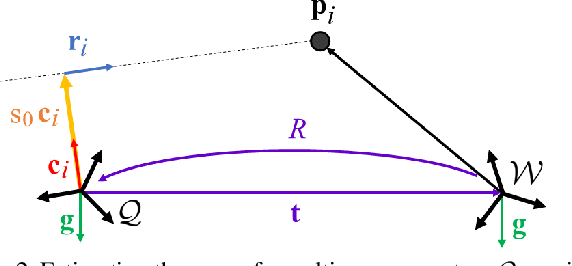
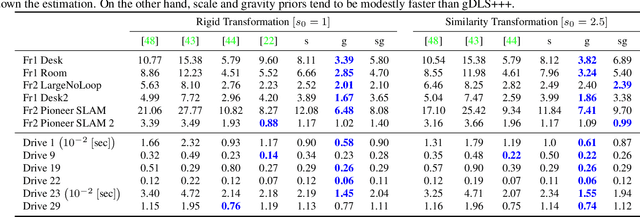
Many real-world applications in augmented reality (AR), 3D mapping, and robotics require both fast and accurate estimation of camera poses and scales from multiple images captured by multiple cameras or a single moving camera. Achieving high speed and maintaining high accuracy in a pose-and-scale estimator are often conflicting goals. To simultaneously achieve both, we exploit a priori knowledge about the solution space. We present gDLS*, a generalized-camera-model pose-and-scale estimator that utilizes rotation and scale priors. gDLS* allows an application to flexibly weigh the contribution of each prior, which is important since priors often come from noisy sensors. Compared to state-of-the-art generalized-pose-and-scale estimators (e.g., gDLS), our experiments on both synthetic and real data consistently demonstrate that gDLS* accelerates the estimation process and improves scale and pose accuracy.
ChromaTag: A Colored Marker and Fast Detection Algorithm
Aug 09, 2017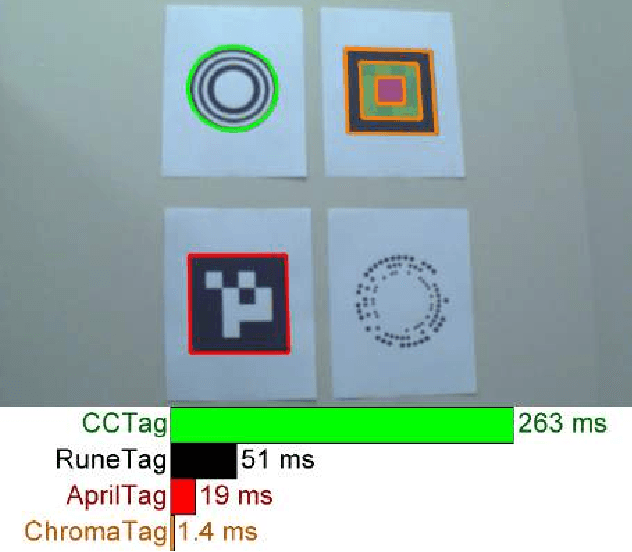
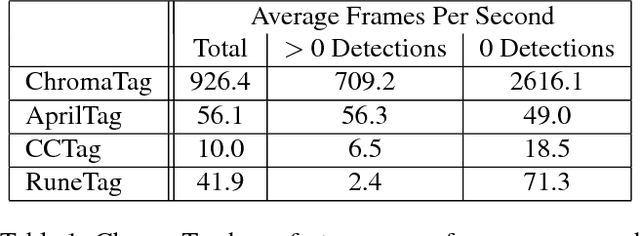

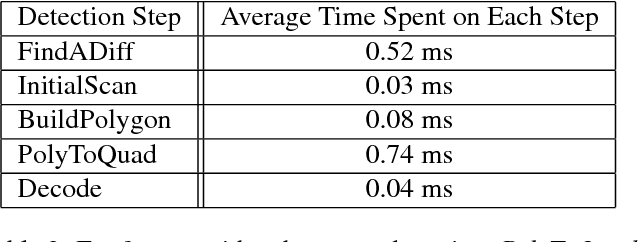
Current fiducial marker detection algorithms rely on marker IDs for false positive rejection. Time is wasted on potential detections that will eventually be rejected as false positives. We introduce ChromaTag, a fiducial marker and detection algorithm designed to use opponent colors to limit and quickly reject initial false detections and grayscale for precise localization. Through experiments, we show that ChromaTag is significantly faster than current fiducial markers while achieving similar or better detection accuracy. We also show how tag size and viewing direction effect detection accuracy. Our contribution is significant because fiducial markers are often used in real-time applications (e.g. marker assisted robot navigation) where heavy computation is required by other parts of the system.
Geometry-Informed Material Recognition
Jul 18, 2016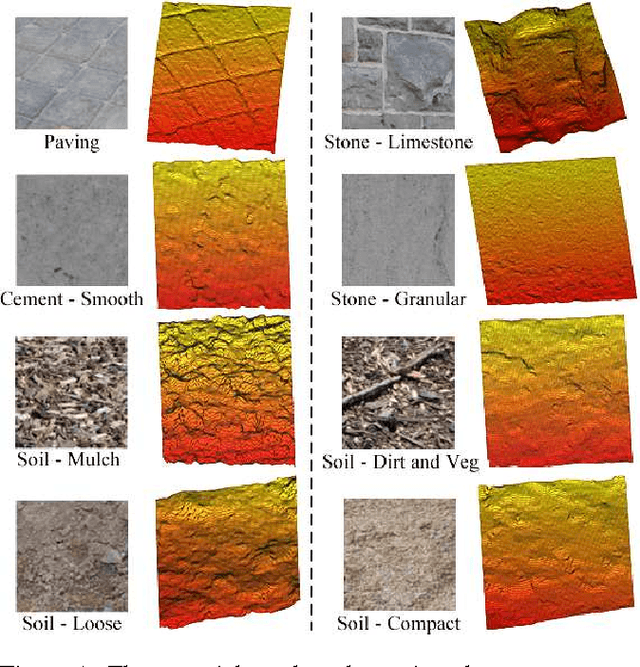


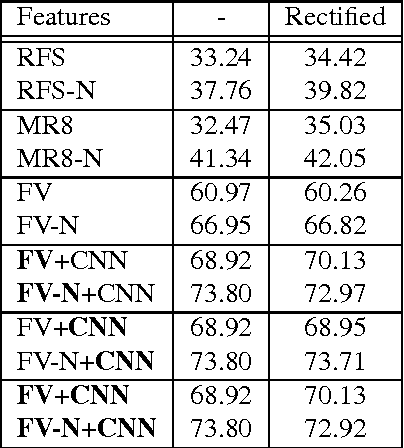
Our goal is to recognize material categories using images and geometry information. In many applications, such as construction management, coarse geometry information is available. We investigate how 3D geometry (surface normals, camera intrinsic and extrinsic parameters) can be used with 2D features (texture and color) to improve material classification. We introduce a new dataset, GeoMat, which is the first to provide both image and geometry data in the form of: (i) training and testing patches that were extracted at different scales and perspectives from real world examples of each material category, and (ii) a large scale construction site scene that includes 160 images and over 800,000 hand labeled 3D points. Our results show that using 2D and 3D features both jointly and independently to model materials improves classification accuracy across multiple scales and viewing directions for both material patches and images of a large scale construction site scene.