 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual ResGCN for Balanced Scene GraphGeneration
Nov 09, 2020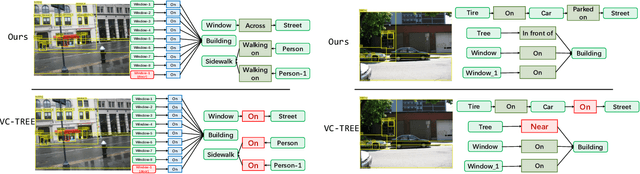
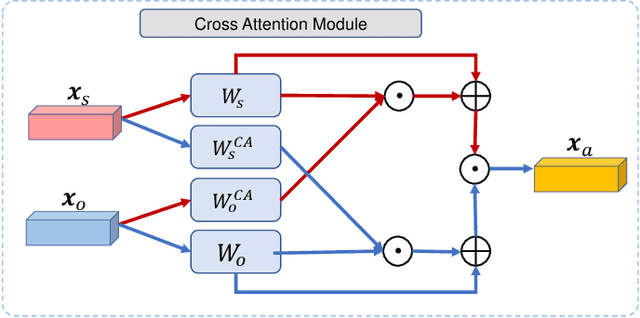
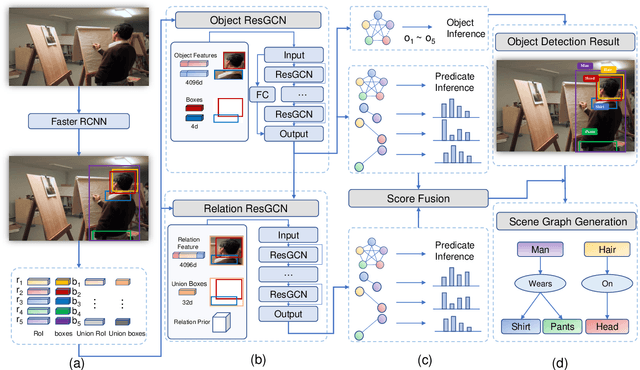
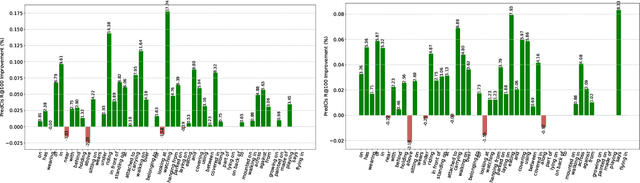
Visual scene graph generation is a challenging task. Previous works have achieved great progress, but most of them do not explicitly consider the class imbalance issue in scene graph generation. Models learned without considering the class imbalance tend to predict the majority classes, which leads to a good performance on trivial frequent predicates, but poor performance on informative infrequent predicates. However, predicates of minority classes often carry more semantic and precise information~(\textit{e.g.}, \emph{`on'} v.s \emph{`parked on'}). % which leads to a good score of recall, but a poor score of mean recall. To alleviate the influence of the class imbalance, we propose a novel model, dubbed \textit{dual ResGCN}, which consists of an object residual graph convolutional network and a relation residual graph convolutional network. The two networks are complementary to each other. The former captures object-level context information, \textit{i.e.,} the connections among objects. We propose a novel ResGCN that enhances object features in a cross attention manner. Besides, we stack multiple contextual coefficients to alleviate the imbalance issue and enrich the prediction diversity. The latter is carefully designed to explicitly capture relation-level context information \textit{i.e.,} the connections among relations. We propose to incorporate the prior about the co-occurrence of relation pairs into the graph to further help alleviate the class imbalance issue. Extensive evaluations of three tasks are performed on the large-scale database VG to demonstrate the superiority of the proposed method.
Auto-Encoding Twin-Bottleneck Hashing
Mar 16, 2020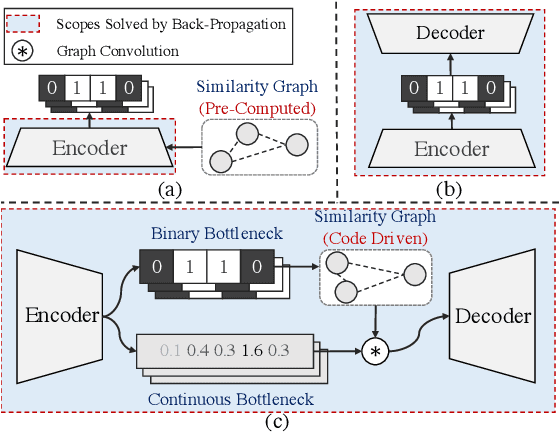
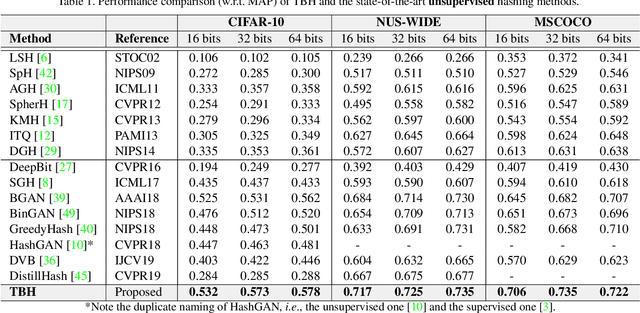
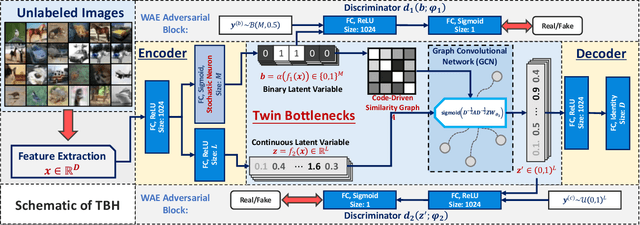
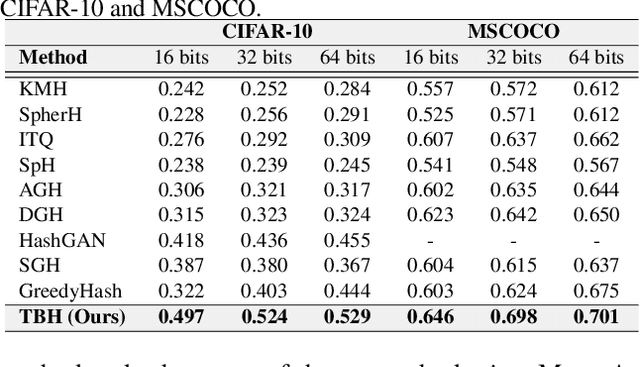
Conventional unsupervised hashing methods usually take advantage of similarity graphs, which are either pre-computed in the high-dimensional space or obtained from random anchor points. On the one hand, existing methods uncouple the procedures of hash function learning and graph construction. On the other hand, graphs empirically built upon original data could introduce biased prior knowledge of data relevance, leading to sub-optimal retrieval performance. In this paper, we tackle the above problems by proposing an efficient and adaptive code-driven graph, which is updated by decoding in the context of an auto-encoder. Specifically, we introduce into our framework twin bottlenecks (i.e., latent variables) that exchange crucial information collaboratively. One bottleneck (i.e., binary codes) conveys the high-level intrinsic data structure captured by the code-driven graph to the other (i.e., continuous variables for low-level detail information), which in turn propagates the updated network feedback for the encoder to learn more discriminative binary codes. The auto-encoding learning objective literally rewards the code-driven graph to learn an optimal encoder. Moreover, the proposed model can be simply optimized by gradient descent without violating the binary constraints. Experiments on benchmarked datasets clearly show the superiority of our framework over the state-of-the-art hashing methods. Our source code can be found at https://github.com/ymcidence/TBH.
Fast Large-Scale Discrete Optimization Based on Principal Coordinate Descent
Sep 16, 2019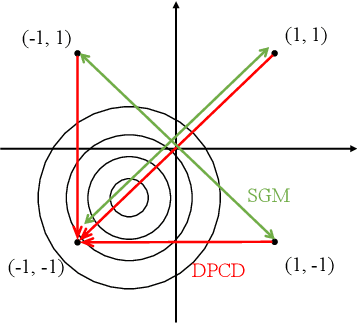
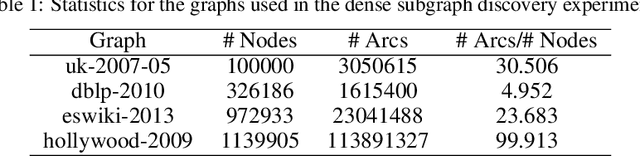
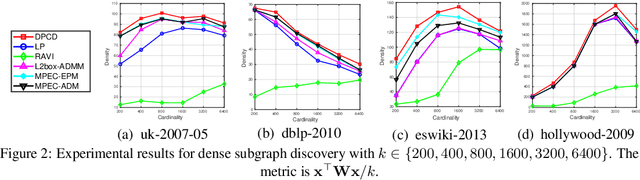
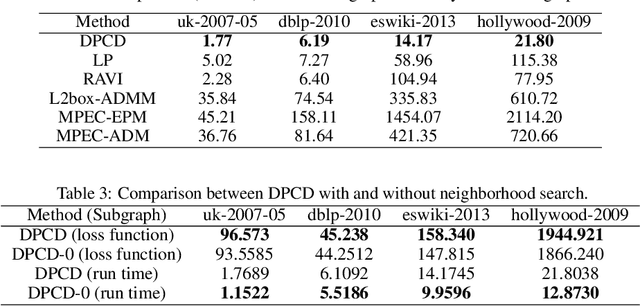
Binary optimization, a representative subclass of discrete optimization, plays an important role in mathematical optimization and has various applications in computer vision and machine learning. Usually, binary optimization problems are NP-hard and difficult to solve due to the binary constraints, especially when the number of variables is very large. Existing methods often suffer from high computational costs or large accumulated quantization errors, or are only designed for specific tasks. In this paper, we propose a fast algorithm to find effective approximate solutions for general binary optimization problems. The proposed algorithm iteratively solves minimization problems related to the linear surrogates of loss functions, which leads to the updating of some binary variables most impacting the value of loss functions in each step. Our method supports a wide class of empirical objective functions with/without restrictions on the numbers of $1$s and $-1$s in the binary variables. Furthermore, the theoretical convergence of our algorithm is proven, and the explicit convergence rates are derived, for objective functions with Lipschitz continuous gradients, which are commonly adopted in practice. Extensive experiments on several binary optimization tasks and large-scale datasets demonstrate the superiority of the proposed algorithm over several state-of-the-art methods in terms of both effectiveness and efficiency.
Cooperative Cross-Stream Network for Discriminative Action Representation
Aug 27, 2019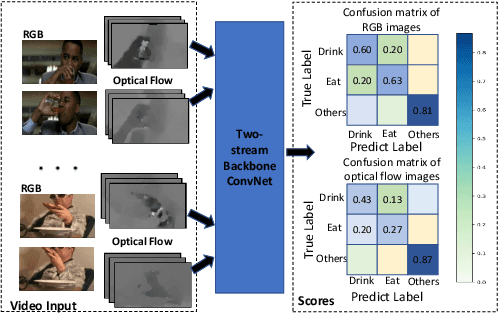
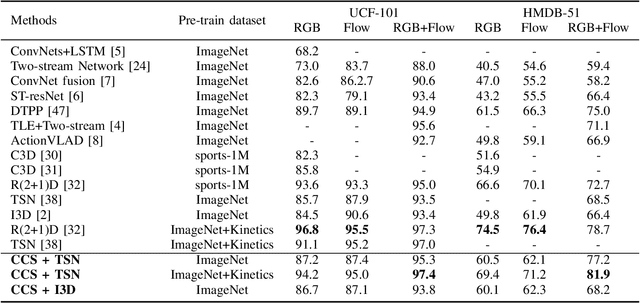
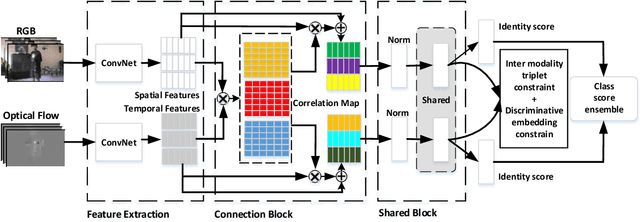
Spatial and temporal stream model has gained great success in video action recognition. Most existing works pay more attention to designing effective features fusion methods, which train the two-stream model in a separate way. However, it's hard to ensure discriminability and explore complementary information between different streams in existing works. In this work, we propose a novel cooperative cross-stream network that investigates the conjoint information in multiple different modalities. The jointly spatial and temporal stream networks feature extraction is accomplished by an end-to-end learning manner. It extracts this complementary information of different modality from a connection block, which aims at exploring correlations of different stream features. Furthermore, different from the conventional ConvNet that learns the deep separable features with only one cross-entropy loss, our proposed model enhances the discriminative power of the deeply learned features and reduces the undesired modality discrepancy by jointly optimizing a modality ranking constraint and a cross-entropy loss for both homogeneous and heterogeneous modalities. The modality ranking constraint constitutes intra-modality discriminative embedding and inter-modality triplet constraint, and it reduces both the intra-modality and cross-modality feature variations. Experiments on three benchmark datasets demonstrate that by cooperating appearance and motion feature extraction, our method can achieve state-of-the-art or competitive performance compared with existing results.
MetaMixUp: Learning Adaptive Interpolation Policy of MixUp with Meta-Learning
Aug 27, 2019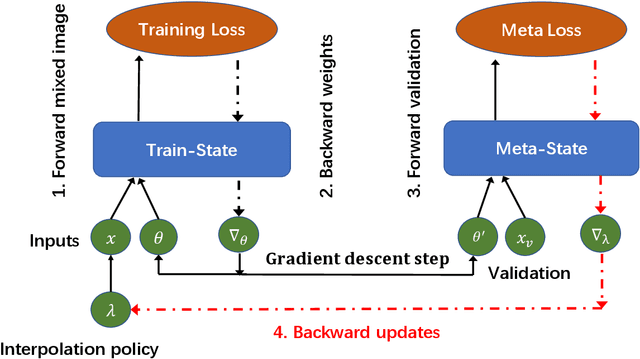
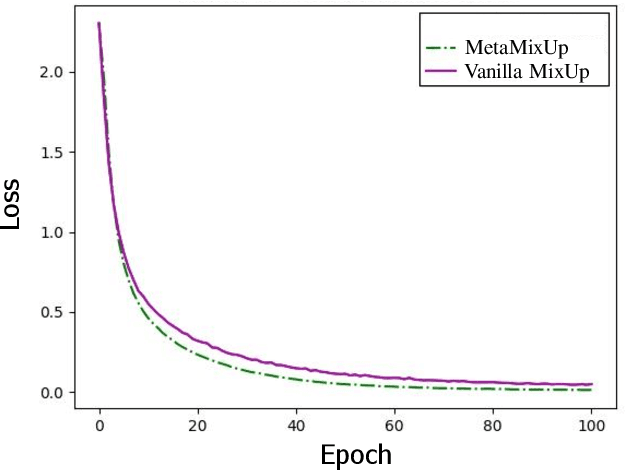
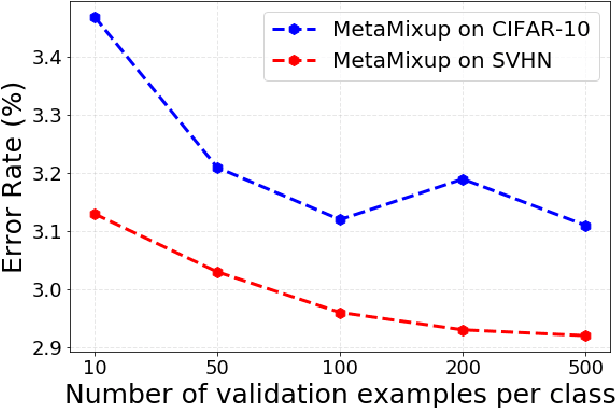
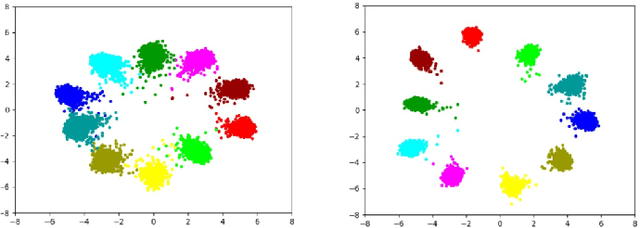
MixUp is an effective data augmentation method to regularize deep neural networks via random linear interpolations between pairs of samples and their labels. It plays an important role in model regularization, semi-supervised learning and domain adaption. However, despite its empirical success, its deficiency of randomly mixing samples has poorly been studied. Since deep networks are capable of memorizing the entire dataset, the corrupted samples generated by vanilla MixUp with a badly chosen interpolation policy will degrade the performance of networks. To overcome the underfitting by corrupted samples, inspired by Meta-learning (learning to learn), we propose a novel technique of learning to mixup in this work, namely, MetaMixUp. Unlike the vanilla MixUp that samples interpolation policy from a predefined distribution, this paper introduces a meta-learning based online optimization approach to dynamically learn the interpolation policy in a data-adaptive way. The validation set performance via meta-learning captures the underfitting issue, which provides more information to refine interpolation policy. Furthermore, we adapt our method for pseudo-label based semisupervised learning (SSL) along with a refined pseudo-labeling strategy. In our experiments, our method achieves better performance than vanilla MixUp and its variants under supervised learning configuration. In particular, extensive experiments show that our MetaMixUp adapted SSL greatly outperforms MixUp and many state-of-the-art methods on CIFAR-10 and SVHN benchmarks under SSL configuration.
Temporal Reasoning Graph for Activity Recognition
Aug 27, 2019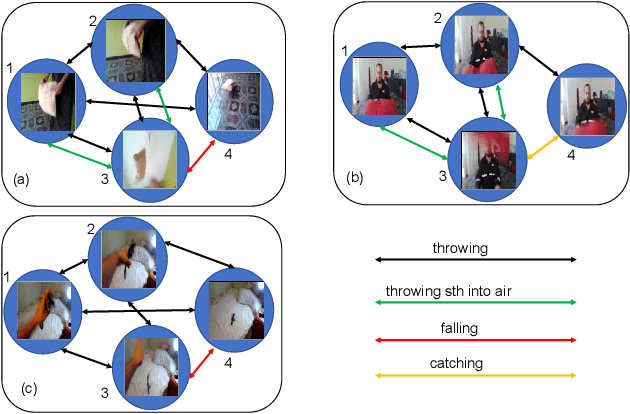
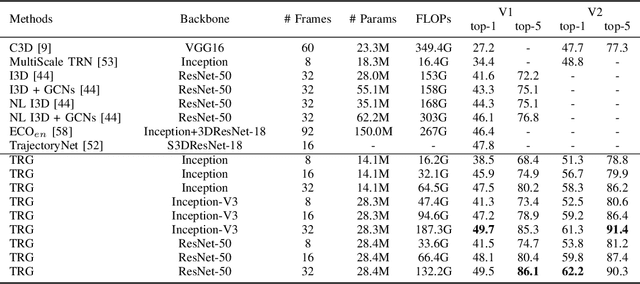
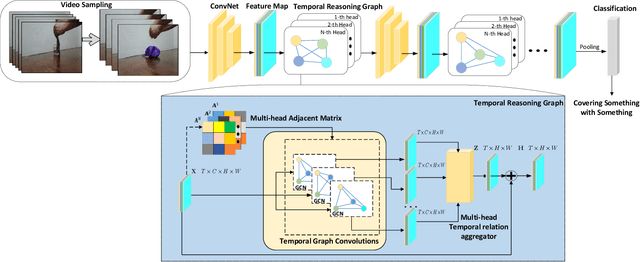
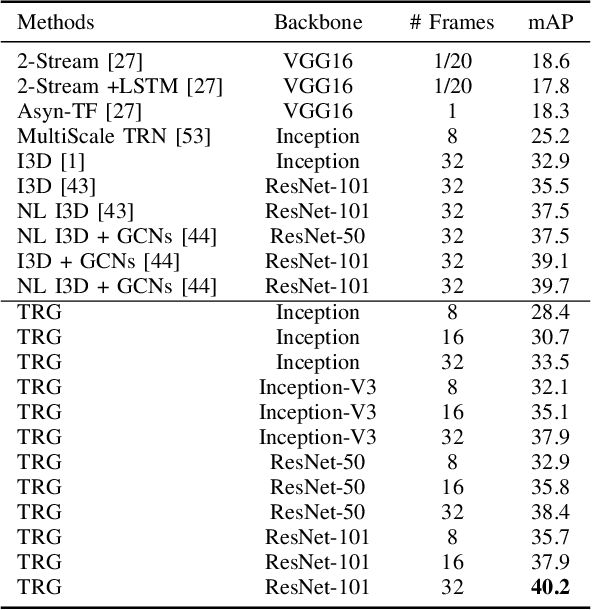
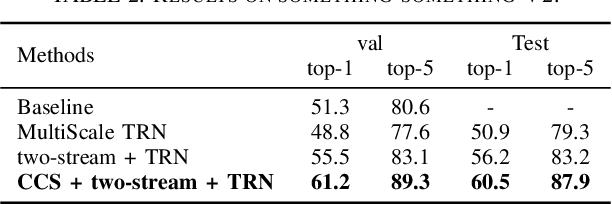
Despite great success has been achieved in activity analysis, it still has many challenges. Most existing work in activity recognition pay more attention to design efficient architecture or video sampling strategy. However, due to the property of fine-grained action and long term structure in video, activity recognition is expected to reason temporal relation between video sequences. In this paper, we propose an efficient temporal reasoning graph (TRG) to simultaneously capture the appearance features and temporal relation between video sequences at multiple time scales. Specifically, we construct learnable temporal relation graphs to explore temporal relation on the multi-scale range. Additionally, to facilitate multi-scale temporal relation extraction, we design a multi-head temporal adjacent matrix to represent multi-kinds of temporal relations. Eventually, a multi-head temporal relation aggregator is proposed to extract the semantic meaning of those features convolving through the graphs. Extensive experiments are performed on widely-used large-scale datasets, such as Something-Something and Charades, and the results show that our model can achieve state-of-the-art performance. Further analysis shows that temporal relation reasoning with our TRG can extract discriminative features for activity recognition.
Make a Face: Towards Arbitrary High Fidelity Face Manipulation
Aug 20, 2019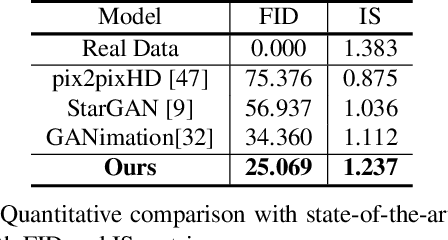
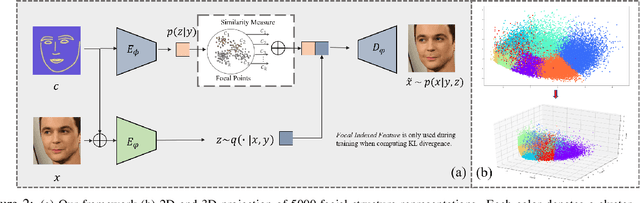
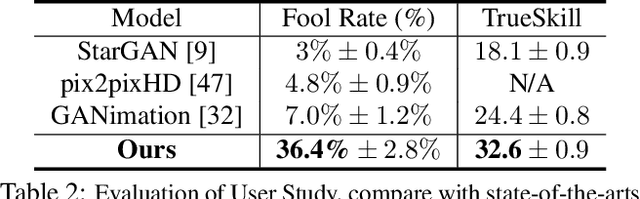
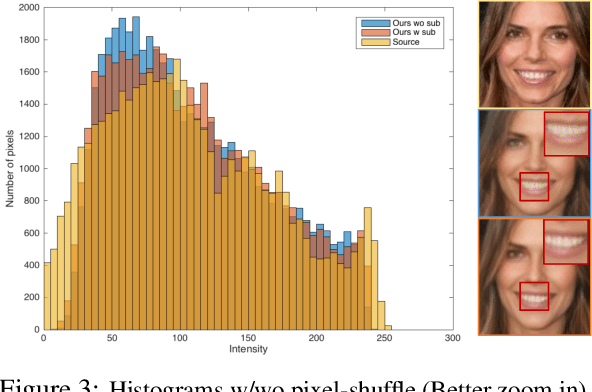
Recent studies have shown remarkable success in face manipulation task with the advance of GANs and VAEs paradigms, but the outputs are sometimes limited to low-resolution and lack of diversity. In this work, we propose Additive Focal Variational Auto-encoder (AF-VAE), a novel approach that can arbitrarily manipulate high-resolution face images using a simple yet effective model and only weak supervision of reconstruction and KL divergence losses. First, a novel additive Gaussian Mixture assumption is introduced with an unsupervised clustering mechanism in the structural latent space, which endows better disentanglement and boosts multi-modal representation with external memory. Second, to improve the perceptual quality of synthesized results, two simple strategies in architecture design are further tailored and discussed on the behavior of Human Visual System (HVS) for the first time, allowing for fine control over the model complexity and sample quality. Human opinion studies and new state-of-the-art Inception Score (IS) / Frechet Inception Distance (FID) demonstrate the superiority of our approach over existing algorithms, advancing both the fidelity and extremity of face manipulation task.
Extracting Visual Knowledge from the Internet: Making Sense of Image Data
Jun 07, 2019
Recent successes in visual recognition can be primarily attributed to feature representation, learning algorithms, and the ever-increasing size of labeled training data. Extensive research has been devoted to the first two, but much less attention has been paid to the third. Due to the high cost of manual labeling, the size of recent efforts such as ImageNet is still relatively small in respect to daily applications. In this work, we mainly focus on how to automatically generate identifying image data for a given visual concept on a vast scale. With the generated image data, we can train a robust recognition model for the given concept. We evaluate the proposed webly supervised approach on the benchmark Pascal VOC 2007 dataset and the results demonstrates the superiority of our proposed approach in image data collection.
Dynamically Visual Disambiguation of Keyword-based Image Search
May 27, 2019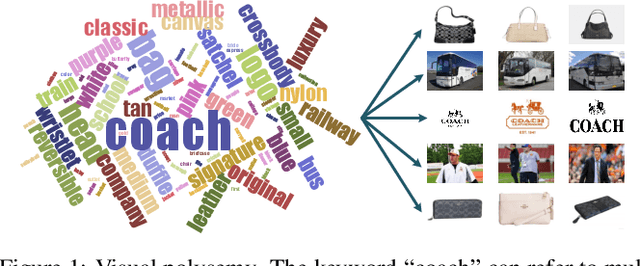
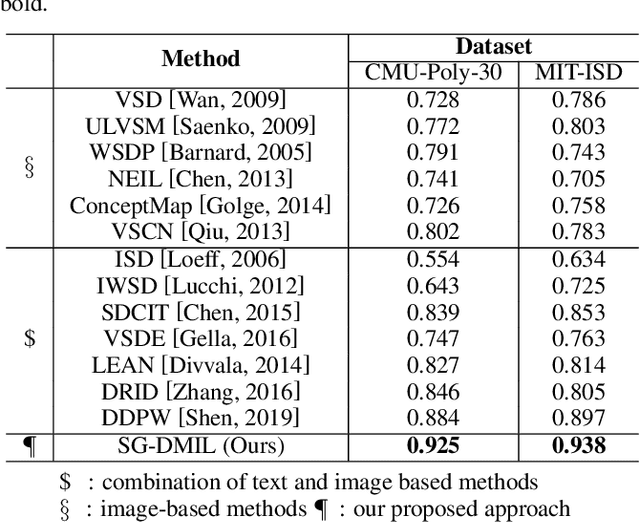
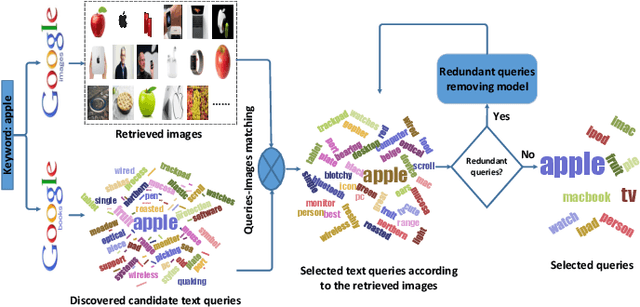
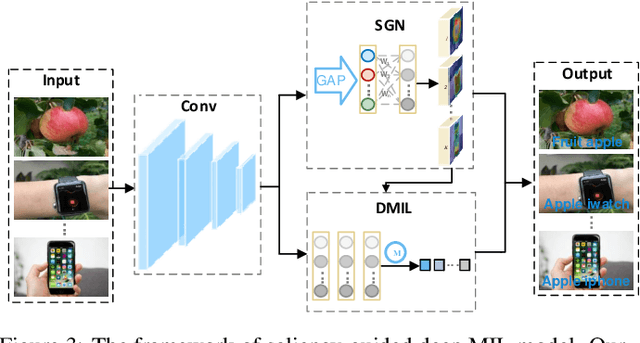
Due to the high cost of manual annotation, learning directly from the web has attracted broad attention. One issue that limits their performance is the problem of visual polysemy. To address this issue, we present an adaptive multi-model framework that resolves polysemy by visual disambiguation. Compared to existing methods, the primary advantage of our approach lies in that our approach can adapt to the dynamic changes in the search results. Our proposed framework consists of two major steps: we first discover and dynamically select the text queries according to the image search results, then we employ the proposed saliency-guided deep multi-instance learning network to remove outliers and learn classification models for visual disambiguation. Extensive experiments demonstrate the superiority of our proposed approach.
Exact Adversarial Attack to Image Captioning via Structured Output Learning with Latent Variables
May 10, 2019
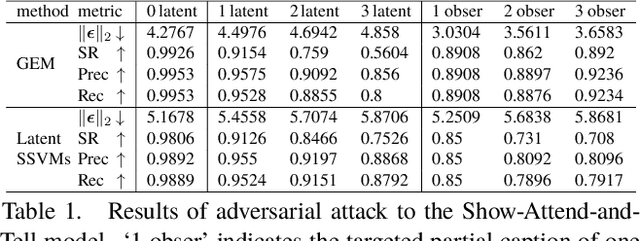

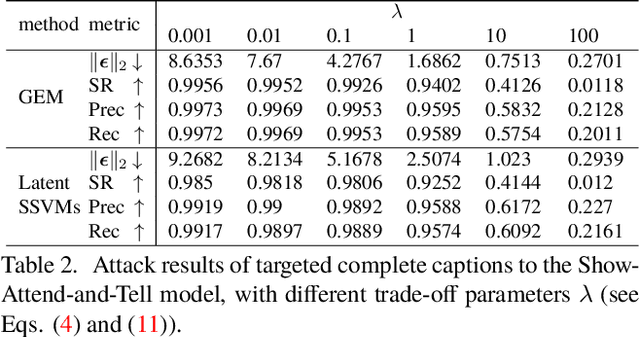
In this work, we study the robustness of a CNN+RNN based image captioning system being subjected to adversarial noises. We propose to fool an image captioning system to generate some targeted partial captions for an image polluted by adversarial noises, even the targeted captions are totally irrelevant to the image content. A partial caption indicates that the words at some locations in this caption are observed, while words at other locations are not restricted.It is the first work to study exact adversarial attacks of targeted partial captions. Due to the sequential dependencies among words in a caption, we formulate the generation of adversarial noises for targeted partial captions as a structured output learning problem with latent variables. Both the generalized expectation maximization algorithm and structural SVMs with latent variables are then adopted to optimize the problem. The proposed methods generate very successful at-tacks to three popular CNN+RNN based image captioning models. Furthermore, the proposed attack methods are used to understand the inner mechanism of image captioning systems, providing the guidance to further improve automatic image captioning systems towards human captioning.