 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language Model
Feb 27, 2025



Recent advances in deep learning have revolutionized seismic monitoring, yet developing a foundation model that performs well across multiple complex tasks remains challenging, particularly when dealing with degraded signals or data scarcity. This work presents SeisMoLLM, the first foundation model that utilizes cross-modal transfer for seismic monitoring, to unleash the power of large-scale pre-training from a large language model without requiring direct pre-training on seismic datasets. Through elaborate waveform tokenization and fine-tuning of pre-trained GPT-2 model, SeisMoLLM achieves state-of-the-art performance on the DiTing and STEAD datasets across five critical tasks: back-azimuth estimation, epicentral distance estimation, magnitude estimation, phase picking, and first-motion polarity classification. It attains 36 best results out of 43 task metrics and 12 top scores out of 16 few-shot generalization metrics, with many relative improvements ranging from 10% to 50%. In addition to its superior performance, SeisMoLLM maintains efficiency comparable to or even better than lightweight models in both training and inference. These findings establish SeisMoLLM as a promising foundation model for practical seismic monitoring and highlight cross-modal transfer as an exciting new direction for earthquake studies, showcasing the potential of advanced deep learning techniques to propel seismology research forward.
NeuroTree: Hierarchical Functional Brain Pathway Decoding for Mental Health Disorders
Feb 26, 2025



Analyzing functional brain networks using functional magnetic resonance imaging (fMRI) is crucial for understanding psychiatric disorders and addictive behaviors. While existing fMRI-based graph convolutional networks (GCNs) show considerable promise for feature extraction, they often fall short in characterizing complex relationships between brain regions and demographic factors and accounting for interpretable variables linked to psychiatric conditions. We propose NeuroTree to overcome these limitations, integrating a k-hop AGE-GCN with neural ordinary differential equations (ODEs). This framework leverages an attention mechanism to optimize functional connectivity (FC), thereby enhancing dynamic FC feature learning for brain disease classification. Furthermore, NeuroTree effectively decodes fMRI network features into tree structures, which improves the capture of high-order brain regional pathway features and enables the identification of hierarchical neural behavioral patterns essential for understanding disease-related brain subnetworks. Our empirical evaluations demonstrate that NeuroTree achieves state-of-the-art performance across two distinct mental disorder datasets and provides valuable insights into age-related deterioration patterns. These findings underscore the model's efficacy in predicting psychiatric disorders and elucidating their underlying neural mechanisms.
Robust Dynamic Facial Expression Recognition
Feb 22, 2025The study of Dynamic Facial Expression Recognition (DFER) is a nascent field of research that involves the automated recognition of facial expressions in video data. Although existing research has primarily focused on learning representations under noisy and hard samples, the issue of the coexistence of both types of samples remains unresolved. In order to overcome this challenge, this paper proposes a robust method of distinguishing between hard and noisy samples. This is achieved by evaluating the prediction agreement of the model on different sampled clips of the video. Subsequently, methodologies that reinforce the learning of hard samples and mitigate the impact of noisy samples can be employed. Moreover, to identify the principal expression in a video and enhance the model's capacity for representation learning, comprising a key expression re-sampling framework and a dual-stream hierarchical network is proposed, namely Robust Dynamic Facial Expression Recognition (RDFER). The key expression re-sampling framework is designed to identify the key expression, thereby mitigating the potential confusion caused by non-target expressions. RDFER employs two sequence models with the objective of disentangling short-term facial movements and long-term emotional changes. The proposed method has been shown to outperform current State-Of-The-Art approaches in DFER through extensive experimentation on benchmark datasets such as DFEW and FERV39K. A comprehensive analysis provides valuable insights and observations regarding the proposed agreement. This work has significant implications for the field of dynamic facial expression recognition and promotes the further development of the field of noise-consistent robust learning in dynamic facial expression recognition. The code is available from [https://github.com/Cross-Innovation-Lab/RDFER].
MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation
Feb 06, 2025



This paper presents a method that allows users to design cinematic video shots in the context of image-to-video generation. Shot design, a critical aspect of filmmaking, involves meticulously planning both camera movements and object motions in a scene. However, enabling intuitive shot design in modern image-to-video generation systems presents two main challenges: first, effectively capturing user intentions on the motion design, where both camera movements and scene-space object motions must be specified jointly; and second, representing motion information that can be effectively utilized by a video diffusion model to synthesize the image animations. To address these challenges, we introduce MotionCanvas, a method that integrates user-driven controls into image-to-video (I2V) generation models, allowing users to control both object and camera motions in a scene-aware manner. By connecting insights from classical computer graphics and contemporary video generation techniques, we demonstrate the ability to achieve 3D-aware motion control in I2V synthesis without requiring costly 3D-related training data. MotionCanvas enables users to intuitively depict scene-space motion intentions, and translates them into spatiotemporal motion-conditioning signals for video diffusion models. We demonstrate the effectiveness of our method on a wide range of real-world image content and shot-design scenarios, highlighting its potential to enhance the creative workflows in digital content creation and adapt to various image and video editing applications.
Membership Inference Attack Should Move On to Distributional Statistics for Distilled Generative Models
Feb 05, 2025



Membership inference attacks (MIAs) determine whether certain data instances were used to train a model by exploiting the differences in how the model responds to seen versus unseen instances. This capability makes MIAs important in assessing privacy leakage within modern generative AI systems. However, this paper reveals an oversight in existing MIAs against \emph{distilled generative models}: attackers can no longer detect a teacher model's training instances individually when targeting the distilled student model, as the student learns from the teacher-generated data rather than its original member data, preventing direct instance-level memorization. Nevertheless, we find that student-generated samples exhibit a significantly stronger distributional alignment with teacher's member data than non-member data. This leads us to posit that MIAs \emph{on distilled generative models should shift from instance-level to distribution-level statistics}. We thereby introduce a \emph{set-based} MIA framework that measures \emph{relative} distributional discrepancies between student-generated data\emph{sets} and potential member/non-member data\emph{sets}, Empirically, distributional statistics reliably distinguish a teacher's member data from non-member data through the distilled model. Finally, we discuss scenarios in which our setup faces limitations.
Limitations of Large Language Models in Clinical Problem-Solving Arising from Inflexible Reasoning
Feb 05, 2025Large Language Models (LLMs) have attained human-level accuracy on medical question-answer (QA) benchmarks. However, their limitations in navigating open-ended clinical scenarios have recently been shown, raising concerns about the robustness and generalizability of LLM reasoning across diverse, real-world medical tasks. To probe potential LLM failure modes in clinical problem-solving, we present the medical abstraction and reasoning corpus (M-ARC). M-ARC assesses clinical reasoning through scenarios designed to exploit the Einstellung effect -- the fixation of thought arising from prior experience, targeting LLM inductive biases toward inflexible pattern matching from their training data rather than engaging in flexible reasoning. We find that LLMs, including current state-of-the-art o1 and Gemini models, perform poorly compared to physicians on M-ARC, often demonstrating lack of commonsense medical reasoning and a propensity to hallucinate. In addition, uncertainty estimation analyses indicate that LLMs exhibit overconfidence in their answers, despite their limited accuracy. The failure modes revealed by M-ARC in LLM medical reasoning underscore the need to exercise caution when deploying these models in clinical settings.
Pushing the Boundaries of State Space Models for Image and Video Generation
Feb 03, 2025



While Transformers have become the dominant architecture for visual generation, linear attention models, such as the state-space models (SSM), are increasingly recognized for their efficiency in processing long visual sequences. However, the essential efficiency of these models comes from formulating a limited recurrent state, enforcing causality among tokens that are prone to inconsistent modeling of N-dimensional visual data, leaving questions on their capacity to generate long non-causal sequences. In this paper, we explore the boundary of SSM on image and video generation by building the largest-scale diffusion SSM-Transformer hybrid model to date (5B parameters) based on the sub-quadratic bi-directional Hydra and self-attention, and generate up to 2K images and 360p 8 seconds (16 FPS) videos. Our results demonstrate that the model can produce faithful results aligned with complex text prompts and temporal consistent videos with high dynamics, suggesting the great potential of using SSMs for visual generation tasks.
Exploring the Role of Explicit Temporal Modeling in Multimodal Large Language Models for Video Understanding
Jan 28, 2025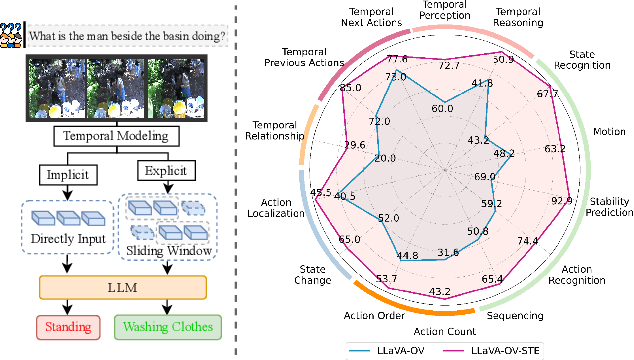
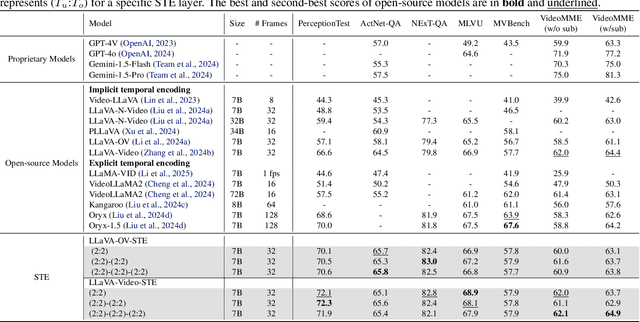
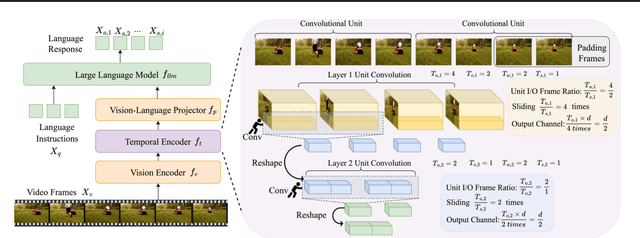
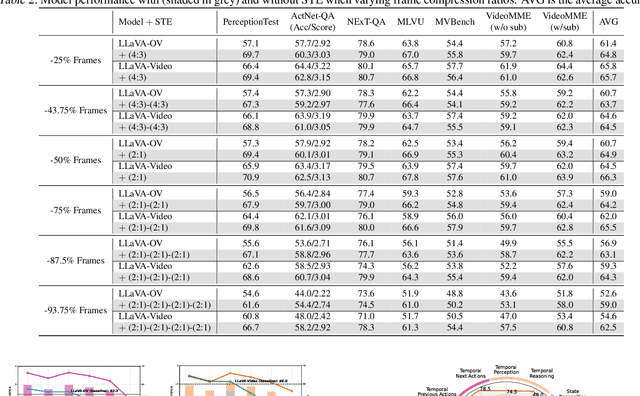
Applying Multimodal Large Language Models (MLLMs) to video understanding presents significant challenges due to the need to model temporal relations across frames. Existing approaches adopt either implicit temporal modeling, relying solely on the LLM decoder, or explicit temporal modeling, employing auxiliary temporal encoders. To investigate this debate between the two paradigms, we propose the Stackable Temporal Encoder (STE). STE enables flexible explicit temporal modeling with adjustable temporal receptive fields and token compression ratios. Using STE, we systematically compare implicit and explicit temporal modeling across dimensions such as overall performance, token compression effectiveness, and temporal-specific understanding. We also explore STE's design considerations and broader impacts as a plug-in module and in image modalities. Our findings emphasize the critical role of explicit temporal modeling, providing actionable insights to advance video MLLMs.
Progressive Growing of Video Tokenizers for Highly Compressed Latent Spaces
Jan 09, 2025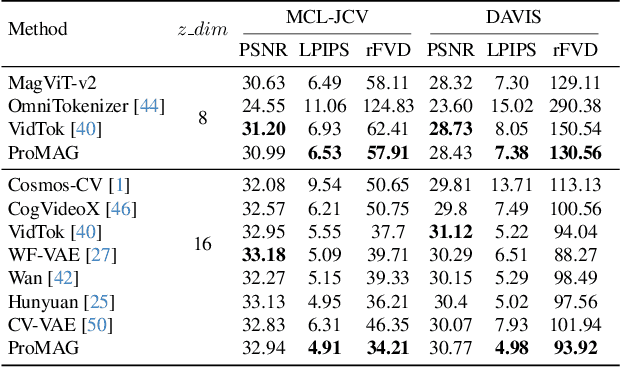

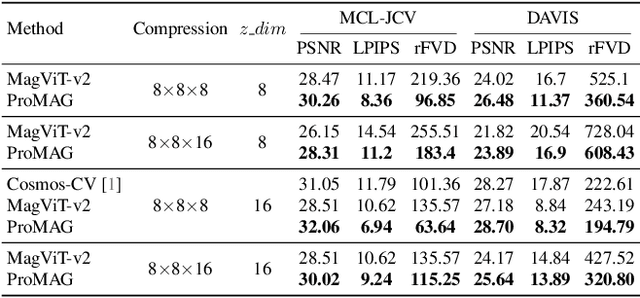

Video tokenizers are essential for latent video diffusion models, converting raw video data into spatiotemporally compressed latent spaces for efficient training. However, extending state-of-the-art video tokenizers to achieve a temporal compression ratio beyond 4x without increasing channel capacity poses significant challenges. In this work, we propose an alternative approach to enhance temporal compression. We find that the reconstruction quality of temporally subsampled videos from a low-compression encoder surpasses that of high-compression encoders applied to original videos. This indicates that high-compression models can leverage representations from lower-compression models. Building on this insight, we develop a bootstrapped high-temporal-compression model that progressively trains high-compression blocks atop well-trained lower-compression models. Our method includes a cross-level feature-mixing module to retain information from the pretrained low-compression model and guide higher-compression blocks to capture the remaining details from the full video sequence. Evaluation of video benchmarks shows that our method significantly improves reconstruction quality while increasing temporal compression compared to direct extensions of existing video tokenizers. Furthermore, the resulting compact latent space effectively trains a video diffusion model for high-quality video generation with a reduced token budget.
DispFormer: Pretrained Transformer for Flexible Dispersion Curve Inversion from Global Synthesis to Regional Applications
Jan 08, 2025



Surface wave dispersion curve inversion is essential for estimating subsurface Shear-wave velocity ($v_s$), yet traditional methods often struggle to balance computational efficiency with inversion accuracy. While deep learning approaches show promise, previous studies typically require large amounts of labeled data and struggle with real-world datasets that have varying period ranges, missing data, and low signal-to-noise ratios. This study proposes DispFormer, a transformer-based neural network for inverting the $v_s$ profile from Rayleigh-wave phase and group dispersion curves. DispFormer processes dispersion data at each period independently, thereby allowing it to handle data of varying lengths without requiring network modifications or alignment between training and testing data. The performance is demonstrated by pre-training it on a global synthetic dataset and testing it on two regional synthetic datasets using zero-shot and few-shot strategies. Results indicate that zero-shot DispFormer, even without any labeled data, produces inversion profiles that match well with the ground truth, providing a deployable initial model generator to assist traditional methods. When labeled data is available, few-shot DispFormer outperforms traditional methods with only a small number of labels. Furthermore, real-world tests indicate that DispFormer effectively handles varying length data, and yields lower data residuals than reference models. These findings demonstrate that DispFormer provides a robust foundation model for dispersion curve inversion and is a promising approach for broader applications.