 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023



As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023



Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
TEA: Test-time Energy Adaptation
Nov 24, 2023



Test-time adaptation (TTA) aims to improve model generalizability when test data diverges from training distribution, offering the distinct advantage of not requiring access to training data and processes, especially valuable in the context of large pre-trained models. However, current TTA methods fail to address the fundamental issue: covariate shift, i.e., the decreased generalizability can be attributed to the model's reliance on the marginal distribution of the training data, which may impair model calibration and introduce confirmation bias. To address this, we propose a novel energy-based perspective, enhancing the model's perception of target data distributions without requiring access to training data or processes. Building on this perspective, we introduce $\textbf{T}$est-time $\textbf{E}$nergy $\textbf{A}$daptation ($\textbf{TEA}$), which transforms the trained classifier into an energy-based model and aligns the model's distribution with the test data's, enhancing its ability to perceive test distributions and thus improving overall generalizability. Extensive experiments across multiple tasks, benchmarks and architectures demonstrate TEA's superior generalization performance against state-of-the-art methods. Further in-depth analyses reveal that TEA can equip the model with a comprehensive perception of test distribution, ultimately paving the way toward improved generalization and calibration.
Robust Recommender System: A Survey and Future Directions
Sep 05, 2023



With the rapid growth of information, recommender systems have become integral for providing personalized suggestions and overcoming information overload. However, their practical deployment often encounters "dirty" data, where noise or malicious information can lead to abnormal recommendations. Research on improving recommender systems' robustness against such dirty data has thus gained significant attention. This survey provides a comprehensive review of recent work on recommender systems' robustness. We first present a taxonomy to organize current techniques for withstanding malicious attacks and natural noise. We then explore state-of-the-art methods in each category, including fraudster detection, adversarial training, certifiable robust training against malicious attacks, and regularization, purification, self-supervised learning against natural noise. Additionally, we summarize evaluation metrics and common datasets used to assess robustness. We discuss robustness across varying recommendation scenarios and its interplay with other properties like accuracy, interpretability, privacy, and fairness. Finally, we delve into open issues and future research directions in this emerging field. Our goal is to equip readers with a holistic understanding of robust recommender systems and spotlight pathways for future research and development.
A Large Language Model Enhanced Conversational Recommender System
Aug 11, 2023Conversational recommender systems (CRSs) aim to recommend high-quality items to users through a dialogue interface. It usually contains multiple sub-tasks, such as user preference elicitation, recommendation, explanation, and item information search. To develop effective CRSs, there are some challenges: 1) how to properly manage sub-tasks; 2) how to effectively solve different sub-tasks; and 3) how to correctly generate responses that interact with users. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to reason and generate, presenting a new opportunity to develop more powerful CRSs. In this work, we propose a new LLM-based CRS, referred to as LLMCRS, to address the above challenges. For sub-task management, we leverage the reasoning ability of LLM to effectively manage sub-task. For sub-task solving, we collaborate LLM with expert models of different sub-tasks to achieve the enhanced performance. For response generation, we utilize the generation ability of LLM as a language interface to better interact with users. Specifically, LLMCRS divides the workflow into four stages: sub-task detection, model matching, sub-task execution, and response generation. LLMCRS also designs schema-based instruction, demonstration-based instruction, dynamic sub-task and model matching, and summary-based generation to instruct LLM to generate desired results in the workflow. Finally, to adapt LLM to conversational recommendations, we also propose to fine-tune LLM with reinforcement learning from CRSs performance feedback, referred to as RLPF. Experimental results on benchmark datasets show that LLMCRS with RLPF outperforms the existing methods.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023



Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
PDE+: Enhancing Generalization via PDE with Adaptive Distributional Diffusion
May 25, 2023The generalization of neural networks is a central challenge in machine learning, especially concerning the performance under distributions that differ from training ones. Current methods, mainly based on the data-driven paradigm such as data augmentation, adversarial training, and noise injection, may encounter limited generalization due to model non-smoothness. In this paper, we propose to investigate generalization from a Partial Differential Equation (PDE) perspective, aiming to enhance it directly through the underlying function of neural networks, rather than focusing on adjusting input data. Specifically, we first establish the connection between neural network generalization and the smoothness of the solution to a specific PDE, namely ``transport equation''. Building upon this, we propose a general framework that introduces adaptive distributional diffusion into transport equation to enhance the smoothness of its solution, thereby improving generalization. In the context of neural networks, we put this theoretical framework into practice as PDE+ (\textbf{PDE} with \textbf{A}daptive \textbf{D}istributional \textbf{D}iffusion) which diffuses each sample into a distribution covering semantically similar inputs. This enables better coverage of potentially unobserved distributions in training, thus improving generalization beyond merely data-driven methods. The effectiveness of PDE+ is validated in extensive settings, including clean samples and various corruptions, demonstrating its superior performance compared to SOTA methods.
Rethinking GNN-based Entity Alignment on Heterogeneous Knowledge Graphs: New Datasets and A New Method
Apr 10, 2023The development of knowledge graph (KG) applications has led to a rising need for entity alignment (EA) between heterogeneous KGs that are extracted from various sources. Recently, graph neural networks (GNNs) have been widely adopted in EA tasks due to GNNs' impressive ability to capture structure information. However, we have observed that the oversimplified settings of the existing common EA datasets are distant from real-world scenarios, which obstructs a full understanding of the advancements achieved by recent methods. This phenomenon makes us ponder: Do existing GNN-based EA methods really make great progress? In this paper, to study the performance of EA methods in realistic settings, we focus on the alignment of highly heterogeneous KGs (HHKGs) (e.g., event KGs and general KGs) which are different with regard to the scale and structure, and share fewer overlapping entities. First, we sweep the unreasonable settings, and propose two new HHKG datasets that closely mimic real-world EA scenarios. Then, based on the proposed datasets, we conduct extensive experiments to evaluate previous representative EA methods, and reveal interesting findings about the progress of GNN-based EA methods. We find that the structural information becomes difficult to exploit but still valuable in aligning HHKGs. This phenomenon leads to inferior performance of existing EA methods, especially GNN-based methods. Our findings shed light on the potential problems resulting from an impulsive application of GNN-based methods as a panacea for all EA datasets. Finally, we introduce a simple but effective method: Simple-HHEA, which comprehensively utilizes entity name, structure, and temporal information. Experiment results show Simple-HHEA outperforms previous models on HHKG datasets.
LegoNet: A Fast and Exact Unlearning Architecture
Oct 28, 2022Machine unlearning aims to erase the impact of specific training samples upon deleted requests from a trained model. Re-training the model on the retained data after deletion is an effective but not efficient way due to the huge number of model parameters and re-training samples. To speed up, a natural way is to reduce such parameters and samples. However, such a strategy typically leads to a loss in model performance, which poses the challenge that increasing the unlearning efficiency while maintaining acceptable performance. In this paper, we present a novel network, namely \textit{LegoNet}, which adopts the framework of ``fixed encoder + multiple adapters''. We fix the encoder~(\ie the backbone for representation learning) of LegoNet to reduce the parameters that need to be re-trained during unlearning. Since the encoder occupies a major part of the model parameters, the unlearning efficiency is significantly improved. However, fixing the encoder empirically leads to a significant performance drop. To compensate for the performance loss, we adopt the ensemble of multiple adapters, which are independent sub-models adopted to infer the prediction by the encoding~(\ie the output of the encoder). Furthermore, we design an activation mechanism for the adapters to further trade off unlearning efficiency against model performance. This mechanism guarantees that each sample can only impact very few adapters, so during unlearning, parameters and samples that need to be re-trained are both reduced. The empirical experiments verify that LegoNet accomplishes fast and exact unlearning while maintaining acceptable performance, synthetically outperforming unlearning baselines.
MILAN: Masked Image Pretraining on Language Assisted Representation
Aug 15, 2022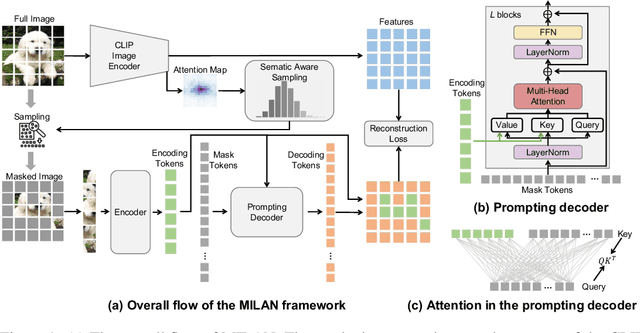
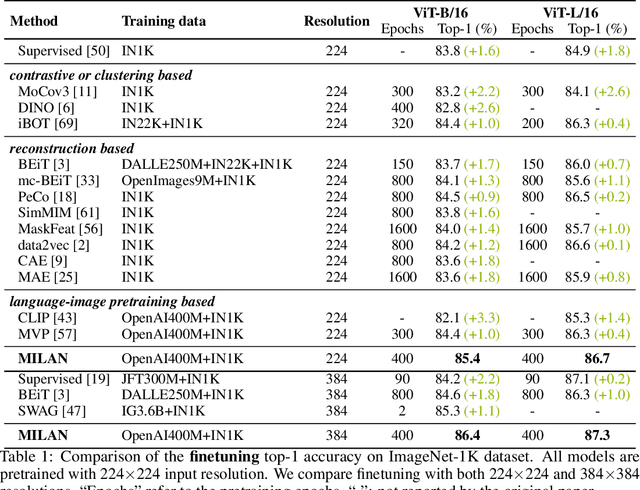

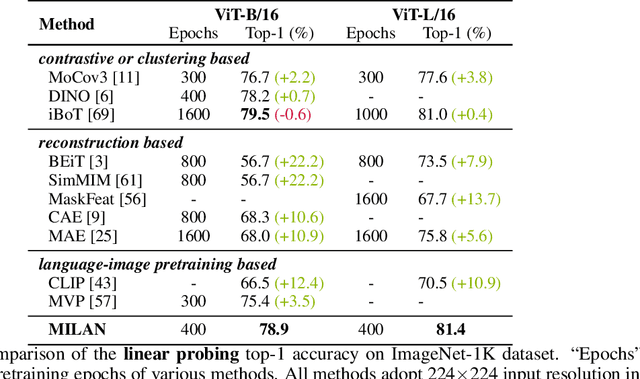
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled datasets, reconstruction based masked autoencoders are gaining popularity, which learn high quality transferable representations from unlabeled images. For the same purpose, recent weakly supervised image pretraining methods explore language supervision from text captions accompanying the images. In this work, we propose masked image pretraining on language assisted representation, dubbed as MILAN. Instead of predicting raw pixels or low level features, our pretraining objective is to reconstruct the image features with substantial semantic signals that are obtained using caption supervision. Moreover, to accommodate our reconstruction target, we propose a more efficient prompting decoder architecture and a semantic aware mask sampling mechanism, which further advance the transfer performance of the pretrained model. Experimental results demonstrate that MILAN delivers higher accuracy than the previous works. When the masked autoencoder is pretrained and finetuned on ImageNet-1K dataset with an input resolution of 224x224, MILAN achieves a top-1 accuracy of 85.4% on ViTB/16, surpassing previous state-of-the-arts by 1%. In the downstream semantic segmentation task, MILAN achieves 52.7 mIoU using ViT-B/16 backbone on ADE20K dataset, outperforming previous masked pretraining results by 4 points.