 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling the Long Video Understanding of Multimodal Large Language Models via Visual Memory Mechanism
Mar 31, 2026Long video understanding is a key challenge that plagues the advancement of \emph{Multimodal Large language Models} (MLLMs). In this paper, we study this problem from the perspective of visual memory mechanism, and proposed a novel and training-free approach, termed \emph{Flexible Memory} (\textbf{FlexMem}). In principle, FlexMem aims to mimic human behavior of video watching, \emph{i.e.}, continually watching video content and recalling the most relevant memory fragments to answer the question. In this way, FlexMem can help MLLMs achieve video understanding of infinite lengths, unlike previous methods that process all video information at once and have input upper-limit. Concretely, FlexMem first consider the visual KV caches as the memory sources, and realize the effective memory transfer and writing via a dual-pathway compression design. Afterwards, FlexMem also explores different memory reading strategies for the diverse video understanding tasks, including the popular streaming one. To validate FlexMem, we apply it to two popular video-MLLMs, and conduct extensive experiments on five long video and one streaming video task. The experimental results show that on \textbf{a single 3090 GPU}, our FlexMem can achieve obvious improvements than existing efficient video understanding methods and process more than \textbf{1k frames}, which also helps the base MLLMs achieve comparable or even better performance than SOTA MLLMs on some benchmarks, \emph{e.g.} , GPT-4o and Gemini-1.5 Pro.
ForestPrune: High-ratio Visual Token Compression for Video Multimodal Large Language Models via Spatial-Temporal Forest Modeling
Mar 24, 2026Due to the great saving of computation and memory overhead, token compression has become a research hot-spot for MLLMs and achieved remarkable progress in image-language tasks. However, for the video, existing methods still fall short of high-ratio token compression. We attribute this shortcoming to the insufficient modeling of temporal and continual video content, and propose a novel and training-free token pruning method for video MLLMs, termed ForestPrune, which achieves effective and high-ratio pruning via Spatial-temporal Forest Modeling. In practice, ForestPrune construct token forests across video frames based on the semantic, spatial and temporal constraints, making an overall comprehension of videos. Afterwards, ForestPrune evaluates the importance of token trees and nodes based on tree depth and node roles, thereby obtaining a globally optimal pruning decision. To validate ForestPrune, we apply it to two representative video MLLMs, namely LLaVA-Video and LLaVA-OneVision, and conduct extensive experiments on a bunch of video benchmarks. The experimental results not only show the great effectiveness for video MLLMs, e.g., retaining 95.8% average accuracy while reducing 90% tokens for LLaVA-OneVision, but also show its superior performance and efficiency than the compared token compression methods, e.g., +10.1% accuracy on MLVU and -81.4% pruning time than FrameFusion on LLaVA-Video.
DeepInv: A Novel Self-supervised Learning Approach for Fast and Accurate Diffusion Inversion
Jan 04, 2026Diffusion inversion is a task of recovering the noise of an image in a diffusion model, which is vital for controllable diffusion image editing. At present, diffusion inversion still remains a challenging task due to the lack of viable supervision signals. Thus, most existing methods resort to approximation-based solutions, which however are often at the cost of performance or efficiency. To remedy these shortcomings, we propose a novel self-supervised diffusion inversion approach in this paper, termed Deep Inversion (DeepInv). Instead of requiring ground-truth noise annotations, we introduce a self-supervised objective as well as a data augmentation strategy to generate high-quality pseudo noises from real images without manual intervention. Based on these two innovative designs, DeepInv is also equipped with an iterative and multi-scale training regime to train a parameterized inversion solver, thereby achieving the fast and accurate image-to-noise mapping. To the best of our knowledge, this is the first attempt of presenting a trainable solver to predict inversion noise step by step. The extensive experiments show that our DeepInv can achieve much better performance and inference speed than the compared methods, e.g., +40.435% SSIM than EasyInv and +9887.5% speed than ReNoise on COCO dataset. Moreover, our careful designs of trainable solvers can also provide insights to the community. Codes and model parameters will be released in https://github.com/potato-kitty/DeepInv.
Graph Attention Collaborative Similarity Embedding for Recommender System
Feb 05, 2021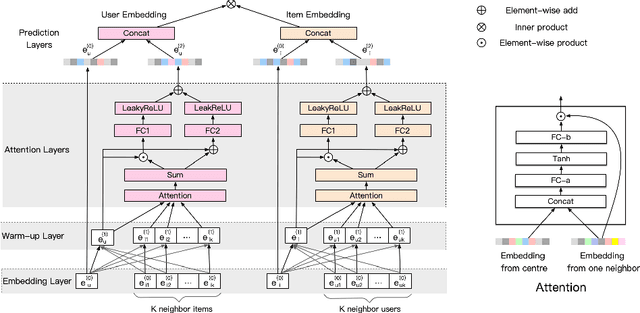
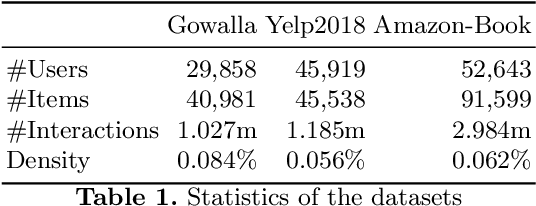
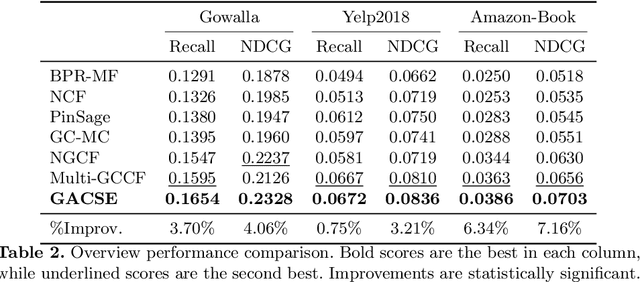
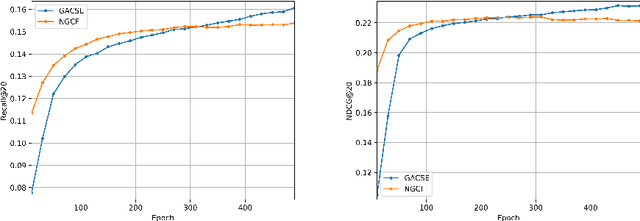
We present Graph Attention Collaborative Similarity Embedding (GACSE), a new recommendation framework that exploits collaborative information in the user-item bipartite graph for representation learning. Our framework consists of two parts: the first part is to learn explicit graph collaborative filtering information such as user-item association through embedding propagation with attention mechanism, and the second part is to learn implicit graph collaborative information such as user-user similarities and item-item similarities through auxiliary loss. We design a new loss function that combines BPR loss with adaptive margin and similarity loss for the similarities learning. Extensive experiments on three benchmarks show that our model is consistently better than the latest state-of-the-art models.