 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Boosting Decision Tree with LSTM for Investment Prediction
May 29, 2025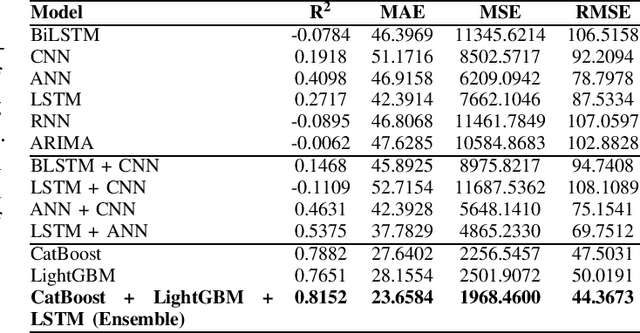
This paper proposes a hybrid framework combining LSTM (Long Short-Term Memory) networks with LightGBM and CatBoost for stock price prediction. The framework processes time-series financial data and evaluates performance using seven models: Artificial Neural Networks (ANNs), Convolutional Neural Networks (CNNs), Bidirectional LSTM (BiLSTM), vanilla LSTM, XGBoost, LightGBM, and standard Neural Networks (NNs). Key metrics, including MAE, R-squared, MSE, and RMSE, are used to establish benchmarks across different time scales. Building on these benchmarks, we develop an ensemble model that combines the strengths of sequential and tree-based approaches. Experimental results show that the proposed framework improves accuracy by 10 to 15 percent compared to individual models and reduces error during market changes. This study highlights the potential of ensemble methods for financial forecasting and provides a flexible design for integrating new machine learning techniques.
Logits DeConfusion with CLIP for Few-Shot Learning
Apr 16, 2025



With its powerful visual-language alignment capability, CLIP performs well in zero-shot and few-shot learning tasks. However, we found in experiments that CLIP's logits suffer from serious inter-class confusion problems in downstream tasks, and the ambiguity between categories seriously affects the accuracy. To address this challenge, we propose a novel method called Logits DeConfusion, which effectively learns and eliminates inter-class confusion in logits by combining our Multi-level Adapter Fusion (MAF) module with our Inter-Class Deconfusion (ICD) module. Our MAF extracts features from different levels and fuses them uniformly to enhance feature representation. Our ICD learnably eliminates inter-class confusion in logits with a residual structure. Experimental results show that our method can significantly improve the classification performance and alleviate the inter-class confusion problem. The code is available at https://github.com/LiShuo1001/LDC.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025



This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
MASSeg : 2nd Technical Report for 4th PVUW MOSE Track
Apr 14, 2025Complex video object segmentation continues to face significant challenges in small object recognition, occlusion handling, and dynamic scene modeling. This report presents our solution, which ranked second in the MOSE track of CVPR 2025 PVUW Challenge. Based on an existing segmentation framework, we propose an improved model named MASSeg for complex video object segmentation, and construct an enhanced dataset, MOSE+, which includes typical scenarios with occlusions, cluttered backgrounds, and small target instances. During training, we incorporate a combination of inter-frame consistent and inconsistent data augmentation strategies to improve robustness and generalization. During inference, we design a mask output scaling strategy to better adapt to varying object sizes and occlusion levels. As a result, MASSeg achieves a J score of 0.8250, F score of 0.9007, and a J&F score of 0.8628 on the MOSE test set.
RAG-Adapter: A Plug-and-Play RAG-enhanced Framework for Long Video Understanding
Mar 11, 2025Multi-modal Large Language Models (MLLMs) capable of video understanding are advancing rapidly. To effectively assess their video comprehension capabilities, long video understanding benchmarks, such as Video-MME and MLVU, are proposed. However, these benchmarks directly use uniform frame sampling for testing, which results in significant information loss and affects the accuracy of the evaluations in reflecting the true abilities of MLLMs. To address this, we propose RAG-Adapter, a plug-and-play framework that reduces information loss during testing by sampling frames most relevant to the given question. Additionally, we introduce a Grouped-supervised Contrastive Learning (GCL) method to further enhance sampling effectiveness of RAG-Adapter through fine-tuning on our constructed MMAT dataset. Finally, we test numerous baseline MLLMs on various video understanding benchmarks, finding that RAG-Adapter sampling consistently outperforms uniform sampling (e.g., Accuracy of GPT-4o increases by 9.3 percent on Video-MME), providing a more accurate testing method for long video benchmarks.
ALLVB: All-in-One Long Video Understanding Benchmark
Mar 10, 2025



From image to video understanding, the capabilities of Multi-modal LLMs (MLLMs) are increasingly powerful. However, most existing video understanding benchmarks are relatively short, which makes them inadequate for effectively evaluating the long-sequence modeling capabilities of MLLMs. This highlights the urgent need for a comprehensive and integrated long video understanding benchmark to assess the ability of MLLMs thoroughly. To this end, we propose ALLVB (ALL-in-One Long Video Understanding Benchmark). ALLVB's main contributions include: 1) It integrates 9 major video understanding tasks. These tasks are converted into video QA formats, allowing a single benchmark to evaluate 9 different video understanding capabilities of MLLMs, highlighting the versatility, comprehensiveness, and challenging nature of ALLVB. 2) A fully automated annotation pipeline using GPT-4o is designed, requiring only human quality control, which facilitates the maintenance and expansion of the benchmark. 3) It contains 1,376 videos across 16 categories, averaging nearly 2 hours each, with a total of 252k QAs. To the best of our knowledge, it is the largest long video understanding benchmark in terms of the number of videos, average duration, and number of QAs. We have tested various mainstream MLLMs on ALLVB, and the results indicate that even the most advanced commercial models have significant room for improvement. This reflects the benchmark's challenging nature and demonstrates the substantial potential for development in long video understanding.
CodeSwift: Accelerating LLM Inference for Efficient Code Generation
Feb 24, 2025



Code generation is a latency-sensitive task that demands high timeliness, but the autoregressive decoding mechanism of Large Language Models (LLMs) leads to poor inference efficiency. Existing LLM inference acceleration methods mainly focus on standalone functions using only built-in components. Moreover, they treat code like natural language sequences, ignoring its unique syntax and semantic characteristics. As a result, the effectiveness of these approaches in code generation tasks remains limited and fails to align with real-world programming scenarios. To alleviate this issue, we propose CodeSwift, a simple yet highly efficient inference acceleration approach specifically designed for code generation, without comprising the quality of the output. CodeSwift constructs a multi-source datastore, providing access to both general and project-specific knowledge, facilitating the retrieval of high-quality draft sequences. Moreover, CodeSwift reduces retrieval cost by controlling retrieval timing, and enhances efficiency through parallel retrieval and a context- and LLM preference-aware cache. Experimental results show that CodeSwift can reach up to 2.53x and 2.54x speedup compared to autoregressive decoding in repository-level and standalone code generation tasks, respectively, outperforming state-of-the-art inference acceleration approaches by up to 88%.
Preference Optimization via Contrastive Divergence: Your Reward Model is Secretly an NLL Estimator
Feb 06, 2025



Existing studies on preference optimization (PO) have centered on constructing pairwise preference data following simple heuristics, such as maximizing the margin between preferred and dispreferred completions based on human (or AI) ranked scores. However, none of these heuristics has a full theoretical justification. In this work, we develop a novel PO framework that provides theoretical guidance to effectively sample dispreferred completions. To achieve this, we formulate PO as minimizing the negative log-likelihood (NLL) of a probability model and propose to estimate its normalization constant via a sampling strategy. As we will demonstrate, these estimative samples can act as dispreferred completions in PO. We then select contrastive divergence (CD) as the sampling strategy, and propose a novel MC-PO algorithm that applies the Monte Carlo (MC) kernel from CD to sample hard negatives w.r.t. the parameterized reward model. Finally, we propose the OnMC-PO algorithm, an extension of MC-PO to the online setting. On popular alignment benchmarks, MC-PO outperforms existing SOTA baselines, and OnMC-PO leads to further improvement.
Domain-conditioned and Temporal-guided Diffusion Modeling for Accelerated Dynamic MRI Reconstruction
Jan 16, 2025



Purpose: To propose a domain-conditioned and temporal-guided diffusion modeling method, termed dynamic Diffusion Modeling (dDiMo), for accelerated dynamic MRI reconstruction, enabling diffusion process to characterize spatiotemporal information for time-resolved multi-coil Cartesian and non-Cartesian data. Methods: The dDiMo framework integrates temporal information from time-resolved dimensions, allowing for the concurrent capture of intra-frame spatial features and inter-frame temporal dynamics in diffusion modeling. It employs additional spatiotemporal ($x$-$t$) and self-consistent frequency-temporal ($k$-$t$) priors to guide the diffusion process. This approach ensures precise temporal alignment and enhances the recovery of fine image details. To facilitate a smooth diffusion process, the nonlinear conjugate gradient algorithm is utilized during the reverse diffusion steps. The proposed model was tested on two types of MRI data: Cartesian-acquired multi-coil cardiac MRI and Golden-Angle-Radial-acquired multi-coil free-breathing lung MRI, across various undersampling rates. Results: dDiMo achieved high-quality reconstructions at various acceleration factors, demonstrating improved temporal alignment and structural recovery compared to other competitive reconstruction methods, both qualitatively and quantitatively. This proposed diffusion framework exhibited robust performance in handling both Cartesian and non-Cartesian acquisitions, effectively reconstructing dynamic datasets in cardiac and lung MRI under different imaging conditions. Conclusion: This study introduces a novel diffusion modeling method for dynamic MRI reconstruction.
Few-Shot Adaptation of Training-Free Foundation Model for 3D Medical Image Segmentation
Jan 15, 2025



Vision foundation models have achieved remarkable progress across various image analysis tasks. In the image segmentation task, foundation models like the Segment Anything Model (SAM) enable generalizable zero-shot segmentation through user-provided prompts. However, SAM primarily trained on natural images, lacks the domain-specific expertise of medical imaging. This limitation poses challenges when applying SAM to medical image segmentation, including the need for extensive fine-tuning on specialized medical datasets and a dependency on manual prompts, which are both labor-intensive and require intervention from medical experts. This work introduces the Few-shot Adaptation of Training-frEe SAM (FATE-SAM), a novel method designed to adapt the advanced Segment Anything Model 2 (SAM2) for 3D medical image segmentation. FATE-SAM reassembles pre-trained modules of SAM2 to enable few-shot adaptation, leveraging a small number of support examples to capture anatomical knowledge and perform prompt-free segmentation, without requiring model fine-tuning. To handle the volumetric nature of medical images, we incorporate a Volumetric Consistency mechanism that enhances spatial coherence across 3D slices. We evaluate FATE-SAM on multiple medical imaging datasets and compare it with supervised learning methods, zero-shot SAM approaches, and fine-tuned medical SAM methods. Results show that FATE-SAM delivers robust and accurate segmentation while eliminating the need for large annotated datasets and expert intervention. FATE-SAM provides a practical, efficient solution for medical image segmentation, making it more accessible for clinical applications.