 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-MSTNet: sim2real based Multi-task SpatioTemporal Network Traffic Forecasting
Jan 29, 2026Network traffic forecasting plays a crucial role in intelligent network operations, but existing techniques often perform poorly when faced with limited data. Additionally, multi-task learning methods struggle with task imbalance and negative transfer, especially when modeling various service types. To overcome these challenges, we propose Sim-MSTNet, a multi-task spatiotemporal network traffic forecasting model based on the sim2real approach. Our method leverages a simulator to generate synthetic data, effectively addressing the issue of poor generalization caused by data scarcity. By employing a domain randomization technique, we reduce the distributional gap between synthetic and real data through bi-level optimization of both sample weighting and model training. Moreover, Sim-MSTNet incorporates attention-based mechanisms to selectively share knowledge between tasks and applies dynamic loss weighting to balance task objectives. Extensive experiments on two open-source datasets show that Sim-MSTNet consistently outperforms state-of-the-art baselines, achieving enhanced accuracy and generalization.
Learning Longitudinal Health Representations from EHR and Wearable Data
Jan 18, 2026Foundation models trained on electronic health records show strong performance on many clinical prediction tasks but are limited by sparse and irregular documentation. Wearable devices provide dense continuous physiological signals but lack semantic grounding. Existing methods usually model these data sources separately or combine them through late fusion. We propose a multimodal foundation model that jointly represents electronic health records and wearable data as a continuous time latent process. The model uses modality specific encoders and a shared temporal backbone pretrained with self supervised and cross modal objectives. This design produces representations that are temporally coherent and clinically grounded. Across forecasting physiological and risk modeling tasks the model outperforms strong electronic health record only and wearable only baselines especially at long horizons and under missing data. These results show that joint electronic health record and wearable pretraining yields more faithful representations of longitudinal health.
Noisy MRI Reconstruction via MAP Estimation with an Implicit Deep-Denoiser Prior
Nov 15, 2025Accelerating magnetic resonance imaging (MRI) remains challenging, particularly under realistic acquisition noise. While diffusion models have recently shown promise for reconstructing undersampled MRI data, many approaches lack an explicit link to the underlying MRI physics, and their parameters are sensitive to measurement noise, limiting their reliability in practice. We introduce Implicit-MAP (ImMAP), a diffusion-based reconstruction framework that integrates the acquisition noise model directly into a maximum a posteriori (MAP) formulation. Specifically, we build on the stochastic ascent method of Kadkhodaie et al. and generalize it to handle MRI encoding operators and realistic measurement noise. Across both simulated and real noisy datasets, ImMAP consistently outperforms state-of-the-art deep learning (LPDSNet) and diffusion-based (DDS) methods. By clarifying the practical behavior and limitations of diffusion models under realistic noise conditions, ImMAP establishes a more reliable and interpretable
Hierarchical Schedule Optimization for Fast and Robust Diffusion Model Sampling
Nov 12, 2025



Diffusion probabilistic models have set a new standard for generative fidelity but are hindered by a slow iterative sampling process. A powerful training-free strategy to accelerate this process is Schedule Optimization, which aims to find an optimal distribution of timesteps for a fixed and small Number of Function Evaluations (NFE) to maximize sample quality. To this end, a successful schedule optimization method must adhere to four core principles: effectiveness, adaptivity, practical robustness, and computational efficiency. However, existing paradigms struggle to satisfy these principles simultaneously, motivating the need for a more advanced solution. To overcome these limitations, we propose the Hierarchical-Schedule-Optimizer (HSO), a novel and efficient bi-level optimization framework. HSO reframes the search for a globally optimal schedule into a more tractable problem by iteratively alternating between two synergistic levels: an upper-level global search for an optimal initialization strategy and a lower-level local optimization for schedule refinement. This process is guided by two key innovations: the Midpoint Error Proxy (MEP), a solver-agnostic and numerically stable objective for effective local optimization, and the Spacing-Penalized Fitness (SPF) function, which ensures practical robustness by penalizing pathologically close timesteps. Extensive experiments show that HSO sets a new state-of-the-art for training-free sampling in the extremely low-NFE regime. For instance, with an NFE of just 5, HSO achieves a remarkable FID of 11.94 on LAION-Aesthetics with Stable Diffusion v2.1. Crucially, this level of performance is attained not through costly retraining, but with a one-time optimization cost of less than 8 seconds, presenting a highly practical and efficient paradigm for diffusion model acceleration.
Hybrid Learning: A Novel Combination of Self-Supervised and Supervised Learning for MRI Reconstruction without High-Quality Training Reference
May 09, 2025Purpose: Deep learning has demonstrated strong potential for MRI reconstruction, but conventional supervised learning methods require high-quality reference images, which are often unavailable in practice. Self-supervised learning offers an alternative, yet its performance degrades at high acceleration rates. To overcome these limitations, we propose hybrid learning, a novel two-stage training framework that combines self-supervised and supervised learning for robust image reconstruction. Methods: Hybrid learning is implemented in two sequential stages. In the first stage, self-supervised learning is employed to generate improved images from noisy or undersampled reference data. These enhanced images then serve as pseudo-ground truths for the second stage, which uses supervised learning to refine reconstruction performance and support higher acceleration rates. We evaluated hybrid learning in two representative applications: (1) accelerated 0.55T spiral-UTE lung MRI using noisy reference data, and (2) 3D T1 mapping of the brain without access to fully sampled ground truth. Results: For spiral-UTE lung MRI, hybrid learning consistently improved image quality over both self-supervised and conventional supervised methods across different acceleration rates, as measured by SSIM and NMSE. For 3D T1 mapping, hybrid learning achieved superior T1 quantification accuracy across a wide dynamic range, outperforming self-supervised learning in all tested conditions. Conclusions: Hybrid learning provides a practical and effective solution for training deep MRI reconstruction networks when only low-quality or incomplete reference data are available. It enables improved image quality and accurate quantitative mapping across different applications and field strengths, representing a promising technique toward broader clinical deployment of deep learning-based MRI.
Self-Supervised Noise Adaptive MRI Denoising via Repetition to Repetition (Rep2Rep) Learning
Apr 24, 2025Purpose: This work proposes a novel self-supervised noise-adaptive image denoising framework, called Repetition to Repetition (Rep2Rep) learning, for low-field (<1T) MRI applications. Methods: Rep2Rep learning extends the Noise2Noise framework by training a neural network on two repeated MRI acquisitions, using one repetition as input and another as target, without requiring ground-truth data. It incorporates noise-adaptive training, enabling denoising generalization across varying noise levels and flexible inference with any number of repetitions. Performance was evaluated on both synthetic noisy brain MRI and 0.55T prostate MRI data, and compared against supervised learning and Monte Carlo Stein's Unbiased Risk Estimator (MC-SURE). Results: Rep2Rep learning outperforms MC-SURE on both synthetic and 0.55T MRI datasets. On synthetic brain data, it achieved denoising quality comparable to supervised learning and surpassed MC-SURE, particularly in preserving structural details and reducing residual noise. On the 0.55T prostate MRI dataset, a reader study showed radiologists preferred Rep2Rep-denoised 2-average images over 8-average noisy images. Rep2Rep demonstrated robustness to noise-level discrepancies between training and inference, supporting its practical implementation. Conclusion: Rep2Rep learning offers an effective self-supervised denoising for low-field MRI by leveraging routinely acquired multi-repetition data. Its noise-adaptivity enables generalization to different SNR regimes without clean reference images. This makes Rep2Rep learning a promising tool for improving image quality and scan efficiency in low-field MRI.
Learned Primal Dual Splitting for Self-Supervised Noise-Adaptive MRI Reconstruction
Apr 21, 2025Magnetic resonance imaging (MRI) reconstruction has largely been dominated by deep neural networks (DNN); however, many state-of-the-art architectures use black-box structures, which hinder interpretability and improvement. Here, we propose an interpretable DNN architecture for self-supervised MRI reconstruction and denoising by directly parameterizing and learning the classical primal-dual splitting, dubbed LPDSNet. This splitting algorithm allows us to decouple the observation model from the signal prior. Experimentally, we show other interpretable architectures without this decoupling property exhibit failure in the self-supervised learning regime. We report state-of-the-art self-supervised joint MRI reconstruction and denoising performance and novel noise-level generalization capabilities, where in contrast black-box networks fail to generalize.
HQViT: Hybrid Quantum Vision Transformer for Image Classification
Apr 03, 2025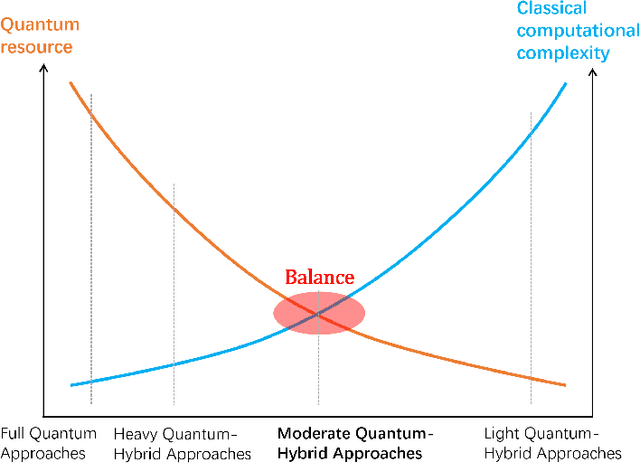
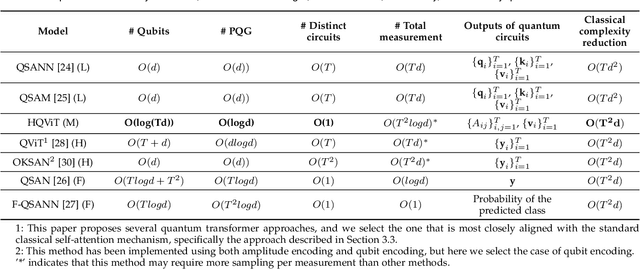
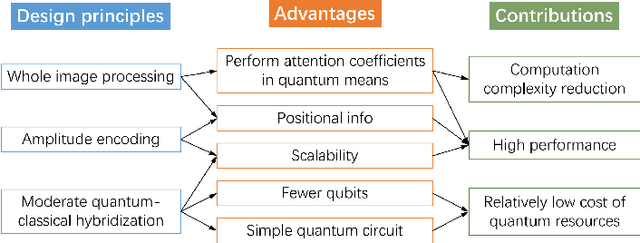
Transformer-based architectures have revolutionized the landscape of deep learning. In computer vision domain, Vision Transformer demonstrates remarkable performance on par with or even surpassing that of convolutional neural networks. However, the quadratic computational complexity of its self-attention mechanism poses challenges for classical computing, making model training with high-dimensional input data, e.g., images, particularly expensive. To address such limitations, we propose a Hybrid Quantum Vision Transformer (HQViT), that leverages the principles of quantum computing to accelerate model training while enhancing model performance. HQViT introduces whole-image processing with amplitude encoding to better preserve global image information without additional positional encoding. By leveraging quantum computation on the most critical steps and selectively handling other components in a classical way, we lower the cost of quantum resources for HQViT. The qubit requirement is minimized to $O(log_2N)$ and the number of parameterized quantum gates is only $O(log_2d)$, making it well-suited for Noisy Intermediate-Scale Quantum devices. By offloading the computationally intensive attention coefficient matrix calculation to the quantum framework, HQViT reduces the classical computational load by $O(T^2d)$. Extensive experiments across various computer vision datasets demonstrate that HQViT outperforms existing models, achieving a maximum improvement of up to $10.9\%$ (on the MNIST 10-classification task) over the state of the art. This work highlights the great potential to combine quantum and classical computing to cope with complex image classification tasks.
Quantum Complex-Valued Self-Attention Model
Mar 24, 2025



The self-attention mechanism has revolutionized classical machine learning, yet its quantum counterpart remains underexplored in fully harnessing the representational power of quantum states. Current quantum self-attention models exhibit a critical limitation by neglecting the indispensable phase information inherent in quantum systems when compressing attention weights into real-valued overlaps. To address this fundamental gap, we propose the Quantum Complex-Valued Self-Attention Model (QCSAM), the first framework that explicitly leverages complex-valued similarities between quantum states to capture both amplitude and phase relationships. Simultaneously, we enhance the standard Linear Combination of Unitaries (LCUs) method by introducing a Complex LCUs (CLCUs) framework that natively supports complex-valued coefficients. This framework enables the weighting of corresponding quantum values using fixed quantum complex self-attention weights, while also supporting trainable complex-valued parameters for value aggregation and quantum multi-head attention. Experimental evaluations on MNIST and Fashion-MNIST demonstrate our model's superiority over recent quantum self-attention architectures including QKSAN, QSAN, and GQHAN, with multi-head configurations showing consistent advantages over single-head variants. We systematically evaluate model scalability through qubit configurations ranging from 3 to 8 qubits and multi-class classification tasks spanning 2 to 4 categories. Through comprehensive ablation studies, we establish the critical advantage of complex-valued quantum attention weights over real-valued alternatives.
Domain-conditioned and Temporal-guided Diffusion Modeling for Accelerated Dynamic MRI Reconstruction
Jan 16, 2025



Purpose: To propose a domain-conditioned and temporal-guided diffusion modeling method, termed dynamic Diffusion Modeling (dDiMo), for accelerated dynamic MRI reconstruction, enabling diffusion process to characterize spatiotemporal information for time-resolved multi-coil Cartesian and non-Cartesian data. Methods: The dDiMo framework integrates temporal information from time-resolved dimensions, allowing for the concurrent capture of intra-frame spatial features and inter-frame temporal dynamics in diffusion modeling. It employs additional spatiotemporal ($x$-$t$) and self-consistent frequency-temporal ($k$-$t$) priors to guide the diffusion process. This approach ensures precise temporal alignment and enhances the recovery of fine image details. To facilitate a smooth diffusion process, the nonlinear conjugate gradient algorithm is utilized during the reverse diffusion steps. The proposed model was tested on two types of MRI data: Cartesian-acquired multi-coil cardiac MRI and Golden-Angle-Radial-acquired multi-coil free-breathing lung MRI, across various undersampling rates. Results: dDiMo achieved high-quality reconstructions at various acceleration factors, demonstrating improved temporal alignment and structural recovery compared to other competitive reconstruction methods, both qualitatively and quantitatively. This proposed diffusion framework exhibited robust performance in handling both Cartesian and non-Cartesian acquisitions, effectively reconstructing dynamic datasets in cardiac and lung MRI under different imaging conditions. Conclusion: This study introduces a novel diffusion modeling method for dynamic MRI reconstruction.